







 本文深入剖析HBase的存储架构,包括RegionServer、Region、Store等核心组件,以及MemStore、StoreFile、HFile的工作机制,揭示各模块如何协同工作以提升性能。
本文深入剖析HBase的存储架构,包括RegionServer、Region、Store等核心组件,以及MemStore、StoreFile、HFile的工作机制,揭示各模块如何协同工作以提升性能。
简介:
本文介绍HBase中的数据存储模块,先从微观层面拆分出每个存储模块讲解,然后再从宏观层面介绍这些模块之间是怎样协同工作的,以及为什么需要这些存储模块,它们帮HBase实现了那些功能和性能上的提升。
一.RegionServer
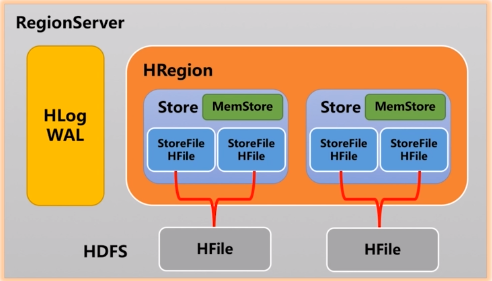
RegionServer的结构:
RegionServer = Region + Store + MemStore + StoreFile + HFile + HLog
接下来将逐个介绍RegionServer中的这些模块。
二.Region
Region的重点介绍:
- Region是数据分布式存储和负载均衡的最小单元(存储的最小单元是HFile),是Client和RegionServer交互的实际载体。
- Region通过三个信息标识自己:tableName,startRowKey(Rowkey是有序的),createTime(最早一条数据的插入时间)。
- 一个Region是一张表中的一行数据(不会出现一行数据出现在多个Region中)。
- 一个RegionServer包含许多的Region,每个Region包含的数据都是互斥的(不会出现一个Region存在多个RegionServer上)。
- 当Region中的数据不断插入,或者某个列族的数据到达一定的阈值后,Region将会水平拆分两个Region。
- 当RegionServer挂了后,Master会通过负载均衡策略将Region移动到其他RegionServer上。
- Region的数量一定不能低于集群中节点的数量(数据量大到一定程度时,避免某个节点压力过大,不能做到负载均衡)。
什么是数据库的水平拆分?
水平拆分就是将表横向切分,就像在一张白纸划一道横线,白纸就分为上下两部分。这样每一部分都保存着完整的字段,只是有些数据保存在上面部分,有些数据保存在下面部分。如下图:
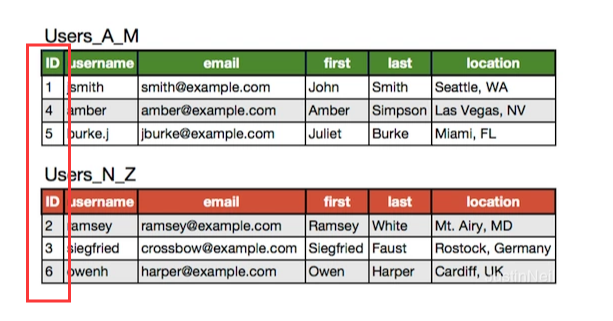
上图中,表中ID为奇数存在一张表中,偶数存在另一张表中,这样就是表的水平拆分。
Region的拆分过程:
Region的拆分是不可见的,Master不参与拆分。RegionServer先将要拆分的Region下线,然后拆分;再将子Region加入到Mata元信息中,再将两个Region添加到RegionServer上,最后同步到Master上(这就是HBase负载均衡的原理)。
根据拆分原理得到的优化技巧:
在设计表,尤其是RowKey时,尽量让数据分散到多台Server上,避免单个节点成为热点,才能发挥出HBase的性能。
三.Store
每个Region有多个Store。Store对应每个表的列族,表里有多少个列族,Region中就有多少个Store。Region会根据Store的大小,决定是否切分Region。
四.MemStore
每个Store又包含多个MEMStore,MEMStore是内存式的数据结构。
MemStore保存修改的数据,即用户put、delete的请求,默认大小64M,HBase有异步线程进行刷写。
五.StoreFile
