






文章目录
前言
善始者繁多,克终者盖寡。
数据分析的过程大抵可分为数据收集、数据预处理、数据分析、数据可视化四个环节,数据预处理是数据分析前最重要的一个环节,主要包括数据清洗、数据集成、数据规约、数据变换四种操作。今天和大家分享使用pandas对数据进行“清洗”。
一、“清洗”什么
举一个例子,刚从地里摘了一颗白菜,发现白菜的根须上有很多泥巴,还有一些烂叶子,再下锅前需要把这些泥巴、烂叶子给去掉。
数据清洗就类似这个过程,通过第三方平台收集到的数据里往往包含很多不规范的数据,主要指空值、异常值、重复值,在数据分析前我们需要将其处理掉。
二、python实现
2.1 数据来源
以某地区电信客户流失数据为例,表中包含19个字段323条记录,每个字段中包含若干空值,表格结构如图所示:
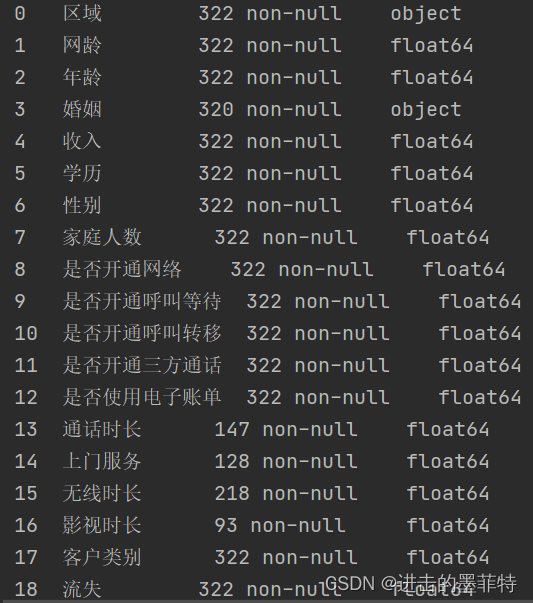
2.2 查找空值
import pandas
数据 = pandas.read_csv("电信客户流失数据-东城区.csv")
print(数据)
#粗略浏览数据分布
print(数据.isnull())
#查询所有包含空值的列
print(数据.isnull().any())
程序运行后,发现所有的列都存在空值!!!

2.3 空值处理
根据数据分布情况(空值多不多),采用不同的处理方法:
某条记录全为空值——删除该记录;
某列数据空值较多——删除该列;
某列数据空值一半左右——使用均值填充;
某列数据空值三分之一左右——使用0填充;
某列数据空值极少——删除该记录
.
2.3.1 删除空行
#pandas的操作是在“数据”的副本上进行的,将inplace属性设为True,表示用副本覆盖原文件
数据.dropna(how="all",inplace=True)
print(数据)
2.3.2 统计某列空值数量
删除空行后再次查看每列中包含空值的情况,发现仅“婚姻”、“通话时长”等5列数据还包含空值,使用value_counts()统计空值数量。
print(数据.isnull().any())
print(数据["婚姻"].isnull().value_counts())
print(数据["通话时长"].isnull().value_counts())
print(数据["上门服务"].isnull().value_counts())
print(数据["无线时长"].isnull().value_counts())
print(数据["影视时长"].isnull().value_counts())
2.3.3 删除某列
“影视时长”中空值占比较大,删除该列
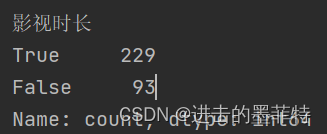
#aixs属性表示维度,其值为0时表示行,其值为1时表示列
数据.drop("影视时长",axis=1,inplace=True)
2.3.4 空值填充
对于“通话时长”、“上门服务”使用均值填充,对于“无线时长”使用0填充。
通话时长平均值 = 数据["通话时长"].mean()
数据["通话时长"].fillna(通话时长平均值,inplace=True)
上门服务平均值 = 数据["上门服务"].mean()
数据["上门服务"].fillna(上门服务平均值,inplace=True)
数据["无线时长"].fillna(0,inplace=True)
2.3.5 删除某列数据中空值对应的记录
“婚姻”中仅包含两个空值,将对应的两条记录删除。

