






Spectrum Sharing in Vehicular Networks Based on Multi-Agent Reinforcement Learning--笔记
这是我第一次尝试使用使用CSDN记笔记,并且这也是我上研究生完完整整跑通的第一个模型,研一新生,研究生生涯就此开始。
博客中的代码均为论文提供的源码
一、 论文部分
1.1 介绍
1.1.1 背景:
实现高级驾驶服务的需求增加,需要车与车之间传递安全消息,传递信息需要占用频谱资源,频谱资源是有限的,并不是所有波长的信号都可以用来进行信号传输。
这里的高级驾驶服务我的理解就是无人驾驶等,是一些辅助驾驶的应用,需要车与车之间互通一些信息(如果学过计算机网络的,大概就如同路由之间传递路由表,我个人理解)
无线传输信息需要使用信号进行传输,而信号需要有三个要素:频率、振幅、相位,区别不同的信号主要是区分信号的不同(有点绕,也就是三要素/特征不一样,就可以进行区分了),其中这个频谱资源就是指频率。
信号的波长与发射信号的天线长度成正比(天线和波长的关系),考虑到实际天线过长不现实,过短容易被遮挡,所以天线长度有一个范围,导致信号波长有范围/有限。
1.1.2论文使用方法:
频谱共享:使车与车通信(V2V,vehicle-to-vehicle)共享原来的车与基础设施通信(V2I,vehicle-to-infrastructure)的频谱资源进行通信
让V2I每一个通信通道占用一个频谱子带(将大宽马路划分成各个车道),然后让V2V通信见缝插针,找车流小的车道,塞几辆车进去。
1.1.3资源:
对频谱共享有两个问题: 1 占用哪一个 2 占用多少
所以论文中提到的资源主要有两个数据量:1 频谱子带的选择(选择一个车道) 2 发送信息功率的大小(见缝插针塞的车的个数)
为什么功率的大小决定“车”的个数,与香农定理有关。(见1.3)
1.1.4设计思路:
使每一个V2I通信固定使用一个频谱子带(因为数量相对较少,有多少辆车就有多少个V2I通信通道),让每个V2V通信规划自己需要占用哪一个频谱子带并且占用多少。
场景中的问题:
1、车辆行驶过程中,车辆的位置变化会影响信道信息(衰落信息),对资源分配造成很大的不确定性
2、尽量使V2V通信完成任务同时,减少对频谱上原有的V2I通信的影响,即同时最大化V2V和V2I的吞吐量和可靠性
衰落信息主要为快衰落和慢衰落,快衰落就是在很短时间内信号有剧烈变化,慢衰落就是短时间内看似没什么变化,但是从长时间来看还是有变化,在本论文中,快衰落的时间颗粒度为1ms,慢衰落为100ms。
针对上述问题提出本论文模型:
提出使用多代理强化学习方法
强化学习:代理(agent)在和环境(environment)的不断交互中通过学习策略达到回报最大或者实现特定目标的问题,适合不确定性较大的问题
多代理:适合实现分布式方法,相较集中式计算能更好的提升计算性能(节约通信成本、容错性强等)
1.2 模型:
多代理强化学习 𝑀𝐴𝑅𝐿(Multi-Agent Reinforcement Learning)


