







王智生---原创作品转载请注明出处
本系列为《Linux内核分析》MOOC课程(http://mooc.study.163.com/course/USTC-1000029000 )对应学习笔记,文章不定期更新
一、冯诺依曼体系结构
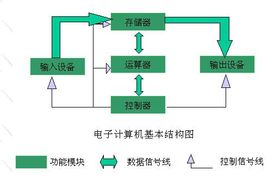
- 设计思想:
“程序存储概念”--->即把数据和处理数据的程序都存储在同一个存储器上,具体内容为:
(1)计算机应包括运算器、存储器、控制器、输入和输出设备五大基本部件。
(2)计算机内部应采用二进制来表示指令和数据。每条指令一般具有一个操作码和一个地址码。其中操作码表示运算性质,地址码指出操作数在存储器中的地址。
(3)采用存储程序方式。将编好的程序送人内存储器中,然后启动计算机工作,计算机勿需操作人员干预,能自动逐条取出指令和执行指令。
- 与哈佛体系结构的区别:
哈佛体系机构将数据和程序指令存储在不同的的存储器中,两者的总线相互独立,相对不会造成总线的拥挤,有利于高速处理。
二、X86汇编基础
参考来源:http://www.ibm.com/developerworks/cn/linux/l-assembly/
《Professional AssemblyLanguage》Chapter4
(一)、完整汇编代码组成:
一般的汇编代码会包括三个部分
❑ The data section
❑ The bss section
❑ The text section(在一段程序中必须存在)
当一段汇编代码被编译为可执行代码时,通常以_start作为identifier来标记程序从哪里开始执行,没有时编译器会报错:
$ ld -o badtest badtest.o
ld: warning: cannot find entry symbol _start;defaulting to 08048074
*想自己修改identifier:-e
*一般加.global 即定义为全局可见,使程序可以被外部程序访问。
² 一个常见的的汇编模板为:
.section.data
< initialized data here>
.section .bss
< uninitialized data here>
.section .text
.globl _start
_start:
<instruction code goes here>
需要注意的是当我们使用gcc对程序进行编译时,默认以main作为程序开始,因此程序要进行修改:
"You must change both the _start label and the.globl directive defining the label in your program to look like the following:"
.section .text
.globl main
main:
(二)、cpuid指令指令介绍
cpuid 指令顾名思义是用来获取处理器的信息,该指令由eax 寄存器获得输入(功能号),执行cpuid 指令前,将功能号传给eax 寄存器:
输入:eax
输出:ebx、ecx、edx---->分段储存处理器的信息
以下列出了部分功能号对应的输出信息:

举个例子,当输入eax寄存器的功能号为0时:
movl $0, %eax
cpuid
输出数据存储方式:
❑ EBX contains the low 4 bytes of thestring.
❑ EDX contains the middle 4 bytes of thestrin
❑ ECX contains the last 4 bytes of thestring
更多内容请参考《ProfessionalAssembly Language》
(三)、汇编程序的调试
编译时要使用-gstabs参数保证汇编代码可被调试(会增大编译出的文件):
$ as -gstabs -o cpuid.o cpuid.s
$ ld -o cpuid cpuid.o
(-Wall:showall warnings)
² 常用的调试命令
1、开始调试:
$ gdb cpuid
2、运行程序:
(gdb) run
3、设置断点:
break *label+offset
4、单步运行:
next or step
5、查看寄存器信息或内存地址:

举例:

