







最近要用sql了,丢了一年多了,才发现好多基础的东西都忘了,要死!赶紧记录加强记忆。
1.if 后面的判断条件是boolean型的,如果是值判断要用exists()
IF EXISTS(SELECT 1 FROM dbo.tbl WHERE dDate='2020-07-01')
BEGIN
BREAK
END
ELSE
BEGIN
break
end
2.proc中 create proc 要是第一行语句,最好前后加个GO,@a int是输入变量,declear @a int是内部变量,@a int outer是输出变量。
CREATE PROCEDURE [dbo].[P_Max]
@a int, -- 输入
@b int, -- 输入
@Returnc int output --输出
AS
if (@a>@b)
set @Returnc =@a
else
set @Returnc =@b
-- 调用
declare @Returnc int
exec P_Max 2,3,@Returnc output
select @Returnc
3.while 里面不加begin end 的话会死循环!
DECLARE @a INT,@b INT;
SET @a =1
SET @b=1
PRINT @a
WHILE @a <10
begin --去掉就死循环
SELECT @a
SELECT @b
SET @a+=1
SET @b+=1
END --去掉就死循环
4.创建自增字段
另外有个BIGINT数据类型2^63-1
SELECT IDENTITY(INT,1,1) AS fid ,* INTO temcopy FROM a
5break好像只能用在while里面,其他地方可以用return。
自增字段要编辑的话方法如下:
SET IDENTITY_INSERT TABLE_NAME ON;
INSERT INTO TABLE_NAME(XXX, XXX,…, XXX) SELECT XXX, XXX,…, XXX FROM TABLE_NAME_BAK;
注意: 即使是所有列,这里的字段名也不能省略.
SET IDENTITY_INSERT TABLE_NAME OFF;
6左/右去空格 ltrim()/rtrim()。如果是中间去空格用replace(好像没有trim()),另外空格生成一个空格可以用space(1)
SELECT REPLACE(('ni'+'hao'+str(5)),SPACE(1),'')
7 for xml path 的用途:
引:https://www.cnblogs.com/wangjingblogs/archive/2012/05/16/2504325.html
1.变成xml格式
select * from a for xml path
2.xml行节点名变更
select * from a for xml path(‘行节点名’)
3.屏蔽行列名,只显示结果
SELECT ‘[ ‘+hName+’ ]’ FROM @hobby FOR XML PATH(‘’)
这里的path(‘’)应该就是设置行节点为空
3.筛选及多列合并字段
--备注订单号,订单号按','隔开
--stuff的作用是去除第一逗号,如果用substring或者left或者right则需要再嵌套一层select进行筛选
select 单据日期, 销售订单号 = (stuff((select distinct ',' + 销售订单号 from #tempfin where 单据日期 =
a.单据日期 for xml path('')),1,1,''))
INTO #temporder
from #tempfin a group by 单据日期
8修改一个表中一列为自增列。
直接改可能不行,这时会有2种方案。
