









参考资料:
写在开头:本文为个人学习笔记,内容比较随意,夹杂个人理解,如有错误,欢迎指正。
目录
一、DMA的作用
1、早期IO的弊端
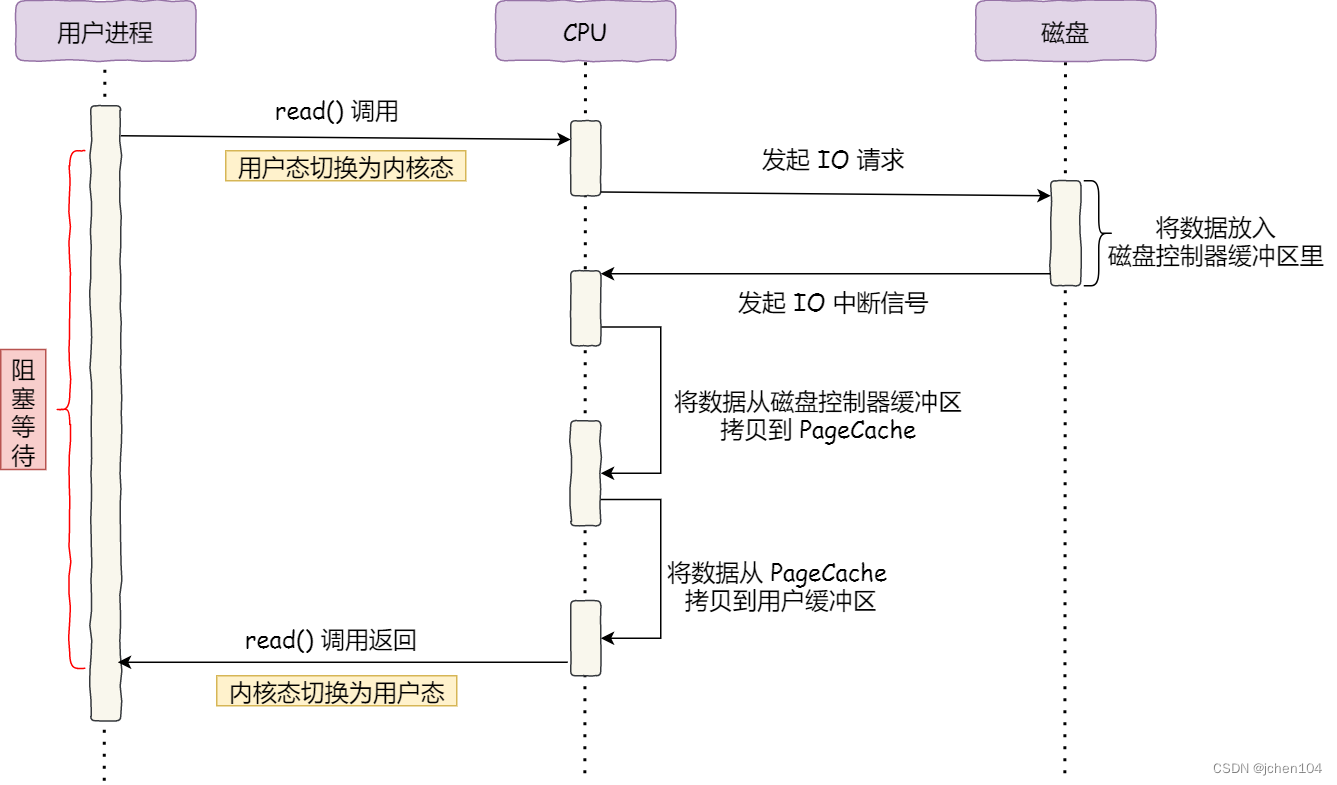
在早期的IO过程中,整个数据的传输过程,都要需要 CPU 亲自参与搬运数据的过程,而且这个过程,CPU 是不能做其他事情的。
具体过程如下:
- CPU 发出对应的指令给磁盘控制器,然后返回;
- 磁盘控制器收到指令后,于是就开始准备数据,会把数据放入到磁盘控制器的内部缓冲区(pagecache)中,然后产生一个中断;
- CPU 收到中断信号后,停下手头的工作,接着把磁盘控制器的缓冲区的数据读进自己的寄存器,然后再把寄存器里的数据写入到内存。
在数据传输的期间 CPU 是无法执行其他任务的。
如果数据只有几个字符数据那没问题,但是现在的文件传输都以M为单位,如果还是让CPU来做文件搬运,肯定是不合适的,所以DMA便应运而生。
2、DMA的使用
DMA 即直接内存访问(Direct Memory Access) 技术,在进行 I/O 设备和内存的数据传输的时候,数据搬运的工作全部交给 DMA 控制器,而 CPU 不再参与任何与数据搬运相关的事情,这样 CPU 就可以去处理别的事务。
具体过程如下:
- 用户进程调用 read 方法,向操作系统发出 I/O 请求,请求读取数据到自己的内存缓冲区中,进程进入阻塞状态;
- 操作系统收到请求后,进一步将 I/O 请求发送 DMA,然后让 CPU 执行其他任务;
- DMA 进一步将 I/O 请求发送给磁盘;
- 磁盘收到 DMA 的 I/O 请求,把数据从磁盘读取到磁盘控制器的缓冲区中,当磁盘控制器的缓冲区被读满后,向 DMA 发起中断信号,告知自己缓冲区已满;
- DMA 收到磁盘的信号,将磁盘控制器缓冲区中的数据拷贝到内核缓冲区中,此时不占用 CPU,CPU 可以执行其他任务;
- 当 DMA 读取了足够多的数据,就会发送中断信号给 CPU;
- CPU 收到 DMA 的信号,知道数据已经准备好,于是将数据从内核拷贝到用户空间,系统调用返回;
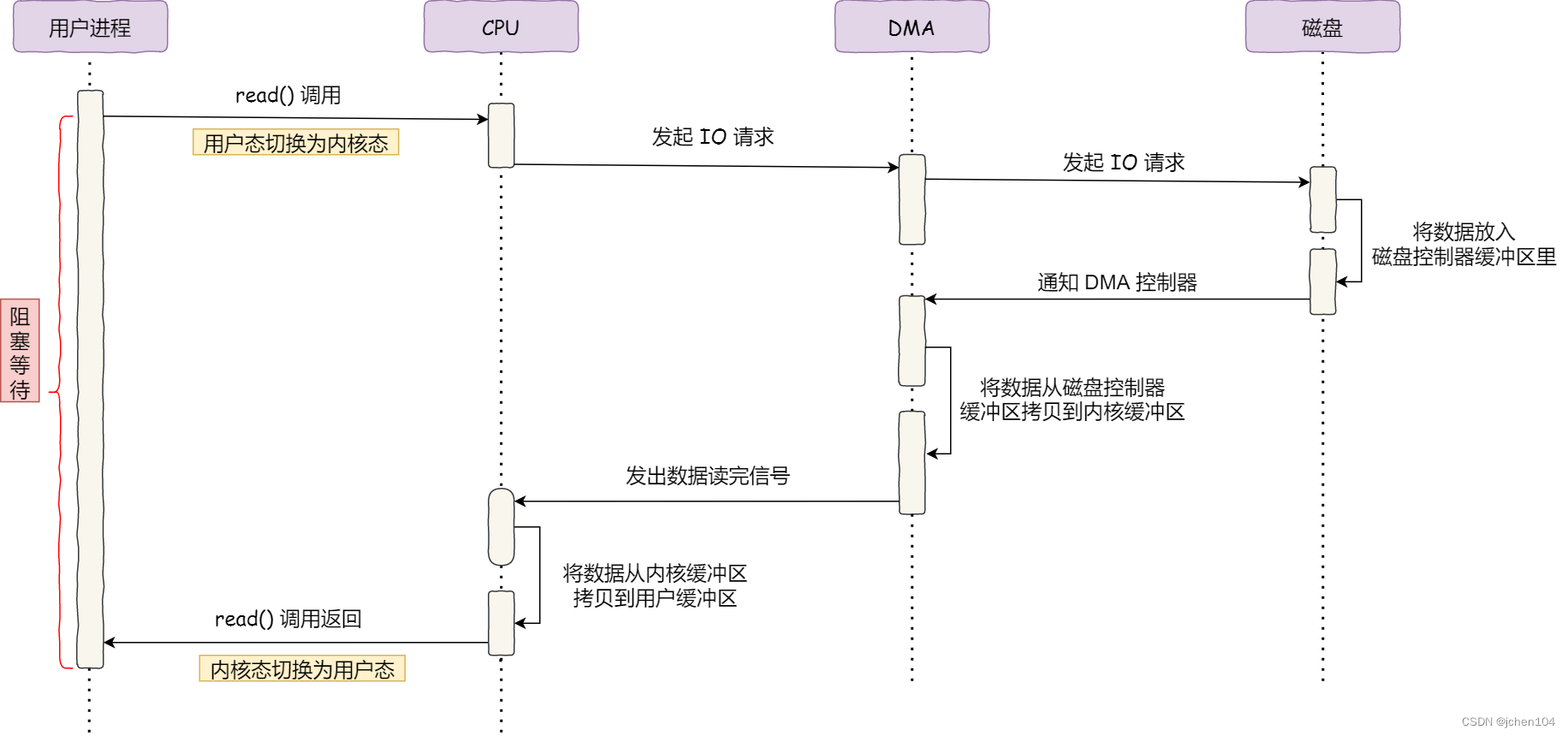
整个数据传输的过程,CPU 不再参与数据搬运的工作,而是全程由 DMA 完成,但是 CPU 在这个过程中也是必不可少的,因为传输什么数据,从哪里传输到哪里,都需要 CPU 来告诉 DMA 控制器。
二、文件传输方式的优化过程
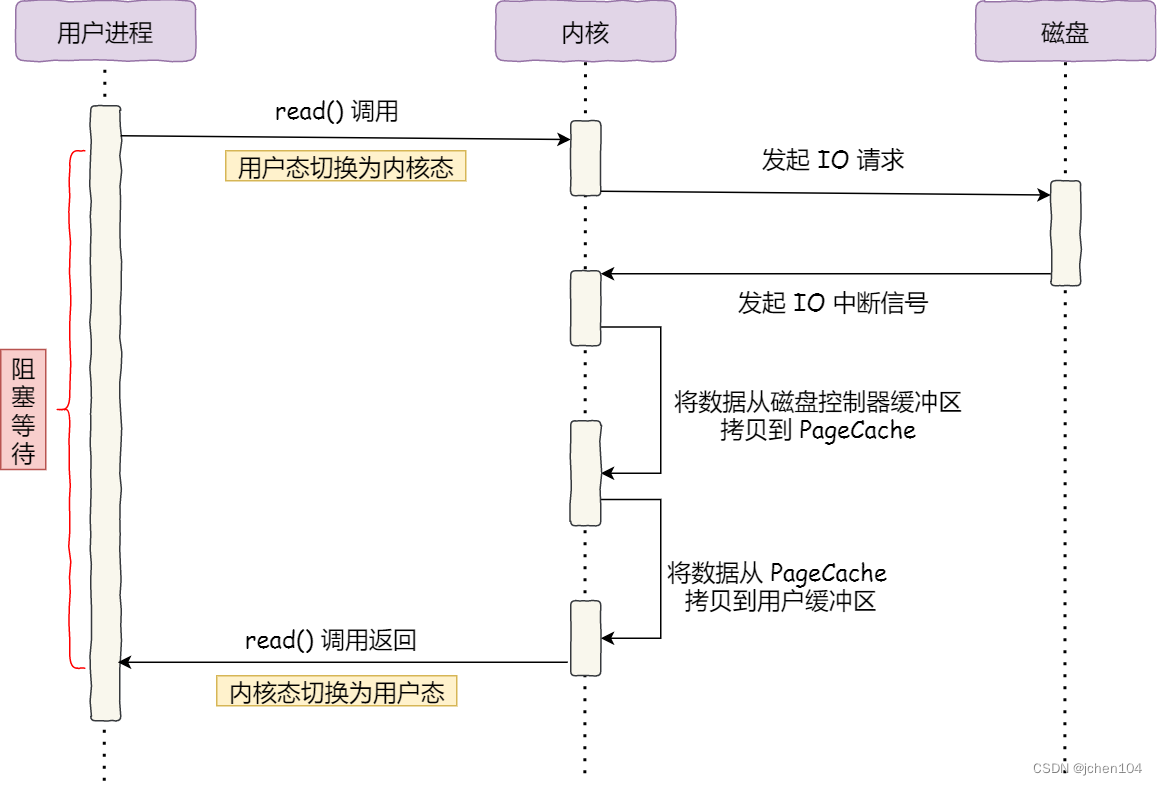
1、传统文件传输方式
服务端提供的文件传输的功能,需要将磁盘上的文件读取出来,然后通过网络协议发送给客户端。传统 I/O 的工作方式是,数据读取和写入是从用户空间到内核空间来回复制,而内核空间的数据是通过操作系统层面的 I/O 接口从磁盘读取或写入。
整个过程一般需要2个系统调用,read与write:
read(file, tmp_buf, len);
write(socket, tmp_buf, len);虽然只有2个系统调用,但是这里面发生了不少的事情。(下文中图片来源《Linux - 零拷贝技术》)

从上图中,我们可以看出,期间共发生了 4 次用户态与内核态的上下文切换,因为发生了两次系统调用,一次是 read() ,一次是 write(),每次系统调用都得先从用户态切换到内核态,等内核完成任务后,再从内核态切换回用户态。
上下文切换到成本并不小,一次切换需要耗时几十纳秒到几微秒,虽然时间看上去很短,但是在高并发的场景下,这类时间容易被累积和放大,从而影响系统的性能。
其次,还发生了 4 次数据拷贝,其中两次是 DMA 的拷贝,另外两次则是通过 CPU 拷贝的。我们来看下这4次文件拷贝操作:
- 第一次拷贝,把磁盘上的数据拷贝到操作系统内核的缓冲区里,这个拷贝的过程是通过 DMA 搬运的。
- 第二次拷贝,把内核缓冲区的数据拷贝到用户的缓冲区里,于是我们应用程序就可以使用这部分数据了,这个拷贝到过程是由 CPU 完成的。
- 第三次拷贝,把刚才拷贝到用户的缓冲区里的数据,再拷贝到内核的 socket 的缓冲区里,这个过程依然还是由 CPU 搬运的。
- 第四次拷贝,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程又是由 DMA 搬运的。
