







在众多的股票量化策略里,我比较钟爱一个策略:净利润断层
直观理解就是在股票的业绩预告、业绩快报、业绩报告等报告出来的时候,因为业绩超预期,股价会有一个跳空高开形成缺口,而且因为上攻力量比较强,这个缺口短期不会回补
而且股价会随着上攻力量越来越高,形成一个净利润断层
关于这个策略的验证今天不多说,改天会专门讲,我个人觉得断层上攻的准确率很高
但是由于业绩预告、业绩快报、业绩报告这些数据一般都需要付费,很少有免费接口
所以,今天就来教一下大家如何用Python免费获取股票的业绩预告数据。
ok,先给一个使用说明,源码和逻辑见后文
1、核心代码
首先是需要自定义一些参数,分别是:
业绩预告的年份、季度,以及需要获取的报告日期,格式是年-月-日
# 需要手动设置,对应的 report_quarter 即为每个季度的数据
report_year, report_quarter = '2022', '4'
# 截止当前日期
notice_day = '2022-10-29'其次是通过一个函数循环获取获取每一个页面中的所有报告
为了更方便跳出循环,一旦报告日期小于设定的日期,会结束爬取,这个在后面的代码中会介绍到
# 爬取数据
df_stock_info = get_main_info(report_year, report_quarter, notice_day)最后是将爬取的业绩预报数据存到本地文件中:
# 导出成本地csv
df_stock_info.to_csv(save_filepath, index=False, encoding='gbk')
print('======>> 处理完成,已导出本地:{0}'.format(save_filepath))程序运行图如下:
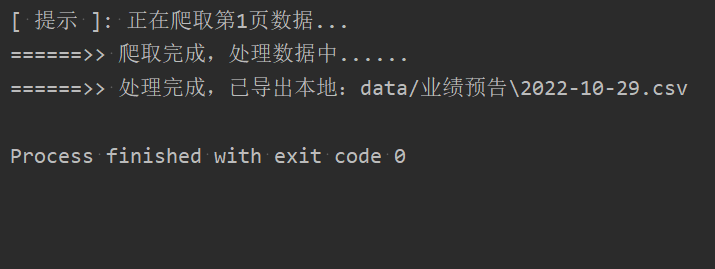
最终爬取的报告结果如下:
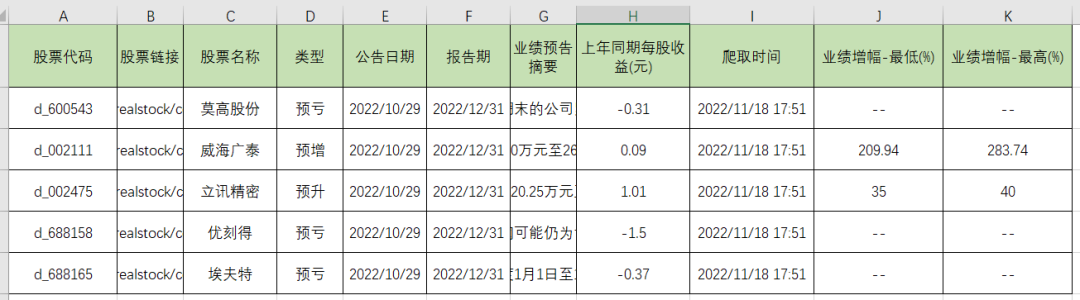