一种是先删除id列,再新建一个id自增列。
alter table 表名 drop column ID
alter table 表名 add ID int identity(1,1)
一种是通过ssms修改

如果保存时报错把以下选择项去掉就行。
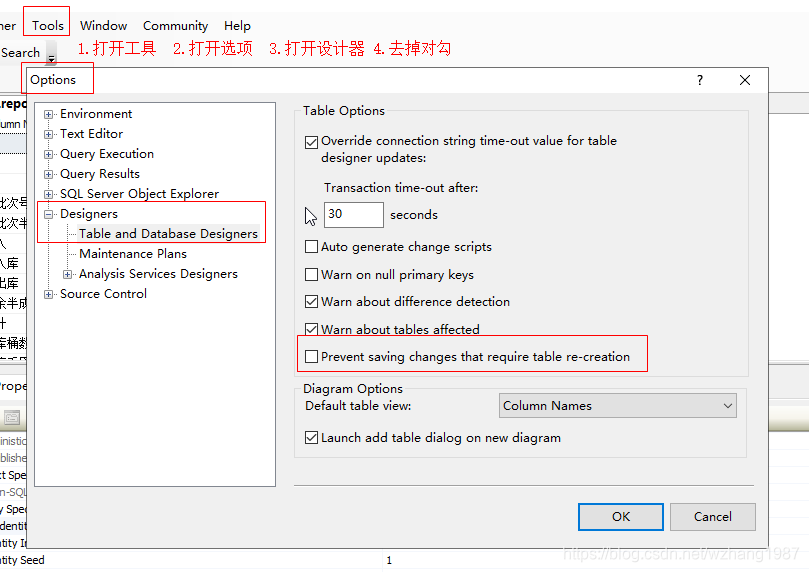
9 将截断字符串或二进制数据。
出现这个提示是说你update的字段长度过短,而更新的内容过长,一般直接修改set前的字段长度,或者用’000000000000000’ as 字段,这种形式也可以。
SELECT 发货单号,'0000000000000'AS a ,'0000000000000'AS b,
'00000000000000000'AS date1,'000000000000000'AS date2
INTO #temptime3
FROM #temptime2
10proc里面在插入临时表数据时select * into from 可能sum() group by 不会生效,可以退而求其次,分两步走,先select * into from 然后再新建一个临时表 select * into from 再sum() group by
11游标
转:https://www.cnblogs.com/qqhfeng/p/5348439.html
12分类汇总
注意grouping和with rollup 的组合
SELECT case when grouping([月份])=1 then '合计' else [月份] end as [月份]
,sum([采购入库])
,sum([其他入库])
,sum([销售出库])
,sum([其他出库])
FROM [report].[dbo].[finance_cheng_zhi6]
group by [月份]
with rollup
13时间处理
--本月1号
select dateadd(mm,DATEDIFF(mm,0,getdate()),0)
--本月最后一天
select dateadd(mm,DATEDIFF(mm,0,getdate())+1,-1)
--上个月1号
select dateadd(mm,DATEDIFF(mm,0,getdate())-1,0)
--上个月最后一天
select dateadd(mm,DATEDIFF(mm,0,getdate()),-1)
--下个月1号
select dateadd(mm,DATEDIFF(mm,0,getdate())+1,0)
--下个月最后一天
select dateadd(mm,DATEDIFF(mm,0,getdate())+2,-1)
14视图排序
报这个错:除非另外还指定了 TOP 或 FOR XML,否则,ORDER BY 子句在视图、内联函数、派生表、子查询和公用表表达式中无效。
用top percent 似乎是无效的,虽然不会报错但实际还是没排序。
需要用top 1000000。
15proc里变量使用问题
如在非表头位置使用变量,直接使用即可,如@i,如果要在表头或者截断部分插入变量则要用@sql的形式。
如 create table ‘生产报表’+@i+‘月’,要set @tablename= ‘生产报表’+@i+‘月’,然后set @sql=‘create table ‘+@tablename+’’ ,最后exec(@sql)
另外强调一个细节问题,在@sql里进行如日期这种转换,一定要把convert写在里面!!!!!!!在外部转是无效的。。。。
如 a.日期 between ‘+convert(date,@time)+’ and convert(date,‘’‘+@time+’‘’)
and 后面的写法才有效!!,between后面这种实际没有转!!