Print:以某一格式显示寄存器的值
❑ print/d to display the value in decimal
❑ print/t to display the value in binary
❑ print/x to display the value inhexadecimal
6、x/nyz显示某一内存地址的信息:
where n is the number of fields to display, y is theformat of the output, and can be
❑ c for character
❑ d for decimal
❑ x for hexadecimal
and z is the size of the field to be displayed:
❑ b for byte
❑ h for 16-bit word (half-word)
❑ w for 32-bit word
其他部分,如"如何使用C语言库的库函数"及"如何生成链接C函数库"请参考《Professional AssemblyLanguage》Chapter4 的内容。
(四)AT&T汇编格式
在Unix 和 Linux 系统中的汇编格式为AT&T格式,区别于intel下的汇编格式:
- 在 AT&T 汇编格式中,寄存器名要加上 '%' 作为前缀;而在 Intel 汇编格式中,寄存器名不需要加前缀。例如:
| AT&T 格式 | Intel 格式 |
| pushl %eax | push eax |
- 在 AT&T 汇编格式中,用 '$' 前缀表示一个立即操作数;而在 Intel 汇编格式中,立即数的表示不用带任何前缀。例如:
| AT&T 格式 | Intel 格式 |
| pushl $1 | push 1 |
- AT&T 和 Intel 格式中的源操作数和目标操作数的位置正好相反。在 Intel 汇编格式中,目标操作数在源操作数的左边;而在 AT&T 汇编格式中,目标操作数在源操作数的右边。例如:
| AT&T 格式 | Intel 格式 |
| addl $1, %eax | add eax, 1 |
- 在 AT&T 汇编格式中,操作数的字长由操作符的最后一个字母决定,后缀'b'、'w'、'l'分别表示操作数为字节(byte,8 比特)、字(word,16 比特)和长字(long,32比特);而在 Intel 汇编格式中,操作数的字长是用 "byte ptr" 和 "word ptr" 等前缀来表示的。例如:
| AT&T 格式 | Intel 格式 |
| movb val, %al | mov al, byte ptr val |
- 在 AT&T 汇编格式中,绝对转移和调用指令(jump/call)的操作数前要加上'*'作为前缀,而在 Intel 格式中则不需要。
- 远程转移指令和远程子调用指令的操作码,在 AT&T 汇编格式中为 "ljump" 和 "lcall",而在 Intel 汇编格式中则为 "jmp far" 和 "call far",即:
| AT&T 格式 | Intel 格式 |
| ljump $section, $offset | jmp far section:offset |
| lcall $section, $offset | call far section:offset |
- 与之相应的远程返回指令则为:
| AT&T 格式 | Intel 格式 |
| lret $stack_adjust | ret far stack_adjust |
- 在 AT&T 汇编格式中,内存操作数的寻址方式是
section:disp(base, index, scale)
而在Intel 汇编格式中,内存操作数的寻址方式为:
section:[base + index*scale + disp]
由于Linux 工作在保护模式下,用的是32 位线性地址,所以在计算地址时不用考虑段基址和偏移量,而是采用如下的地址计算方法:
disp + base + index * scale
下面是一些内存操作数的例子:
| AT&T 格式 | Intel 格式 |