整个文件传输的过程,我们只是搬运一份数据,结果却搬运了 4 次,过多的数据拷贝无疑会消耗 CPU 资源,大大降低了系统性能。这种简单又传统的文件传输方式,存在冗余的上文切换和数据拷贝,在高并发系统里是非常糟糕的,多了很多不必要的开销,会严重影响系统性能。
所以,要想提高文件传输的性能,就需要减少「用户态与内核态的上下文切换」和「内存拷贝」的次数。
2、使用mmap + write减少拷贝次数
mmap原理
传统的文件传输方式会历经 4 次数据拷贝,这里面「从内核的读缓冲区拷贝到用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里」这个过程是没有必要的。因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
在前面我们知道,read() 系统调用的过程中会把内核缓冲区的数据拷贝到用户的缓冲区里,于是为了减少这一步开销,我们可以用 mmap() 替换 read() 系统调用函数。
buf = mmap(file, len);
write(sockfd, buf, len);
mmap() 系统调用函数会直接把内核缓冲区里的数据「映射」到用户空间,这样,操作系统内核与用户空间就不需要再进行任何的数据拷贝操作。
具体过程如下:
- 应用进程调用了 mmap() 后,DMA 会把磁盘的数据拷贝到内核的缓冲区里,然后应用进程跟操作系统内核「共享」这个缓冲区;
- 应用进程再调用 write(),操作系统直接将内核缓冲区的数据拷贝到 socket 缓冲区中,这一切都发生在内核态,由 CPU 来搬运数据;
- 最后,把内核的 socket 缓冲区里的数据,拷贝到网卡的缓冲区里,这个过程是由 DMA 搬运的。
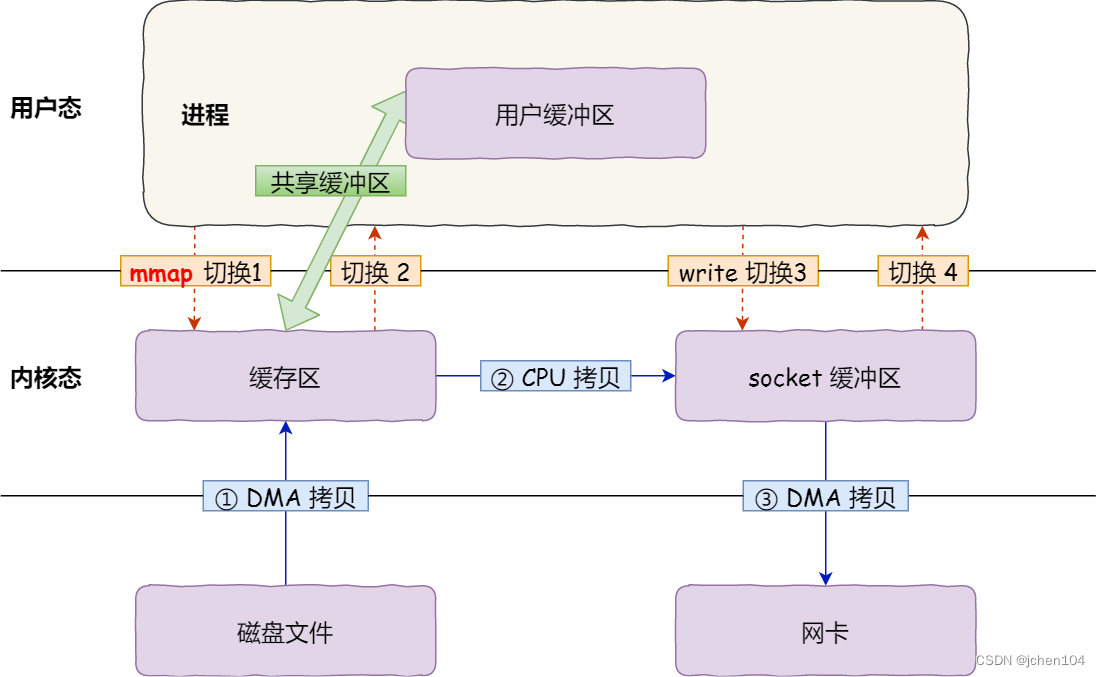
我们可以得知,通过使用 mmap() 来代替 read(), 可以减少一次数据拷贝的过程。
MappedByteBuffer实现内存映射(mmap)
MappedByteBuffer 是 NIO 基于内存映射(mmap)这种零拷贝方式的提供的一种实现,它继承自 ByteBuffer。FileChannel 定义了一个 map() 方法,它可以把一个文件从 position 位置开始的 size 大小的区域映射为内存映像文件。抽象方法 map() 方法在 FileChannel 中的定义如下:
public abstract MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException;
三个参数的含义如下:
- mode:限定内存映射区域(MappedByteBuffer)对内存映像文件的访问模式,包括只可读(READ_ONLY)、可读可写(READ_WRITE)和写时拷贝(PRIVATE)三种模式。
- position:文件映射的起始地址,对应内存映射区域(MappedByteBuffer)的首地址。
- size:文件映射的字节长度,从 position 往后的字节数,对应内存映射区域(MappedByteBuffer)的大小。
MappedByteBuffer 相比 ByteBuffer 新增了 force()、load() 和 isLoad() 三个重要的方法:
- fore():对于处于 READ_WRITE 模式下的缓冲区,把对缓冲区内容的修改强制刷新到本地文件。
- load():将缓冲区的内容载入物理内存中,并返回这个缓冲区的引用。
- isLoaded():如果缓冲区的内容在物理内存中,则返回 true,否则返回 false。
下面给出一个利用 MappedByteBuffer 对文件进行读写的使用示例:
private final static String CONTENT = "Zero copy implemented by MappedByteBuffer";
private final static String FILE_NAME = "/mmap.txt";
private final static String CHARSET = "UTF-8";
写文件数据:打开文件通道 fileChannel 并提供读权限、写权限和数据清空权限,通过 fileChannel 映射到一个可写的内存缓冲区 mappedByteBuffer,将目标数据写入 mappedByteBuffer,通过 force() 方法把缓冲区更改的内容强制写入本地文件。
