








上篇介绍的多类回归,因变量的多个分类是无序的,即所谓的定类数据。还有一种分类数据,其类别存在大小顺序,即定序数据。这两类逻辑回归的原理是不同的。本篇介绍MADlib的序数回归模型。
一、序数回归简介
在统计学中,序数回归(Ordinal Regression,也称为“序数分类”)是一种用于预测序数变量的回归分析,即其值存在于任意范围内的变量,其中只有不同值之间的相对排序是显着的。它可以被认为是介于回归和分类之间的一类问题。例如,病情的分级(1、2、3、4级),症状的感觉分级(不痛、微痛、较痛和剧痛),对药物剂量反应的分级(无效、微效、中效和高效)等等。不同级别之间的差异不一定相等,如不痛与微痛的差值不一定等于较痛与剧痛的差值。如果把这些指标作为因变量,可以采用序数回归来分析。在机器学习中,序数回归也可以称为排序学习。
ordered logit和ordered probit是两种最普通的序数回归模型。两种模型的差别在于对残差项的假设不同,前者假设是Logistic分布,后者假设是正态分布。当数据符合比例优势假定条件时通常应用ordered logit。MADlib的序数回归模型支持这两种实现方式。
序数回归的原理是从二元逻辑回归上衍生出来的,它最终的拟合结果是因变量水平数减1个logit回归模型,因此也称为累积logit模型。例如,因变量是4个水平的定序数据,4个水平的取值分别为1、2、3、4,它们发生的概率设为p1、p2、p3和p4,那么该序数回归模型可以写成下面的形式:
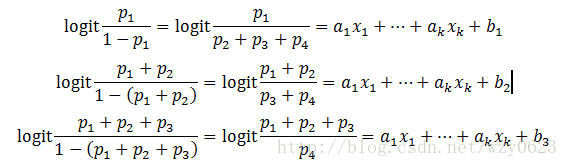
对于上面的式子,其实和二元逻辑回归模型是一样的,只不过将因变量的多个类别拆分为几个模型式子来解读而已。同时,因为因变量是有序的定序数据,所以序数回归模型产生的几个模型的因变量概率是递增的,也就是有序结果的累积概率。
比较上面三个式子,可以发现三个模型的自变量个数和回归系数都是相同的,唯一区别在于常数项,也就是说所有自变量对因变量不同类型结果的影响趋势是相同的,只是截距不同而已。这也是序数回归模型建立的基本假设前提。通过上述模型,就可以求出因变量中每种结果的概率值:

