






论文概况
本文是2024 AAAI的一篇联邦推荐论文,提出了一个公平性、隐私性、个性化兼顾的联邦推荐框架。
Introduction
- 我们引入了具有隐私保护的归纳图扩展算法,该算法可以最大限度地减少通信开销,同时有效地从分布式用户数据中捕获高阶交互
- 为了加强隐私保护,我们合并了一个额外的LDP模块用于模型更新以及保护组统计数据的隐私
Method
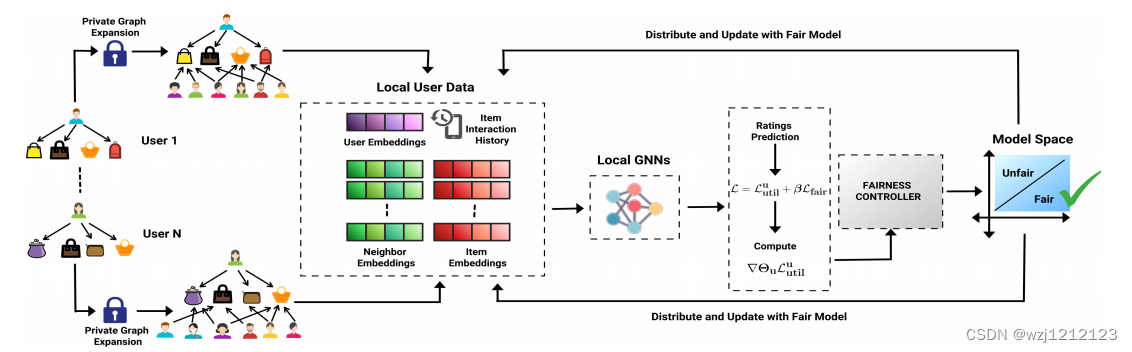
A.整体架构
首先,每个用户使用归纳私有图扩展算法扩展局部子图,以包含高阶交互。通过匹配加密项和分布匿名用户嵌入,扩展图包括每个用户的邻居与协同交互的项。对于每一个与m个项目交互的用户界面,以及与r个有共同交互项目的邻居,用户嵌入是
z
i
u
,
z_i^u,
ziu,物品嵌入是
[
z
i
,
1
t
,
z
i
,
2
t
,
⋯
z
i
,
m
t
]
\left[z_{i,1}^t,z_{i,2}^t,\cdots z_{i,m}^t\right]
[zi,1t,zi,2t,⋯zi,mt],邻居嵌入是
[
z
i
,
1
u
,
z
i
,
2
u
,
⋯
z
i
,
r
u
]
\begin{bmatrix}z_{i,1}^u,z_{i,2}^u,\cdots z_{i,r}^u\end{bmatrix}
[zi,1u,zi,2u,⋯zi,ru]。在图神经网络处理后,我们得到了
h
i
u
,
[
h
i
,
1
t
,
h
i
,
2
t
,
⋯
h
i
,
m
t
]
a
n
d
[
h
i
,
1
u
,
h
i
,
2
u
,
⋯
h
i
,
r
u
]
h_{i}^{u}, \left[h_{i,1}^{t},h_{i,2}^{t},\cdots h_{i,m}^{t}\right]\mathrm{~and~}\left[h_{i,1}^{u},h_{i,2}^{u},\cdots h_{i,r}^{u}\right]
hiu,[hi,1t,hi,2t,⋯hi,mt] and [hi,1u,hi,2u,⋯hi,ru]。
相应的损失是
L
u
t
i
l
u
=
1
m
∑
j
=
1
m
∣
y
^
i
,
j
−
y
i
,
j
∣
2
\mathcal{L}_{util}^{u}=\frac{1}{m}\sum_{j=1}^{m}|\hat{y}_{i,j}-y_{i,j}|^{2}
Lutilu=m1j=1∑m∣y^i,j−yi,j∣2
在该文章中,我们将公平性转化成损失加入到整体损失中
L
=
L
u
t
i
l
+
β
L
f
a
i
r
\mathcal{L}=\mathcal{L}_{util}+\beta\mathcal{L}_{fair}
L=Lutil+βLfair
其中,公平性损失的计算如下
L
f
a
i
r
(
M
,
S
0
,
S
1
)
=
∣
1
∣
S
0
∣
∑
u
∈
S
0
M
(
u
)
−
1
∣
S
1
∣
∑
u
∈
S
1
M
(
u
)
∣
α
\mathcal{L}_{fair}(\mathcal{M},S_0,S_1)=\left|\frac{1}{|S_0|}\sum_{u\in S_0}\mathcal{M}(u)-\frac{1}{|S_1|}\sum_{u\in S_1}\mathcal{M}(u)\right|^\alpha
Lfair(M,S0,S1)=
∣S0∣1u∈S0∑M(u)−∣S1∣1u∈S1∑M(u)
α
为了整体方案的可行性,我们定义
M
u
=
−
L
u
t
i
l
u
\mathcal{M}_{u} = -\mathcal{L}_{util}^{u}
Mu=−Lutilu。因此,损失的梯度为
∇
Θ
u
=
∂
∂
Θ
u
L
u
t
i
l
u
+
β
∂
∂
Θ
u
L
f
a
i
r
\nabla\Theta_u=\frac{\partial}{\partial\Theta_u}\mathcal{L}_{util}^u+\beta\frac{\partial}{\partial\Theta_u}\mathcal{L}_{fair}
∇Θu=∂Θu∂Lutilu+β∂Θu∂Lfair
其中,公平性梯度为
∂
∂
Θ
u
L
f
a
i
r
=
−
R
∣
P
−
Q
∣
α
−
1
∂
∂
Θ
u
L
u
t
i
l
u
\frac{\partial}{\partial\Theta_u}\mathcal{L}_{fair}=-R\left|P-Q\right|^{\alpha-1}\frac{\partial}{\partial\Theta_u}\mathcal{L}_{util}^{u}
∂Θu∂Lfair=−R∣P−Q∣α−1∂Θu∂Lutilu
因此,整体梯度为
∇
Θ
u
=
(
1
−
β
R
∣
P
−
Q
∣
α
−
1
)
∂
∂
Θ
u
L
u
t
i
l
u
=
L
∂
∂
Θ
u
L
u
t
i
l
u
\nabla\Theta_{u}=\left(1-\beta R\left|P-Q\right|^{\alpha-1}\right)\frac{\partial}{\partial\Theta_{u}}\mathcal{L}_{util}^{u}=L\frac{\partial}{\partial\Theta_{u}}\mathcal{L}_{util}^{u}
∇Θu=(1−βR∣P−Q∣α−1)∂Θu∂Lutilu=L∂Θu∂Lutilu
B.隐私保护
- 安全的用户-项目本地图扩展:每个用户使用公钥对项目进行加密,并将加密的id上传到服务器。匹配加密项后,服务器将匿名用户嵌入分发给每个用户,以扩展其本地子图。
- 隐私保护模型更新:我们使用标准的LDP技术来克服用户-项目交互历史的隐私泄露
- 安全群统计信息聚合:为了更新全局模型,服务器需要组统计信息P和Q,即用户是属于S0还是S1的信息。在FL中,上传用户的敏感属性信息侵犯了用户的隐私。我们使用LDP以安全的方式聚合组统计信息。
P p e r u ← 1 ( u ∈ S 0 ) M u + ϵ 1 , u , P a d d u ← 1 ( u ∈ S 0 ) + ϵ 3 , u Q p e r u ← 1 ( u ∈ S 1 ) M u + ϵ 2 , u , Q a d d u ← 1 ( u ∈ S 1 ) + ϵ 4 , u P_{per}^{u}\leftarrow1(u\in S_{0})\mathcal{M}_{u}+\epsilon_{1,u},P_{add}^{u}\leftarrow1(u\in S_{0})+\epsilon_{3,u}\\Q_{per}^{u}\leftarrow1(u\in S_{1})\mathcal{M}_{u}+\epsilon_{2,u},Q_{add}^{u}\leftarrow1(u\in S_{1})+\epsilon_{4,u} Pperu←1(u∈S0)Mu+ϵ1,u,Paddu←1(u∈S0)+ϵ3,uQperu←1(u∈S1)Mu+ϵ2,u,Qaddu←1(u∈S1)+ϵ4,u
整体算法流程如下:

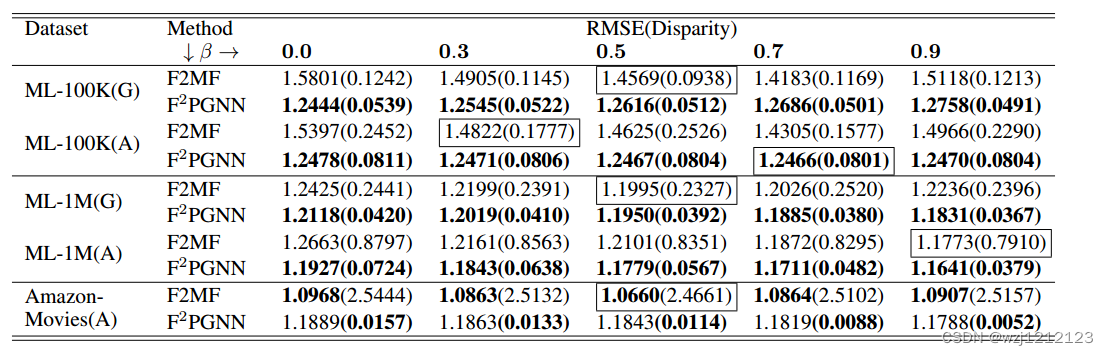
C.结果
总结
本文介绍了一种公平性联邦推荐系统框架,解决隐私与公平性问题,可对比的框架比较少。















 641
641

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