#subset属性用于指定需要操作的列
数据.dropna(subset="婚姻",inplace=True)
2.4 重复值处理
此处“重复值”主要指表中的重复记录,也可以通过某一列中的重复值来删除对应的记录。
数据.drop_duplicates(inplace=True)
'''
#删除”婚姻“中属性值重复的对应记录
数据.drop_duplicates(subset="婚姻",inplace=True)
#“婚姻”中仅包含“已婚”、“单身”两种类型,程序运行后仅保留两条记录
print(数据)
'''
2.5 异常值处理
异常值就是不符合当前任务统计需求的值,例如“婚姻”仅包含“已婚”和“单身”两种类型,但是某条记录中出现了“离异”,则该条记录是异常的;再如“网龄”在0至100属于合理范围,若某条记录中该字段属性值为-5,则该记录也是异常。
异常值的处理类似于空值的处理,同样可以采用“均值填充”、“0填充”等方式,但本任务中并不涉及,故不处理。
2.6 保存文件
删除部分记录后,DataFrame的行索引已经混乱,可以使用reset_index()方法将其重置后再保存文件。
数据.reset_index(drop=True,inplace=True)
数据.to_excel("处理后的数据.xlsx")
print(数据)
2.7 完整代码
import pandas
数据 = pandas.read_csv("电信客户流失数据-东城区.csv")
print(数据)
print(数据.info())
print("步骤二(方法1)分隔符*********************************")
print(数据.isnull())
print("步骤二(方法2)分隔符*********************************")
print(数据.notnull())
print("步骤三分隔符*********************************")
print(数据.isnull().any())
print("步骤四分隔符*********************************")
print(数据.dropna(how="all",inplace=True))
print("步骤五分隔符*********************************")
print(数据.isnull().any())
print("***婚姻***")
print(数据["婚姻"].isnull().value_counts())
print("***通话时长***")
print(数据["通话时长"].isnull().value_counts())
print("***上门服务***")
print(数据["上门服务"].isnull().value_counts())
print("***无线时长***")
print(数据["无线时长"].isnull().value_counts())
print("***影视时长***")
print(数据["影视时长"].isnull().value_counts())
print("步骤六分隔符*********************************")
数据.drop("影视时长",axis=1,inplace=True)
通话时长平均值 = 数据["通话时长"].mean()
数据["通话时长"].fillna(通话时长平均值,inplace=True)
上门服务平均值 = 数据["上门服务"].mean()
数据["上门服务"].fillna(上门服务平均值,inplace=True)
数据["无线时长"].fillna(0,inplace=True)
数据.dropna(subset="婚姻",inplace=True)
print(数据)
print("步骤七分隔符*********************************")
print(数据.duplicated().value_counts())
数据.drop_duplicates(inplace=True)
'''
#删除”婚姻“中属性值重复的对应记录
数据.drop_duplicates(subset="婚姻",inplace=True)
#“婚姻”中仅包含“已婚”、“单身”两种类型,程序运行后仅保留两条记录
print(数据)
'''
print("步骤八分隔符*********************************")
数据.reset_index(drop=True,inplace=True)
数据.to_excel("处理后的数据.xlsx")
print(数据)
三、方法总结
数据清洗中使用到的方法大抵如下:
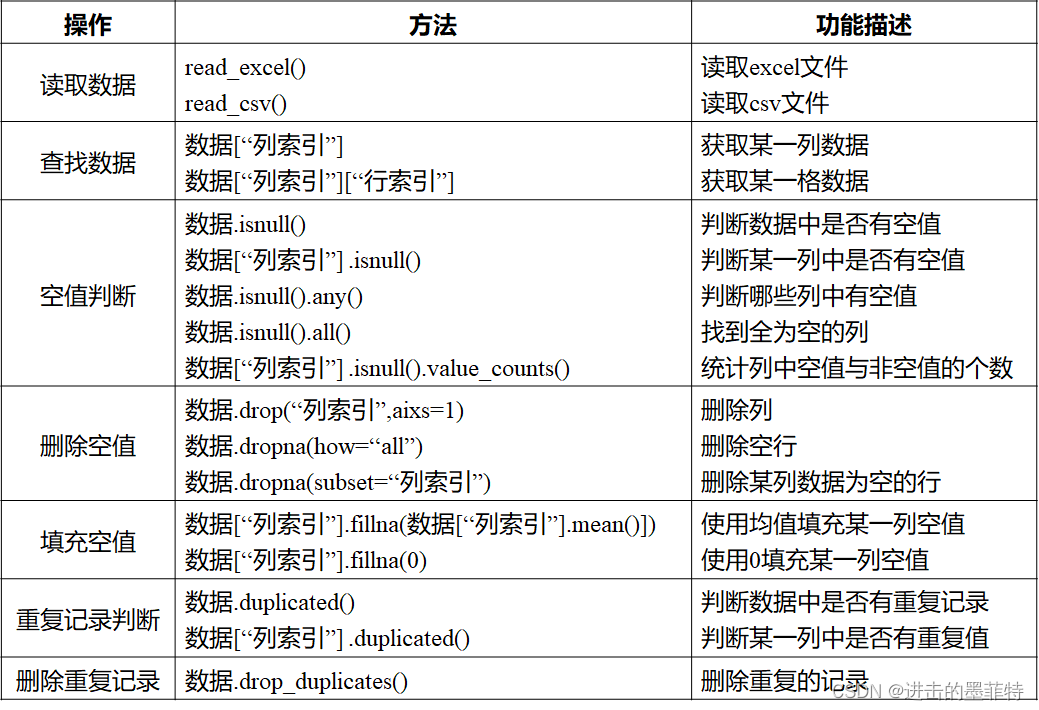
















 1287
1287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