二、MADlib的有序回归相关函数
1. 训练函数
(1) 语法
ordinal(source_table,
model_table,
dependent_varname,
independent_varname,
cat_order,
link_func,
grouping_col,
optim_params,
verbose
)(2) 参数
参数名称 | 数据类型 | 描述 |
source_table | VARCHAR | 包含训练数据的表名。 |
model_table | VARCHAR | 包含输出模型的表名。主输出表列和概要输出表列如表2、3所示。 |
dependent_varname | VARCHAR | 因变量列名。 |
independent_varname | VARCHAR | 评估使用的自变量的表达式列表。此处不应包含截距,累积概率里包含了每个类别的截距。 |
cat_order | VARCHAR | 表示类别顺序的字符串,顺序由'<'字符指示。 |
link_function(可选) | VARCHAR | 缺省为'logit'。连接函数参数,当前支持logit和probit。 |
grouping_col(可选) | VARCHAR | 缺省值为NULL。和SQL中的“GROUP BY”类似,是一个将输入数据集分成离散组的表达式,每个组运行一个回归。此值为NULL时,将不使用分组,并产生一个单一的结果模型。 |
optim_params(可选) | VARCHAR | 缺省值为'max_iter=100,optimizer=irls,tolerance=1e-6',指定优化参数。 |
verbose(可选) | BOOLEAN | 缺省值为FALSE,指定是否提供训练的详细输出结果。 |
表1 ordinal函数参数说明
列名 | 数据类型 | 描述 |
<...> | TEXT | 分组列,取决于grouping_col输入,可能是多个列。 |
coef_threshold | FLOAT8[] | 线性预测中阈值系数向量。阈值系数是每个特定级别的截距。 |
std_err_threshold | FLOAT8[] | 阈值系数标准差向量。 |
z_stats_threshold | FLOAT8[] | 阈值系数z-统计向量。 |
p_values_threshold | FLOAT8[] | 阈值系数p值向量。 |
log_likelihood | FLOAT8 | 对数似然比l(c)。 |
coef_feature | FLOAT8[] | 线性预测中特征系数向量。 |
std_err_feature | FLOAT8[] | 特征系数标准差向量。 |
z_stats_feature | FLOAT8[] | 特征系数z-统计向量。 |
p_values_feature | FLOAT8[] | 特征系数p值向量。 |
num_rows_processed | BIGINT | 实际处理的行数。 |
num_missing_rows_skipped | BIGINT | 训练时因为缺失值或错误跳过的行数。 |
num_iterations | INTEGER | 实际迭代次数。 |
表2 ordinal函数主输出表列说明
训练函数在产生输出表的同时,还会创建一个名为<model_table>_summary的概要表,具有以下列:
列名 | 数据类型 | 描述 |
method | VARCHAR | 'ordinal',描述模型的字符串。 |
source_table | VARCHAR | 源表名。 |
model_table | VARCHAR | 模型表名。 |
dependent_varname | VARCHAR | 因变量表达式。 |
independent_varname | VARCHAR | 自变量表达式。 |
cat_order | VARCHAR | 表示类别顺序的字符串,默认是使用python排序的类别。 |
link_func | VARCHAR | 连接函数参数,当前实现了'logit'和'probit'。 |
grouping_col | VARCHAR | 分组列。 |
optimizer_params | VARCHAR | 包含所有优化参数的字符串,形式是‘optimizer=..., max_iter=..., tolerance=...’。 |
num_all_groups | INTEGER | 分组数。 |
num_failed_groups | INTEGER | 失败分组数。 |
total_rows_processed | BIGINT | 所有分组处理的总行数。 |
total_rows_skipped | BIGINT | 所有组由于缺少值或失败跳过的总行数。 |
表3 ordinal函数概要输出表列说明
2. 预测函数
(1) 语法
ordinal_predict(model_table,
predict_table_input,
output_table,
predict_type,
verbose
) (2) 参数
参数名称 | 数据类型 | 描述 |
model_table | TEXT | 训练函数生成的模型表名,是ordinal()函数的输出表。 |
predict_table_input | TEXT | 包含被预测数据的表名。表中必须有作为主键的ID列。 |
output_table | TEXT | 包含预测结果的输出表名。输出表的列根据predict_type参数而有所不同。当predict_type = response时,输出表中包含两列:SERIAL类型的id,表示主键,TEXT类型的category列,包含预测的类别。predict_type = probability时,除id列外,每个类别输出一列,列名就是类别值,列值数据类型为FLOAT8,表示预测为该类别的概率。 |
predict_type | TEXT | 'response'或'probability'。使用前者将输出预测最大概率的类别值,使用后者将输出每种类别的预测概率。 |
verbose | BOOLEAN | 控制是否显示详细信息,缺省值为FALSE。 |
表4 ordinal_predict函数参数说明
三、示例
1. 问题提出
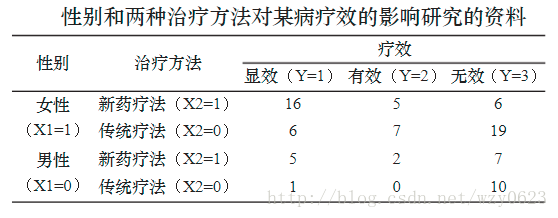
研究性别和两种治疗方法对某病疗效的影响,疗效的评价为3个有序等级:显效、有效和无效,数据见下图,做回归分析。
2. 训练模型
(1)建立测试数据表并装载原始数据
drop table if exists t1;
create table t1 (id serial, y int, x1 int, x2 int);
insert into t1 (y, x1, x2) values
(1, 1, 1), (1, 1, 1), (1, 1, 1), (1, 1, 1),
(1, 1, 1), (1, 1, 1), (1, 1, 1), (1, 1, 1),
(1, 1, 1), (1, 1, 1), (1, 1, 1), (1, 1, 1),
(1, 1, 1), (1, 1, 1), (1, 1, 1), (1, 1, 1),
(2, 1, 1), (2, 1, 1), (2, 1, 1), (2, 1, 1), (2, 1, 1),
(3, 1, 1), (3, 1, 1), (3, 1, 1), (3, 1, 1), (3, 1, 1), (3, 1, 1),
(1, 1, 0), (1, 1, 0), (1, 1, 0), (1, 1, 0), (1, 1, 0), (1, 1, 0),
(2, 1, 0), (2, 1, 0), (2, 1, 0), (2, 1, 0), (2, 1, 0), (2, 1, 0), (2, 1, 0),
(3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0),
(3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0),
(3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0), (3, 1, 0),
(1, 0, 1), (1, 0, 1), (1, 0, 1), (1, 0, 1), (1, 0, 1),
(2, 0, 1), (2, 0, 1),
(3, 0, 1), (3, 0, 1), (3, 0, 1), (3, 0, 1), (3, 0, 1), (3, 0, 1), (3, 0, 1),
(1, 0, 0),
(3, 0, 0), (3, 0, 0), (3, 0, 0), (3, 0, 0), (3, 0, 0),
(3, 0, 0), (3, 0, 0), (3, 0, 0), (3, 0, 0), (3, 0, 0); (2)用logit连接函数训练
drop table if exists t1_logit;
drop table if exists t1_logit_summary;
select madlib.ordinal('t1',
't1_logit',
'y',
'array[x1, x2]',
'1<2<3',
'logit'
); (3)查看回归结果
\x on
select * from t1_logit; 结果:
-[ RECORD 1 ]------+-------------------------------------------
coef_threshold | {-2.66719475180658,-1.81280141886419}
std_err_threshold | {0.599702042621952,0.556613728546557}
z_stats_threshold | {-4.44753321190197,-3.25683921522709}
p_values_threshold | {8.68620322445124e-06,0.00112660228456281}
log_likelihood | -75.0147065448914
coef_feature | {-1.31875159864631,-1.79730338412896}
std_err_feature | {0.529191401906822,0.472823747708925}
z_stats_feature | {-2.49201251927843,-3.80121217015394}
p_values_feature | {0.0127021560134723,0.000143989936924618}
num_rows_processed | 84
num_rows_skipped | 0
num_iterations | 6 从回归的结果看,P值并不是很小,而对数似然值的绝对值较大,说明该模型的可靠性不高。
3. 使用模型进行预测源表数据
\x off
drop table if exists t1_prd_logit;
select madlib.ordinal_predict('t1_logit','t1', 't1_prd_logit', 'response');
-- 显示预测
select istrue, count(*) from (
select t0.id, t1.y realvalue, t0.category predict,
case when t1.y = t0.category then 'T' else 'F' end istrue
from t1_prd_logit t0, t1
where t0.id = t1.id
) t group by istrue; 结果:
istrue | count
--------+-------
F | 32
T | 52
(2 rows) 可以看到该模型在源数据上的预测正确的为52条,错误的有32条,也印证了模型的可靠性较差。















 6011
6011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









