






2020,努力做一个无可替代的人!
作者|小一

全文共2018字,阅读全文需7分钟
写在前面的话
拖了好久的爬虫框架,终于有空来写一写了
在Numpy 和Pandas 系列之前我们是在写爬虫相关,也做了两个小项目爬了一些数据。
如果你忘了,建议你花三五分钟回顾一下
通过前面六节我们对于主流网站的数据基本都可以获取到,对于网页内容也都可以解析。
比如说,现在要爬取某个电子书网站的小说,相信你也是可以做到的。
可能有难点的是搞定网站的反爬,比如:需要验证码、隔一段时间ip会被禁用等等
不过,小一应该不会带你们研究这个,至少短期内不会,原因在刚开始说爬虫的时候就提到,就不重复了。
再来说爬虫框架,为什么还会有爬虫框架这个东西呢?
你可以这样理解,在日常工作中你需要每天出一份报表,报表内容也很简单,就是更新一下昨天的一些指标数据。
这个时候,会Python 的你是不是想到了自动化?
在自动化之前,是不是应该准备好一份模板,然后每天更新数据即可。
同样的道理,当你的爬虫已经规范化,不再纠结于细节,你就该了解一下爬虫框架了
正文
你可能要问,不要爬虫框架行不行?
小一明确的表示,完全可以。
在造轮子和用轮子之间,你可以任意选择。
就像前面的例子一样,如果你只是在某一段时间需要每天出报表,每天花上几分钟就搞定,那你完全可以不用去考虑自动化
相反,如果你可能连续好几个月都要出报表,而且每天要花好几个小时才能搞定
这个时候,自动化它不香嘛?
建议根据自身的实际情况去考虑
好了,开始正题
爬虫框架小一用过的就两个,PySpider 和Scrapy。
说实话,在爬虫框架这方面小一没好好做功课,如果有比这两个更好用的,欢迎评论区留言。
首先来看PySpider
PySpider
PySpider 的主要功能是:
PySpider 提供 了 WebUI,爬虫的编写、调试都是在WebUI 中进行的
PySpider 调试非常方便 , WebUI 操作便捷直观
PySpider 支持 PhantomJS 来进行动态页面的采集
PySpider 中内置了Pyquery 作为选择器
提取一下上面四点的关键词:WebUI、调试、动态采集、Pyquery
在前面介绍selenium 的时候,我们用到一个词叫 可见即可爬。
意思就是说我们在浏览器中能看到的,它都可以为我们爬下来
PySpider 就更过分了,它直接让你看到每一步都有什么内容,你操作了之后会变成什么
这就相当于你的每一步操作你都能看到,不需要你再通过F12 调用浏览器网页源码对比去找了。
然后你到底哪一块代码没对应上写错了,都可以通过可视化界面看到
有没有感受到它的方便?我贴一张图
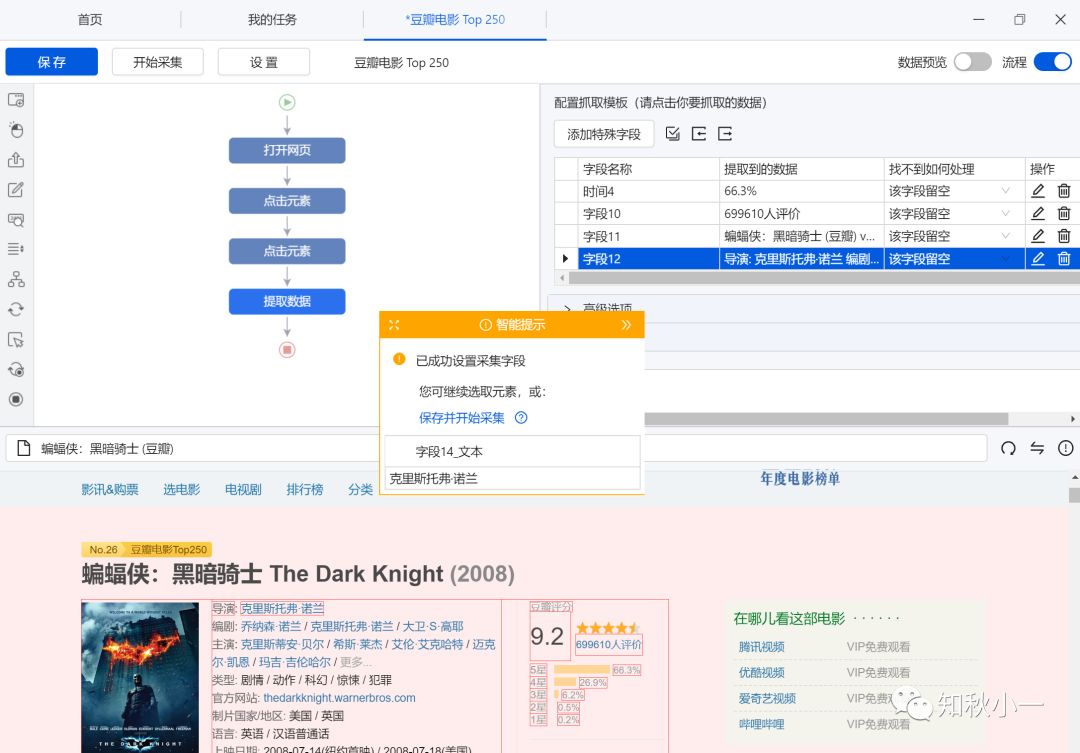
这个,当然不是PySpider 的界面
这是八爪鱼设置爬虫流程的界面,上半部分左边是爬虫流程,右边是获取的内容字段,下半部分是网页内容,中间的框是负责流程采集的
虽说PySpider 没有这个图这么智能化(八爪鱼是全智能采集工具,个别功能需要付费),但是大体流程基本都一样
再来看另一个爬虫框架Scrapy