10月27号共有5条公布业绩预告的股票
2、爬虫思路
获取源码文件请直接在原文链接中回复 业绩预报
原文链接👉:Python批量免费获取股票业绩预告
后续会有一些股票的量化策略分享,而数据正是来自于今天的这篇文章,所以今天的源代码和数据肯定是不会一直公开的,目前仅针对公众号粉丝开放,先到先得吧,后面大概率会收费。
这里我是从新浪财经上爬取的,选择它是因为它有很多有意思的数据,可以用来做辅助验证量化策略,所以后续的很多数据大概率也会是从这拿了
先打开新浪财经的页面,切到业绩预告这一栏
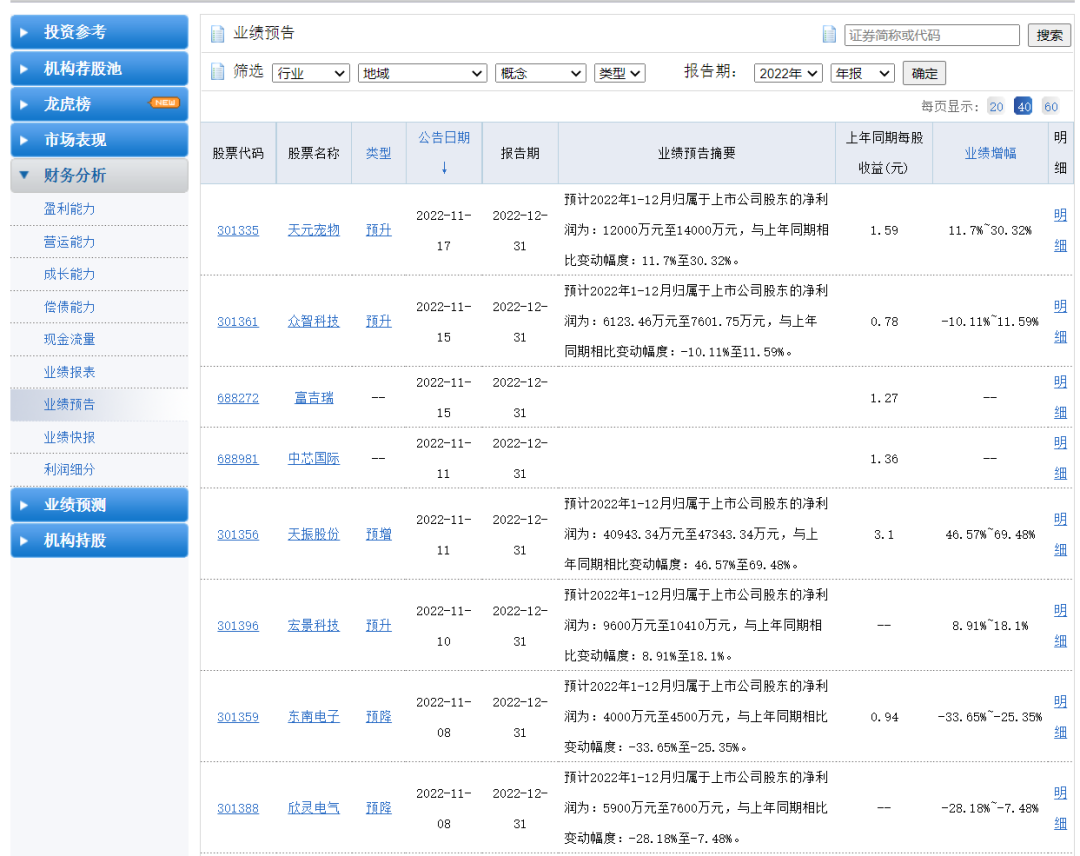
可以看到,上面有我们需要的股票名称、业绩类型、公告日期、报告日期、业绩增幅等数据
浏览器打开 F12,定位到对应的源码上
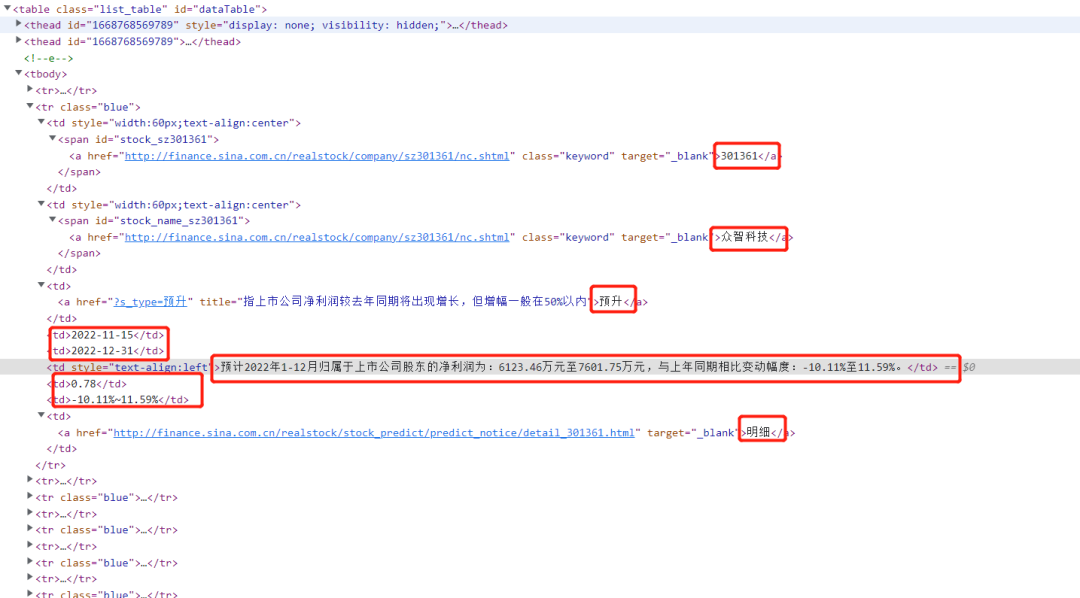
数据一览无遗,正是我们需要的
最后在切换页面的时候,可以看到网址栏的URL发生了变化,观察它的规律,我们可以根据自己的需求构造想要访问的页面
最后,在点击右上角条件筛选的时候可以发现,URL同样发生了变化,对应的我们可以将参数放在URL里面一起构造
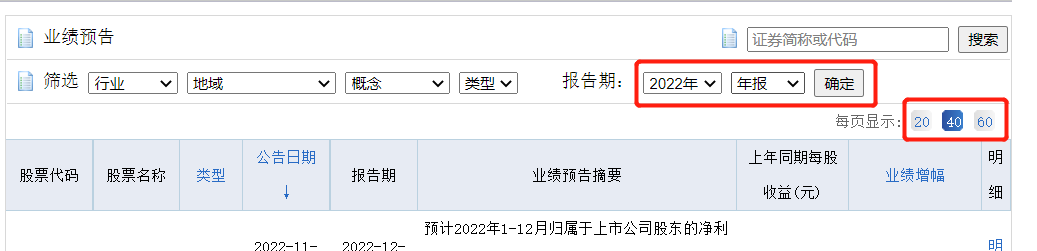
对应的参数如下:
-
reportdate:报告年份
-
quarter:报告季度,分为1/2/3/4
-
p:页面下标,默认从1开始
-
num:显示每页的数据个数,默认是40
-
order:排序方式,默认是公告日期排序,可以选择类型排序,参数是type|2;排序默认是降序,如果想升序就把 2 改成 1
最后循环遍历构造的每个页面,并把页面数据爬取下来就可以了。
获取目标日期的业绩预报的核心代码如下:
if not continue_flag:
break
print('[ 提示 ]: 正在爬取第{0}页数据...'.format(page_index))