@Test
public void writeToFileByMappedByteBuffer() {
Path path = Paths.get(getClass().getResource(FILE_NAME).getPath());
byte[] bytes = CONTENT.getBytes(Charset.forName(CHARSET));
try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) {
MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_WRITE, 0, bytes.length);
if (mappedByteBuffer != null) {
mappedByteBuffer.put(bytes);
mappedByteBuffer.force();
}
} catch (IOException e) {
e.printStackTrace();
}
}
读文件数据:打开文件通道 fileChannel 并提供只读权限,通过 fileChannel 映射到一个只可读的内存缓冲区 mappedByteBuffer,读取 mappedByteBuffer 中的字节数组即可得到文件数据。
@Test
public void readFromFileByMappedByteBuffer() {
Path path = Paths.get(getClass().getResource(FILE_NAME).getPath());
int length = CONTENT.getBytes(Charset.forName(CHARSET)).length;
try (FileChannel fileChannel = FileChannel.open(path, StandardOpenOption.READ)) {
MappedByteBuffer mappedByteBuffer = fileChannel.map(READ_ONLY, 0, length);
if (mappedByteBuffer != null) {
byte[] bytes = new byte[length];
mappedByteBuffer.get(bytes);
String content = new String(bytes, StandardCharsets.UTF_8);
assertEquals(content, "Zero copy implemented by MappedByteBuffer");
}
} catch (IOException e) {
e.printStackTrace();
}
}
我们可以看出内存映射是通过map() 方法实现的,该方法是 java.nio.channels.FileChannel 的抽象方法,由子类 sun.nio.ch.FileChannelImpl.java 实现,下面是和内存映射相关的核心代码:
public MappedByteBuffer map(MapMode mode, long position, long size) throws IOException {
int pagePosition = (int)(position % allocationGranularity);
long mapPosition = position - pagePosition;
long mapSize = size + pagePosition;
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
throw new IOException("Map failed", y);
}
}
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize, addr + pagePosition, mfd, um);
} else {
return Util.newMappedByteBuffer(isize, addr + pagePosition, mfd, um);
}
}
map() 方法通过本地方法 map0() 为文件分配一块虚拟内存,作为它的内存映射区域,然后返回这块内存映射区域的起始地址。