并且convert里面要加两个引号’’
并且convert里面要加两个引号’’
并且convert里面要加两个引号’’
重要事情说三遍!这两个坑搞了一下午。。。。
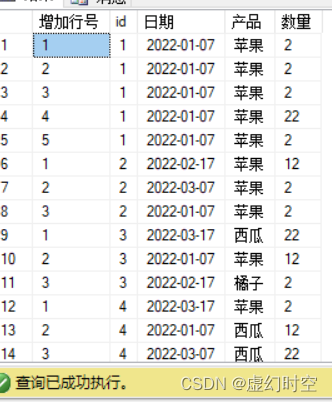
16 用于proc中临时表里面筛选排序的row_number(),需要和over()一起使用,用于增加行号和分区。
其中:PARTITION BY 用于分区,不填就一个区 ,ORDER BY 用于排序。
SELECT ROW_NUMBER()OVER(PARTITION BY id ORDER BY id) 增加行号,* FROM dbo.group1
17 关于以下几个概念:
主键:一个表只能有一个的唯一非空字段,自带唯一索引。
外键:a表(主表)建好主键后,b表(从表)字段(是不是主键都行)关联引用a表的主键创建的为外键。不带索引。外键主要控制b表增删。
主键和索引:主键肯定是索引,索引不一定是主键。
索引:创建在一个或多个字段上,就像书的目录一样有利于表的查询(如果正确使用)。注意创建原则,可以百度,一般是查的多的字段加索引,改的多的字段不加。
聚集(簇集)索引和非聚集(簇类)索引:聚集索引是物理上对应分配的单表唯一索引,非聚集索引是分配单元(存储数据的单元)外套娃的索引。举例就是:聚集索引数据1,2,3,4在物理存储单元时会按照1,2,3,4的顺序存储,非聚集索引数据1,2,3,4在物理上就可能是3,2,1,4,只在逻辑上连续物理存储时不连续,非聚集索引指向的可能是另一个索引而不是数据本身。
索引调优:一般索引碎片5%以下不管,30%以下就重新组织,30%以上就重新生成。通过下面的代码能查:
--这个查询出的id填到下面11的位置。
SELECT DB_ID()
--主要是从下表查碎片信息,avg_fragmentation_in_percent
SELECT b.name,b.id,b.xtype,a.* FROM sys.dm_db_index_physical_stats (11, NULL, NULL , NULL,'LIMITED') a
LEFT JOIN sysobjects b ON a.object_id=b.id
--这个查索引名字,注意不是sysindexes,中间有个点!这俩是两个表!!!
SELECT name,* FROM sys.indexes
下面这个就是实操了,千万别报错,另外先要备份和在测试服跑一下
ps:每次跑完一个库要drop #temp,有需要的自己可以做成proc
--先跑db_id(),找到id填到26的位置
SELECT DB_ID()
SELECT IDENTITY(INT,1,1) id ,* INTO #temp FROM (
select t.name tname,i.name indexname,s.avg_fragmentation_in_percent avgf from sys.tables t
join sys.indexes i on i.object_id=t.object_id
join sys.dm_db_index_physical_stats(26,NULL,null,null,'limited') s
on s.object_id=i.object_id and s.index_id=i.index_id
WHERE s.index_type_desc<>'HEAP' ) a
--看看索引情况
--SELECT * FROM #temp
--drop table #temp
--下面执行到end
DECLARE @i INT
DECLARE @sql NVARCHAR(3000)
DECLARE @tablename NVARCHAR(150)
DECLARE @indexname NVARCHAR(150)
SET @i=1
SET @sql=''
WHILE @i<=(SELECT MAX(id) FROM #temp)
BEGIN
IF (SELECT avgf FROM #temp WHERE id=@i) BETWEEN 10 AND 30
BEGIN
SET @tablename=(SELECT tname FROM #temp WHERE id=@i)
SET @indexname=(SELECT indexname FROM #temp WHERE id=@i)
SET @sql='alter index '+rtrim(@indexname)+' on dbo.'+quotename(rtrim(@tablename))+' reorganize'
EXEC(@sql)
PRINT(@i)
end
IF (SELECT avgf FROM #temp WHERE id=@i) > 30
BEGIN
SET @tablename=(SELECT tname FROM #temp WHERE id=@i)
SET @indexname=(SELECT indexname FROM #temp WHERE id=@i)
SET @sql='alter index '+rtrim(@indexname)+' on dbo.'+quotename(rtrim(@tablename))+' rebuild'
EXEC(@sql)
PRINT(@i)
end
SET @i+=1
END
--SELECT name,* FROM sys.indexes














 5338
5338











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