page_url = 'http://vip.stock.finance.sina.com.cn/q/go.php/vFinanceAnalyze/kind/performance/index.phtml?s_i=&s_a=&s_c=&reportdate={0}&quarter={1}&p={2}'.format(report_year, report_quarter, page_index)
# 爬取当前页码的数据
response = requests.get(url=page_url, headers={'User-Agent': get_ua()})
report_page, continue_flag = parse_content(response, notice_day)
report_data.extend(report_page)然后是详细的解析每一页内容,因为前面是设置了无限循环,所以这一步需要判断一下
当当前页面的公告日期小于目标日期,就会停止,核心代码如下:
# 如果当前日期小于所需的报告日期,则退出
if report_per[4] < notice_day:
continue_flag = False
break
elif report_per[4] == notice_day:
report_page.append(report_per)以上是核心源码,这里省去了非核心部分,需要请查看源码文件。
获取源码文件请直接在原文链接中回复 业绩预报
原文链接👉:Python批量免费获取股票业绩预告
后续会有一些股票的量化策略分享,而数据正是来自于今天的这篇文章,所以今天的源代码肯定是不会一直公开的,目前仅针对公众号粉丝开放,先到先得吧,后面大概率就不开放了。
原创不易,希望大家在看完文章的同时,记得一键三连

















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