- 文件映射需要在 Java 堆中创建一个 MappedByteBuffer 的实例。如果第一次文件映射导致 OOM,则手动触发垃圾回收,休眠 100ms 后再尝试映射,如果失败则抛出异常。
- 通过 Util 的 newMappedByteBuffer (可读可写)方法或者 newMappedByteBufferR(仅读) 方法方法反射创建一个 DirectByteBuffer 实例,其中 DirectByteBuffer 是 MappedByteBuffer 的子类。
map() 方法返回的是内存映射区域的起始地址,通过(起始地址 + 偏移量)就可以获取指定内存的数据。这样一定程度上替代了 read() 或 write() 方法,底层直接采用 sun.misc.Unsafe类的 getByte() 和 putByte() 方法对数据进行读写。
3、使用sendfile减少拷贝次数与切换次数
sendfile原理
在 Linux 内核版本 2.1 中,提供了一个专门发送文件的系统调用函数 sendfile(),函数形式如下:
#include <sys/socket.h>
ssize_t sendfile(int out_fd, int in_fd, off_t *offset, size_t count);
它的前两个参数分别是目的端和源端的文件描述符,后面两个参数是源端的偏移量和复制数据的长度,返回值是实际复制数据的长度。过程如下:
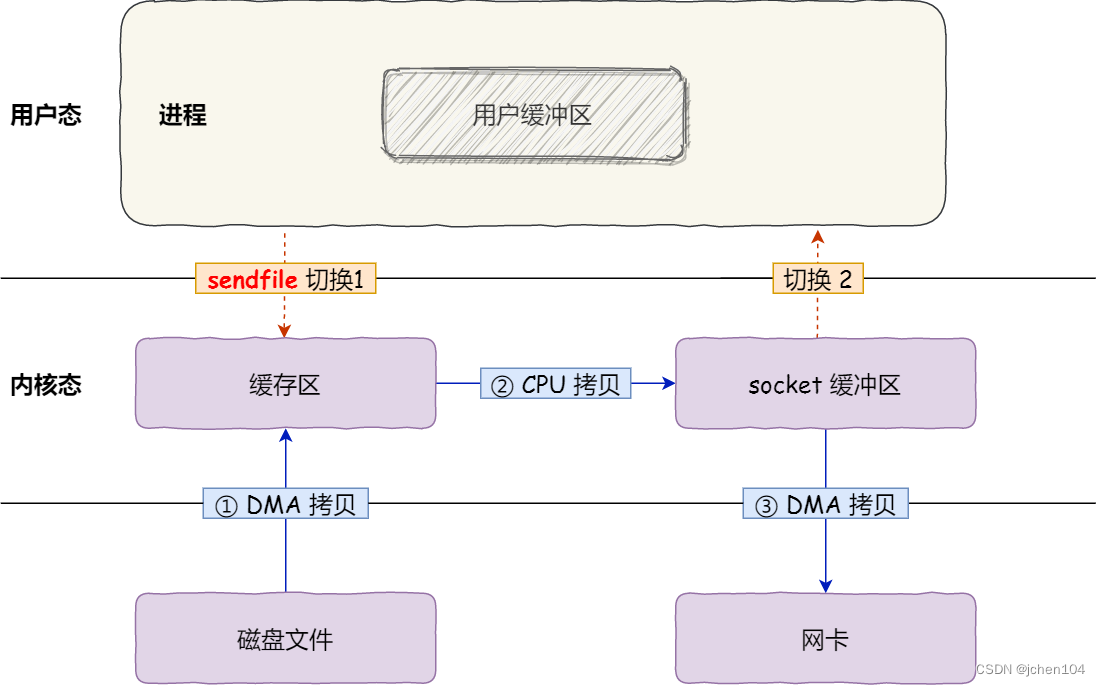
从上图中可以看出,sendfile替代了前面的 read() 和 write() 这两个系统调用,这样就可以减少一次系统调用,也就减少了 2 次上下文切换的开销。其次,该系统调用,可以直接把内核缓冲区里的数据拷贝到 socket 缓冲区里,不再拷贝到用户态,这样就只有 2 次上下文切换,和 3 次数据拷贝。
FileChannel实现sendfile
FileChannel 是一个用于文件读写、映射和操作的通道,同时它在并发环境下是线程安全的,基于 FileInputStream、FileOutputStream 或者 RandomAccessFile 的 getChannel() 方法可以创建并打开一个文件通道。FileChannel 定义了 transferFrom() 和 transferTo() 两个抽象方法,它通过在通道和通道之间建立连接实现数据传输的。
transferTo():通过 FileChannel 把文件里面的源数据写入一个 WritableByteChannel 的目的通道。
public abstract long transferTo(long position, long count, WritableByteChannel target)
throws IOException;
transferFrom():把一个源通道 ReadableByteChannel 中的数据读取到当前 FileChannel 的文件里面。
public abstract long transferFrom(ReadableByteChannel src, long position, long count)
throws IOException;
下面给出 FileChannel 利用 transferTo() 和 transferFrom() 方法进行数据传输的使用示例:
private static final String CONTENT = "Zero copy implemented by FileChannel";
private static final String SOURCE_FILE = "/source.txt";
private static final String TARGET_FILE = "/target.txt";
private static final String CHARSET = "UTF-8";
首先在类加载根路径下创建 source.txt 和 target.txt 两个文件,对源文件 source.txt 文件写入初始化数据。
@Before
public void setup() {
Path source = Paths.get(getClassPath(SOURCE_FILE));
