






 本文详细介绍了如何在Ubuntu环境下创建Hadoop用户,更新apt并设置网络,克隆DataNode,安装Java及JDK,配置vim编辑器,进行Hadoop的伪分布式配置。还涉及了VMware中的文件操作和Hadoop服务的启动与停止。
本文详细介绍了如何在Ubuntu环境下创建Hadoop用户,更新apt并设置网络,克隆DataNode,安装Java及JDK,配置vim编辑器,进行Hadoop的伪分布式配置。还涉及了VMware中的文件操作和Hadoop服务的启动与停止。
1.进行用户创建 /bin/bash

图1 创建Hadoop用户
2. 更新apt,在更新apt之前进行网络适配器的设置,如图2所示改为NAT模式

图2 更改网络适配器

图3 更新apt
3.克隆出2台DataNode主机
根据node-master主机克隆出DataNode主机
修改node1、node2主机名以及编辑host文件使三者之间能够通信
在master主机上生成密钥,使之能免认证登录其他两个主机
-在master主机上执行 ssh-keygen -b 4096 命令
-拷贝生成公钥到其他机器。
-ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node-master
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node1
ssh-copy-id -i $HOME/.ssh/id_rsa.pub hadoop@node2
实现文件拖拽、复制剪切等操作步骤
- 在VMware虚拟机中运行Ubuntu,按ctrl+Alt+t进行终端界面。
- 运行sudo apt install open-vm-tools安装基本软件包(输入密码)。
- 运行命令sudo apt install open-vm-tools-desktop以支持桌面环境的双向拖放文件。
- 关闭该虚拟机,在虚拟机设置的”硬件”部署部分打开的”显示器”设置,确认已选中”加速3D图形”选项。
- 重启虚拟机,实现文件拖拽、复制和剪切等操作。
4.安装java环境

图4 安装java环境教案图
5. 进行java安装包的下载和解压

图5 安装java环境图
6. 成功安装jdk如下图所示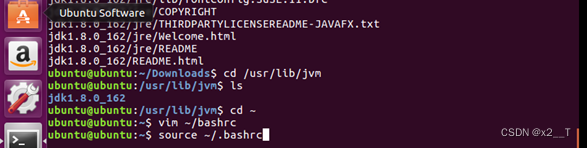
图6 成功安装jdk图
7. 进入vim编辑页面指令

图7 进入vim编辑
8. 打开etc/profile文件如下图所示,在文件最前面加入export命令

图8 profile文件详细图
9. 安照教程输入ubuntu@ubuntu:~$ vim ~/bashrc
显示界面如下:

图9 vim ~/bashrc
-
出现错误,如图10所示

图10 配置环境变量 -
若在etc/profile里面配置则成功如图10所示
-
安装Hadoop
 图11 安装Hadoop操作图
图11 安装Hadoop操作图

图12 安装Hadoop成功图 -
对Hadoop进行伪分布式配置,修改当中的配置文件core-site.xml和hdfs-site.xml,配置成功后输入cd /usr/local/hadoop和./bin/hdfs namenode -format查看是否成功,成功界面如下图所示。

图13 伪分布式配置成功图 -
最后,若要关闭Hadoop,输入./sbin/stop-dfs.sh运行即可















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









