







 本文探讨了如何使用MapReduce框架来高效实现矩阵相乘,详细介绍了输入格式、输出结果以及算法的分析过程,为分布式计算提供了一种解决方案。
本文探讨了如何使用MapReduce框架来高效实现矩阵相乘,详细介绍了输入格式、输出结果以及算法的分析过程,为分布式计算提供了一种解决方案。
Problem
让m * n矩阵A和n * p 的矩阵B相乘
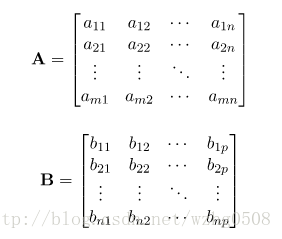
则相乘之后的结果矩阵AB为
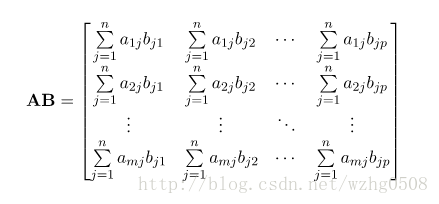
Input
输入文件含有多行,每行的格式如下,矩阵M,下标i,j,非0元素m(i,j)
<M><i><j><m_ij>
假设A、B如下所示:

则输入的文件内容如下:
A,0,1,1.0
A,0,2,2.0
A,0,3,3.0
A,0,4,4.0
A,1,0,5.0
A,1,1,6.0
A,1,2,7.0
A,1,3,8.0
A,1,4,9.0
B,0,1,1.0
B,0,2,2.0
B,1,0,3.0
B,1,1,4.0
B,1,2,5.0
B,2,0,6.0
B,2,1,7.0
B,2,2,8.0
B,3,0,9.0
B,3,1,10.0
B,3,2,11.0
B,4,0,12.0
B,4,1,13.0
B,4,2,14.0Output
数出文件格式是,矩阵M以及其非0元素m(i,j)
<i><j><m_ij>
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 8548
8548

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