byte[] bytes = CONTENT.getBytes(Charset.forName(CHARSET));
try (FileChannel fromChannel = FileChannel.open(source, StandardOpenOption.READ,
StandardOpenOption.WRITE, StandardOpenOption.TRUNCATE_EXISTING)) {
fromChannel.write(ByteBuffer.wrap(bytes));
} catch (IOException e) {
e.printStackTrace();
}
}
对于 transferTo() 方法而言,目的通道 toChannel 可以是任意的单向字节写通道 WritableByteChannel;而对于 transferFrom() 方法而言,源通道 fromChannel 可以是任意的单向字节读通道 ReadableByteChannel。
其中,FileChannel、SocketChannel 和 DatagramChannel 等通道实现了 WritableByteChannel 和 ReadableByteChannel 接口,都是同时支持读写的双向通道。为了方便测试,下面给出基于 FileChannel 完成 channel-to-channel 的数据传输示例。
通过 transferTo() 将 fromChannel 中的数据拷贝到 toChannel
@Test
public void transferTo() throws Exception {
try (FileChannel fromChannel = new RandomAccessFile(
getClassPath(SOURCE_FILE), "rw").getChannel();
FileChannel toChannel = new RandomAccessFile(
getClassPath(TARGET_FILE), "rw").getChannel()) {
long position = 0L;
long offset = fromChannel.size();
fromChannel.transferTo(position, offset, toChannel);
}
}
通过 transferFrom() 将 fromChannel 中的数据拷贝到 toChannel
@Test
public void transferFrom() throws Exception {
try (FileChannel fromChannel = new RandomAccessFile(
getClassPath(SOURCE_FILE), "rw").getChannel();
FileChannel toChannel = new RandomAccessFile(
getClassPath(TARGET_FILE), "rw").getChannel()) {
long position = 0L;
long offset = fromChannel.size();
toChannel.transferFrom(fromChannel, position, offset);
}
}
下面介绍 transferTo() 和 transferFrom() 方法的底层实现原理,这两个方法也是 java.nio.channels.FileChannel 的抽象方法,由子类 sun.nio.ch.FileChannelImpl.java 实现。transferTo() 和 transferFrom() 底层都是基于 sendfile 实现数据传输的,其中 FileChannelImpl.java 定义了 3 个常量,用于标示当前操作系统的内核是否支持 sendfile 以及 sendfile 的相关特性。
private static volatile boolean transferSupported = true;
private static volatile boolean pipeSupported = true;
private static volatile boolean fileSupported = true;