HBase会将内存中的数据写入到文件中,这里的文件指的就是StoreFile。StoreFile底层是以HFile格式保存,HFile下文会专门介绍。
六.HFile
存储数据的最小单元,HFile底层是Hadoop的二进制格式文件(Key-Value类型)。
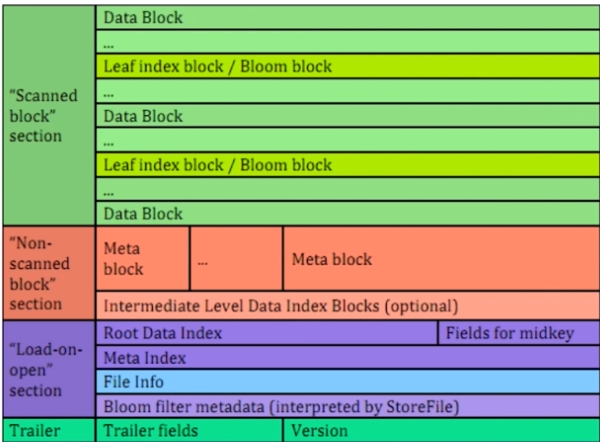
接下来介绍一下HFile中的各个模块:
①Scanned Block Section:
顺序扫描HFile时,此部分数据将被读取,用户数据就保存这个分区中(HFile最重要的功能)。
Data Block:
Data Block是由Key-Value结构组成,这就是为什么HBase是Key-Value存储的。每个Key-Value由Key Length、value length、key、value 4个部分组成,keylength 和value length主要在偏移时候,起到作用。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RTvWFgqR-1599123508856)(https://note.youdao.com/yws/public/resource/babda7978b0415833a56f265c7ae77d8/xmlnote/8DC775EA2B01461097FED47625BD336F/62527)]
-
Key:
结合上图来看,Data Block中的Key中包含以下内容:
名称 含义 Row Length 行键长度 Row 行键 Column Family length 列族长度 Column Family 列族 Column Qualifier length 列描述符的长度 Column Qualifier 列描述符 Timestamp 时间戳 Key Type 键类型 -
Key Type:
由于写入到HFile中的数据,是不可修改的,只能通过先删除后增加实现修改,所以当需要删除数据时,KeyType就起作用了。
KeyType类型 含义 put 插入数据。 delete 删除整行数据。 delete Column 删除整列数据。 delete Family 删除一个列族。 我们可以用Key Type,来给数据做一个
墓碑标记,表示这个数据被删除掉了。HBase在扫描HFile时,当看到标记delete、delete column、delete family时,就认为这些数据已经不存在了;HBase会在以后运行中(具体在什么时候,下文还会详细介绍),将这些标记为删除的数据删除掉,这样就提高了HBase的存储插入的性能。
②Non-scanned Block Section:
顺序扫描HFile时,Non-scanned Block Section区域不会被扫描,该区域包含了一些元数据块。
③"Load-on-open" Section:
在RegionServer启动时,“Load-on-open” Section会加载到内存中的。该区域保存了HBase元数据相关信息。
④Trailer:
Trailer中保存HFile的基本信息,偏移量和寻址信息。也保存了一部分的元数据(Mata)信息。
总结
本文分析了HBase中的各个存储模块,以及所有HBase存储模块的介绍,我建议将本文作为HBase名词的字典,遇到这些存储模块时,就来查看一下它的作用介绍,这样就更容易理解HBase的运行机制,以及各个模块之间是怎样协作运行的了。
在后续的文章中,将介绍下Hbase的日志系统。喜欢本文就点赞和收藏吧。

















 681
681

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









