






 本文提出GPT4Rec模型,利用语言模型生成用户兴趣查询并结合搜索引擎检索项目,解决推荐系统的局限。通过beamsearch生成多样化的查询,但模型细节尚待完善,如如何处理多模态信息。
本文提出GPT4Rec模型,利用语言模型生成用户兴趣查询并结合搜索引擎检索项目,解决推荐系统的局限。通过beamsearch生成多样化的查询,但模型细节尚待完善,如如何处理多模态信息。
论文概况
本文是2023年的一篇大语言模型推荐论文,利用语言模型分析用户特征形成问询语句,再通过搜索模型分析问询语句找到目标物品,查询语句的来源有点疑惑。
problem define
推荐系统就是通过用户的一系列历史点击记录,推测下一时刻用户会点击什么物品。我们的模型学习的核心数据就是用户历史记录,但仅利用ID embedding分析用户与物品的交互是浅显的,一些方法也会增加一些物品本身的属性来增强模型的学习(如多模态推荐)。
Introduction
作者认为当前推荐模型使用ID embedding的形式导致以下限制:(1)不能充分利用项目的内容信息和NLP模型的语言建模能力;(2) 不能解释用户兴趣以提高相关性和多样性;以及(3)冷启动问题
针对上述问题,作者提出GPT4Rec模型:(1)这是一个新颖而灵活的生成框架,将推荐任务视为查询生成+搜索;(2) 我们采用beam search策略来产生多样化和可解释的用户兴趣表示
Method
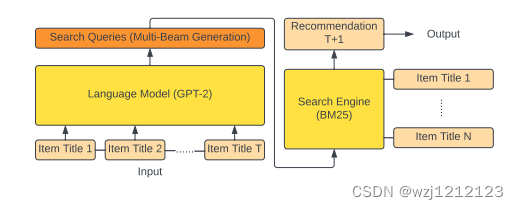
A.使用语言模型生成查询
首先利用GPT2模型来提取用户兴趣,模型向GPT提问
“Previously, the customer has bought:
<ITEM TITLE 1>. <ITEM TITLE 2>…
In the future, the customer wants to buy”
其中,是用户的历史点击物品的标题(名称),模型可以通过该语句分析出用户表征,并通过该语句为条件下的概率分布
P
(
.
∣
w
u
)
P(.|\mathrm{w}_{u})
P(.∣wu)生成针对该用户的查询语句。(没有说查询语句到底是什么,感觉是embedding)
为了更好地代表用户的不同兴趣,增加推荐结果的多样性,我们建议使用beam search技术生成多个查询,而不是单个查询。给定生成的查询数量m,相似度函数S(.),候选查询
Q
l
=
(
q
1
l
,
q
2
l
,
.
.
.
q
m
l
)
Q^{l}=(q_{1}^{l},q_{2}^{l},...q_{m}^{l})
Ql=(q1l,q2l,...qml)。beam search生成长度为l+1的
Q
l
+
1
Q^{l+1}
Ql+1,使得
S
(
W
u
,
q
)
最大,其中
q
∈
{
∣
q
∣
=
l
+
1
,
q
[
1
:
l
]
∈
Q
l
}
.
\textrm{S}(W^{u},q)最大,其中\quad q\in\{|q|=l+1,q_{[1:l]}\in Q^{l}\}.
S(Wu,q)最大,其中q∈{∣q∣=l+1,q[1:l]∈Ql}.(这里没有说m个候选查询是如何得到的,beam search也没有增加查询数,只是增加了每个查询的长度)
B.使用搜索引擎进行项目检索
第二个组成部分是一个充当“鉴别器”的搜索引擎。它将生成的每个查询作为输入,并使用匹配的分数函数检索库存中最相关的项目作为输出。这里使用BM25作为搜索引擎。
假设模型推荐K个物品,共有M个查询。模型根据每个查询的S(.)得分,从大到小依次取前K/M个物品作为结果。
C.训练策略
假设一个用户有T个交互物品,则我们用以下语句训练语言模型
“Previously, the customer has bought:
<ITEM i
i
1
i_{1}
i1>. <ITEM i
i
2
i_{2}
i2>…ITEM
i
T
−
1
i_{T-1}
iT−1
In the future, the customer wants to buy ITEM
i
T
i_{T}
iT”
在语言模型训练好之后,我们再将语言模型得到的查询作为输入训练搜索引擎,尽可能让搜索引擎的结果为ITEM i T i_{T} iT。
D.结果
可能是数据集不同,Electronics上最新的多模态方法recall20也才0.0648

总结
GPT4Rec模型的一些细节作者没有介绍清楚,目前的GPT4.0已经可以输入图片,如果将单纯的物品名称改变为文本+图片不知道是否会提升模型效果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