transferSupported:用于标记当前的系统内核是否支持 sendfile() 调用,默认为 true。pipeSupported:用于标记当前的系统内核是否支持文件描述符(fd)基于管道(pipe)的 sendfile() 调用,默认为 true。fileSupported:用于标记当前的系统内核是否支持文件描述符(fd)基于文件(file)的 sendfile() 调用,默认为 true。
下面以 transferTo() 的源码实现为例。FileChannelImpl 首先执行 transferToDirectly() 方法,以 sendfile 的零拷贝方式尝试数据拷贝。如果系统内核不支持 sendfile,进一步执行 transferToTrustedChannel() 方法,以 mmap 的零拷贝方式进行内存映射,这种情况下目的通道必须是 FileChannelImpl 或者 SelChImpl 类型。
如果以上两步都失败了,则执行 transferToArbitraryChannel() 方法,基于传统的 I/O 方式完成读写,具体步骤是初始化一个临时的 DirectBuffer,将源通道 FileChannel 的数据读取到 DirectBuffer,再写入目的通道 WritableByteChannel 里面。
public long transferTo(long position, long count, WritableByteChannel target)
throws IOException {
// 计算文件的大小
long sz = size();
// 校验起始位置
if (position > sz)
return 0;
int icount = (int)Math.min(count, Integer.MAX_VALUE);
// 校验偏移量
if ((sz - position) < icount)
icount = (int)(sz - position);
long n;
if ((n = transferToDirectly(position, icount, target)) >= 0)
return n;
if ((n = transferToTrustedChannel(position, icount, target)) >= 0)
return n;
return transferToArbitraryChannel(position, icount, target);
}
接下来重点分析一下 transferToDirectly() 方法的实现,也就是 transferTo() 通过 sendfile 实现零拷贝的精髓所在。可以看到,transferToDirectlyInternal() 方法先获取到目的通道 WritableByteChannel 的文件描述符 targetFD,获取同步锁然后执行 transferToDirectlyInternal() 方法。
private long transferToDirectly(long position, int icount, WritableByteChannel target)
throws IOException {
// 省略从target获取targetFD的过程
if (nd.transferToDirectlyNeedsPositionLock()) {
synchronized (positionLock) {
long pos = position();
try {
return transferToDirectlyInternal(position, icount,
target, targetFD);
} finally {
position(pos);
}
}
} else {
return transferToDirectlyInternal(position, icount, target, targetFD);
}
}
最终由 transferToDirectlyInternal() 调用本地方法 transferTo0() ,尝试以 sendfile 的方式进行数据传输。如果系统内核完全不支持 sendfile,比如 Windows 操作系统,则返回 UNSUPPORTED 并把 transferSupported 标识为 false。如果系统内核不支持 sendfile 的一些特性,比如说低版本的 Linux 内核不支持 DMA gather copy 操作,则返回 UNSUPPORTED_CASE 并把 pipeSupported 或者 fileSupported 标识为 false。