Scrapy
Scrapy 的主要功能是:
Scrapy 采用的代码和命令行操作,但可以通过对接Portia 实现可视化配置(需要额外配置)
Scrapy 使用 parse命令进行调试
Scrapy 不主动支持动态页面采集,需要对接Scrapy-Splash组件(需要额外配置)
Scrapy 对接了 XPath、 css选择器和正则匹配
Scrapy 可以通过对接 Middleware、Pipeline、Extension等组件实现功能, 模块之间可扩展程度极高
提取一下Scarpy的关键词:命令行、parse调试、Xpath&css、扩展性高
想起比PySpider,Scrapy 就完全是一个黑乎乎的框架的,这个框架需要你自己去完善。
它的每一个模块的功能都封装起来,各司其职说的就是它
放一张Scrapy 的结构图
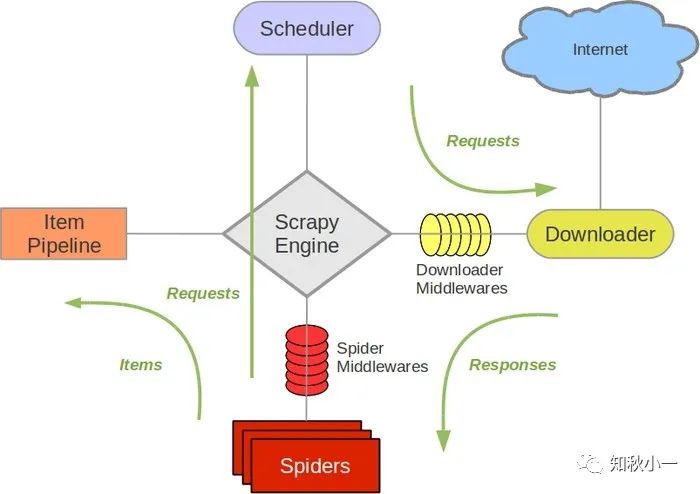
稍微解释一下各个部分:
Engine,引擎,用来处理整个系统的数据流处理,触发事务,是整个框架的核心。
Item,项目,它定义了爬取结果的数据结构,爬取的数据会被赋值成该对象。
Scheduler, 调度器,用来接受引擎发过来的请求并加入队列中,并在引擎再次请求的时候提供给引擎。
Downloader,下载器,用于下载网页内容,并将网页内容返回给蜘蛛。
Spiders,蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成提取结果和新的请求。
Item Pipeline,项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
Downloader Middlewares,下载器中间件,位于引擎和下载器之间的框架,主要是处理引擎与下载器之间的请求及响应。
Spider Middlewares, 蜘蛛中间件,位于引擎和蜘蛛之间的框架,主要工作是处理蜘蛛输入的响应和输出的结果及新的请求。
这两个框架的侧重点差别还是挺大的,PySpider 可以看到爬虫界面,交互性好;Scrapy 组件功能强大,各个模块各司其职,扩展性强
总结一下:
今天大致介绍了PySpider 和Scrapy 两个爬虫框架各自的特点
具体在实际过程中你需要用到哪个框架,根据你自己的侧重点决定
但也不是说框架就一定好用,还是需要结合实际工作需求
下节,会开始介绍框架的具体用法,下节见!
写在后面的话
还记得之前我们爬过链家的租房数据吗?
当时说过会用这部分数据做一期分析的实战,有没有好的想法和建议呢?
欢迎在评论区留言噢
碎碎念一下
爬虫系列大概会在这个月底结束,到此数据分析的基础内容除了可视化就都涉及到了,不知道你们学会了多少?
后面的分析和算法部分小一也在学习中,大家一起加油
好巧啊,你也读到这了!
点个在看让小一看到你















 2417
2417











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