| movl -4(%ebp), %eax | mov eax, [ebp - 4] |
| movl array(, %eax, 4), %eax | mov eax, [eax*4 + array] |
| movb $4, %fs:(%eax) | mov fs:eax, 4 |
三、寄存器及其寻址方式:
参考:http://note.youdao.com/groupshare/?token=DEA8E718F97F43DF9A424A5E91B369B4&gid=7182204
Ø x86,IA32体系结构中寄存器的情况如下:
x86中14个寄存器:AX、BX、CX、DX、SI、DI、SP、BP、IP、FLAGS、CS、SS、DS、ES
IA32寄存器:把16位的通用寄存器、标志寄存器以及指令指针寄存器扩充为32位的寄存器,段寄存器仍然为16位,增加了两个段寄存器,增加4个32位的控制寄存器,增加4个系统地址寄存器,增加8个调试寄存器,增加2个测试寄存器。
AX、 BX、 CX、 DX、 SI、 DI、 SP、 BP、 IP、 FLAGS、 CS、SS、DS、ES
EAX、EBX、ECX、EDX、ESI、EDI、ESP、EBP、EIP、EFLAGS、CS、SS、DS、ES、FS、GS、CR0、CR1、CR2、CR3、GDTR、IDTR、TR、LDTR、DR0~DR7、TR6、TR7.
对于寄存器,特别是通用寄存器中的eax,ebx,ecx,edx,32位的eax,16位的ax,8位的ah,al都是独立的,举个栗子:
假定当前是32位x86机器,eax寄存器的值为0x8226,执行完addw $0x8266, %ax指令后eax的值是多少? 解析:0x8226+0x826=0x1044c,ax是16位寄存器,出现溢出,最高位的1会丢掉,剩下0x44c,不要以为eax是32位的不会发生溢出.
大家都知道,在内存和磁盘上,指令和数据都是二进制信息是没有什么区别的,指令和数据只是应用上的含义,那内存中的数据什么情况下是指令,什么情况下是数据呢?
(1)任何时刻,CPU将CS:EIP指向的内容当做指令执行;
(2)任何时刻,CPU将DS:[内存地址]指向的内容当做数据,内存地址的获取可以有多种寻址方式;
(3)对于栈,任何时刻,SS:ESP指向栈顶元素,一般使用EBP指向栈底。
Ø 寻址方式:
处理器根据指令中给出的地址信息来寻找物理地址的方式。在实模式下,简单总结如下(摘自王爽《汇编语言》,注意AT&T语法会有所不同):
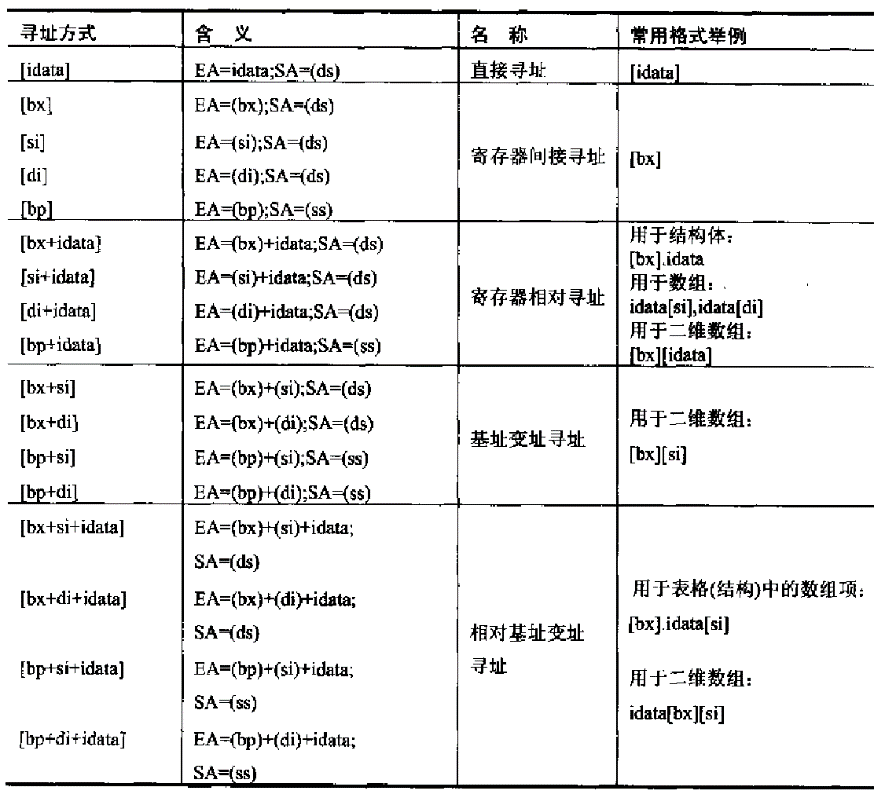
在8086的实模式下,把某一段寄存器左移4位,然后与地址ADDR相加后被直接送到内存总线上,这个相加后的地址就是内存单元的物理地址,而程序中的这个地址就叫逻辑地址(或叫虚地址)。在IA32的保护模式下,这个逻辑地址不是被直接送到内存总线而是被送到内存管理单元(MMU)。MMU由一个或一组芯片组成,其功能是把逻辑地址映射为物理地址,即进行地址转换。如下图:
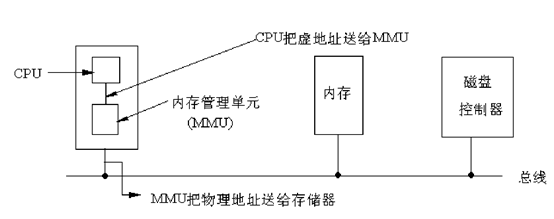
在保护模式下,我们使用三种地址:
1、逻辑地址:
机器语言指令仍用这种地址指定一个操作数的地址或一条指令的地址。这种寻址方式在Intel的分段结构中表现得尤为具体,它使得程序员把程序分为若干段。每个逻辑地址都由一个段和偏移量组成。
2、线性地址:
线性地址是一个32位的无符号整数,可以表达高达4GB的地址。通常用16进制表示线性地址,其取值范围为0x00000000~0xffffffff。
3、物理地址:
也就是内存单元的实际地址,用于芯片级内存单元寻址。物理地址也由32位无符号整数表示。
MMU是一种硬件电路,它包含两个部件,一个是分段部件,一个是分页部件,在此,我们把它们分别叫做分段机制和分页机制,以利于从逻辑的角度来理解硬件的实现机制。分段机制把一个逻辑地址转换为线性地址;接着,分页机制把一个线性地址转换为物理地址。如下图所示:

四、实例分析:反汇编一段C程序并分析(未整理)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