private long transferToDirectlyInternal(long position, int icount,
WritableByteChannel target,
FileDescriptor targetFD) throws IOException {
assert !nd.transferToDirectlyNeedsPositionLock() ||
Thread.holdsLock(positionLock);
long n = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return -1;
do {
n = transferTo0(fd, position, icount, targetFD);
} while ((n == IOStatus.INTERRUPTED) && isOpen());
if (n == IOStatus.UNSUPPORTED_CASE) {
if (target instanceof SinkChannelImpl)
pipeSupported = false;
if (target instanceof FileChannelImpl)
fileSupported = false;
return IOStatus.UNSUPPORTED_CASE;
}
if (n == IOStatus.UNSUPPORTED) {
transferSupported = false;
return IOStatus.UNSUPPORTED;
}
return IOStatus.normalize(n);
} finally {
threads.remove(ti);
end (n > -1);
}
}
4、SG-DMA进一步优化
SG-DMA(The Scatter-Gather Direct Memory Access)技术(和普通的 DMA 有所不同),我们可以进一步减少通过 CPU 把内核缓冲区里的数据拷贝到 socket 缓冲区的过程。
Linux 系统通过下面这个命令,可以查看网卡是否支持 scatter-gather 特性:
$ ethtool -k eth0 | grep scatter-gather
scatter-gather: on
于是,从 Linux 内核 2.4 版本开始起,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化,具体过程如下:
- 第一步,通过 DMA 将磁盘上的数据拷贝到内核缓冲区里;
- 第二步,缓冲区描述符和数据长度传到 socket 缓冲区,这样网卡的 SG-DMA 控制器就可以直接将内核缓存中的数据拷贝到网卡的缓冲区里,此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝;
所以,这个过程之中,只进行了 2 次数据拷贝,如下图:
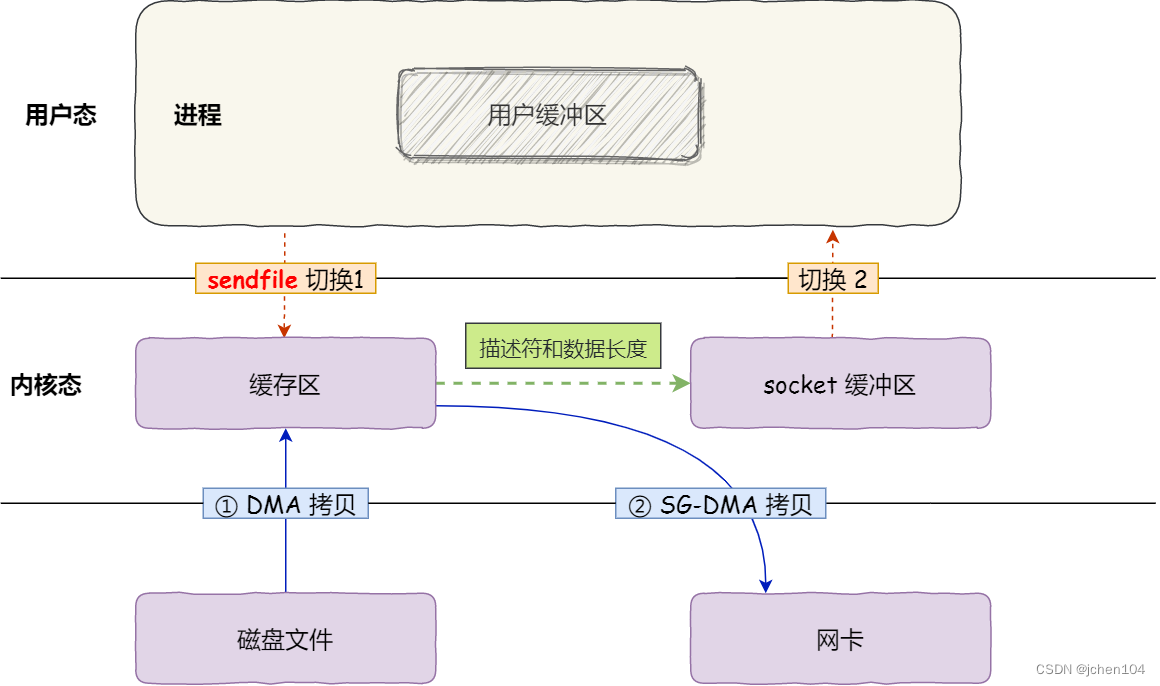
这就是所谓的零拷贝(Zero-copy)技术,因为我们没有在内存层面去拷贝数据,也就是说全程没有通过 CPU 来搬运数据,所有的数据都是通过 DMA 来进行传输的。
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 2 次上下文切换和数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
总体来看,零拷贝技术可以把文件传输的性能提高至少一倍以上。
三、大文件传输方法
1、PageCache的作用
回顾前面说道文件传输过程,其中第一步都是先需要先把磁盘文件数据拷贝「内核缓冲区」里,这个「内核缓冲区」实际上是磁盘高速缓存(PageCache)。
由于零拷贝使用了 PageCache 技术,可以使得零拷贝进一步提升了性能,我们接下来看看 PageCache 是如何做到这一点的。
读写磁盘相比读写内存的速度慢太多了,所以我们应该想办法把「读写磁盘」替换成「读写内存」。于是,我们会通过 DMA 把磁盘里的数据搬运到内存里,这样就可以用读内存替换读磁盘。
但是,内存空间远比磁盘要小,内存注定只能拷贝磁盘里的一小部分数据。那问题来了,选择哪些磁盘数据拷贝到内存呢?
我们都知道程序运行的时候,具有「局部性」,所以通常,刚被访问的数据在短时间内再次被访问的概率很高,于是我们可以用 PageCache 来缓存最近被访问的数据,当空间不足时淘汰最久未被访问的缓存。
所以,读磁盘数据的时候,优先在 PageCache 找,如果数据存在则可以直接返回;如果没有,则从磁盘中读取,然后缓存 PageCache 中。
还有一点,读取磁盘数据的时候,需要找到数据所在的位置,但是对于机械磁盘来说,就是通过磁头旋转到数据所在的扇区,再开始「顺序」读取数据,但是旋转磁头这个物理动作是非常耗时的,为了降低它的影响,PageCache 使用了「预读功能」。
比如,假设 read 方法每次只会读 32 KB 的字节,虽然 read 刚开始只会读 0 ~ 32 KB 的字节,但内核会把其后面的 32~64 KB 也读取到 PageCache,这样后面读取 32~64 KB 的成本就很低,如果在 32~64 KB 淘汰出 PageCache 前,进程读取到它了,收益就非常大。
所以,PageCache 的优点主要是两个:
- 缓存最近被访问的数据;
- 预读功能;
这两个做法,将大大提高读写磁盘的性能。
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DMA 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能
这是因为如果你有很多 GB 级别文件需要传输,每当用户访问这些大文件的时候,内核就会把它们载入 PageCache 中,于是 PageCache 空间很快被这些大文件占满。
另外,由于文件太大,可能某些部分的文件数据被再次访问的概率比较低,这样就会带来 2 个问题:
- PageCache 由于长时间被大文件占据,其他「热点」的小文件可能就无法充分使用到 PageCache,于是这样磁盘读写的性能就会下降了;
- PageCache 中的大文件数据,由于没有享受到缓存带来的好处,但却耗费 DMA 多拷贝到 PageCache 一次;
所以,针对大文件的传输,不应该使用 PageCache,也就是说不应该使用零拷贝技术,因为可能由于 PageCache 被大文件占据,而导致「热点」小文件无法利用到 PageCache,这样在高并发的环境下,会带来严重的性能问题。
2、直接IO+异步IO
大文件传输时在原始的模式下有2个问题,一个是用户进程阻塞等待,另一个是pagecache被大文件沾满,无法为高频小文件服务。
对于阻塞的问题,可以用异步 I/O 来解决,对于pagecache被大文件沾满我们采用直接IO绕过ragecache。过程如下:
- 第一步,内核向磁盘发起读请求,但是可以不等待数据就位就可以返回,于是进程此时可以处理其他任务;
- 第二步,当内核将磁盘中的数据拷贝到进程缓冲区后,进程将接收到内核的通知,再去处理数据;
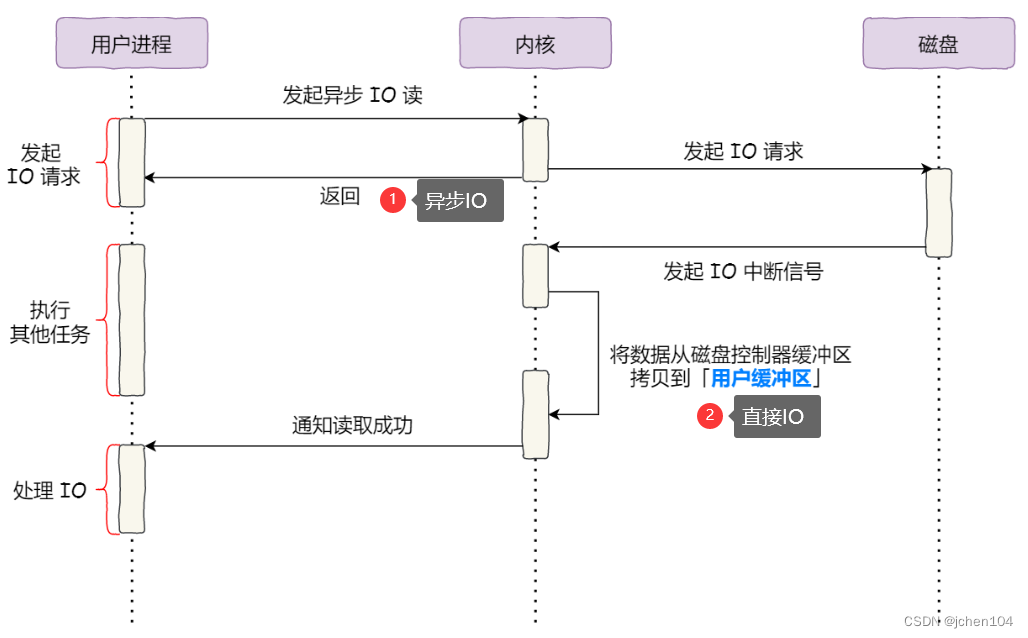
于是,在高并发的场景下,针对大文件的传输的方式,应该使用「异步 I/O + 直接 I/O」来替代零拷贝技术。
直接 I/O 应用场景常见的两种:
- 应用程序已经实现了磁盘数据的缓存,那么可以不需要 PageCache 再次缓存,减少额外的性能损耗。在 MySQL 数据库中,可以通过参数设置开启直接 I/O,默认是不开启;
- 传输大文件的时候,由于大文件难以命中 PageCache 缓存,而且会占满 PageCache 导致「热点」文件无法充分利用缓存,从而增大了性能开销,因此,这时应该使用直接 I/O。
另外,由于直接 I/O 绕过了 PageCache,就无法享受内核的这两点的优化:
- 内核的 I/O 调度算法会缓存尽可能多的 I/O 请求在 PageCache 中,最后「合并」成一个更大的 I/O 请求再发给磁盘,这样做是为了减少磁盘的寻址操作;
- 内核也会「预读」后续的 I/O 请求放在 PageCache 中,一样是为了减少对磁盘的操作; 于是,传输大文件的时候,使用「异步 I/O + 直接 I/O」了,就可以无阻塞地读取文件了。
所以,传输文件的时候,我们要根据文件的大小来使用不同的方式:
- 传输大文件的时候,使用「异步 I/O + 直接 I/O」;
- 传输小文件的时候,则使用「零拷贝技术」;需要注意的是,零拷贝技术是不允许进程对文件内容作进一步的加工的,比如压缩数据再发送。
在 nginx 中,我们可以用如下配置,来根据文件的大小来使用不同的方式:
location /video/ {
sendfile on;
aio on;
directio 1024m;
}















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