两类主体:代理(agent)和环境(environment)
三类数据:对环境的观察(Observation/State)、代理做出的行为(Action)和环境对行为做出的评价(Reward)
算法思路:代理做出某个行为(Action)后,对影响环境的变化(不可撤回),未来能够得到多少回报,然后通过训练最大化这些汇报。
论文中提到两种方法训练神经网络:DQN和double q-learning
(通过对每个代理记忆池中的数据组[前状态,行为,回报,后状态]进行抽样,抽取一部分进行训练)
这里和一般神经网络不一样,一般神经网络是训练让之前所有传入的数据集在当前状态下做到最优,也就是最优化之前的所有数据。强化学习是让未来传入的数据在当前状态下做到最优,也就是最优化未来的所有数据。
关于强化学习如何与环境/场景进行交互?
之前轰动一时的AlphaGo也是使用强化学习进行建模的,只不过比论文中的强化学习更复杂,但是大体差不多,对于AlphaGo来说,对手就是环境,AlphaGo进行落子后对手必然会作出反应——也落一子,这就是与环境进行交互。并且AlphaGo每做出一步反应,除了会影响对手的行为,也会影响自己后续的行为,也就是影响大局,没有悔棋,从落下第一子到最终棋局输或赢,每一步都会影响最终结果。
1.3 系统模型
论文中使用的是基于蜂窝网络的车载通信网络,在网络中具有M个V2I链路(移动的高数据速率的娱乐服务)和K个V2V链路(高级驾驶服务的定期安全信息共享)。

在这一部分中主要是现实场景抽象为模型中的数值。
其中或许让人不解的是什么是蜂窝接口(Uu),什么又是侧链路接口(PC5),以及论文中提到的蜂窝V2X架构中定义的模式4,这些都是什么,我一开始也完全不知道,毕竟是个计算鸡菜机,然后我看到了鲜枣课堂的这篇博客,跪谢枣枣
1 信道功率增益
第m个子带(由第m个V2I链路占用)上第k个V2V链路的信道功率增益
![]()
其中![]() 是与频率相关的小尺度衰落(快衰落)功率分量,假设其与单位平均值呈指数分布;
是与频率相关的小尺度衰落(快衰落)功率分量,假设其与单位平均值呈指数分布;![]() 则是包括了路径损失和阴影衰落在内的大尺度衰落(慢衰落),假定其与频率无关。
则是包括了路径损失和阴影衰落在内的大尺度衰落(慢衰落),假定其与频率无关。
一些同样是信道功率增益,但下角标不同的增益对应如下图所示
本图中实线表示对于接收机来讲为信息链路,虚线表示对于接收机来讲为干扰线路
这里大概解释一下各个增益表示的含义:所有解释的前提都是所有通信都使用了第m个信道,g<k’,k>[m]表示的为本来是第k’的V2V通信,也就是k’的发送机是要发送k’th V2V的信息给k’的接收机,但是我们都知道,无线信号不是有线信号传输的目的性很强,指哪打哪,指哪发给哪,比如你和你女朋友说话,你想只让你女朋友听见,但是没办法,周围的人都会听到(并且吃了一嘴狗粮),所以别的V2V链路的车辆接收机也会收到这个信号,就比如说回这个g<k’,k>[m],就是k的接收机收到了k’的发射机发送的信号,本来k的接收机是不想收到的,所以这是噪声(狗粮就是噪声,噪声!);g<k>[m]就是k的发送机发给k的接收机的信号,这个显然不是噪声了;g<k,B>[m]同理,本来是k的发射机发给k的接收机的信号,但是基站也收到了,对于基站而言,它接收V2V通信的信息没有用,所以这个也是噪声,有的人会觉得,欸,不是有V2I通信吗,这个g<k,B>[m]不是k车的V2I通信吗,大错特错,再强调一下,能收到并且认为这个是噪声,是对于下面即将说的∧g<m,B>[m],人家才是信道m的主人,k的发射车也会进行V2I通信,但是它有自己的信道k(k≠m),所以这个g<k,B>[m]一定是原本的V2V通信只不过不小心发给B了所以叫g<k,B>[m];对于这个∧g<m,B>[m]就是m信道的主人,因为本来也是V2V共享原本分配给V2I的信道嘛,所以人家不是噪声;∧g<m,k>[m]同理,本来V2I的信息,结果让k的接收机收到了,这个信息对它没有意义,所以是噪声。
下面是另一种示意的图,加粗的线是它传输的本意,并不是指它信号强哈




2 信噪比
第m个频谱子带上第m个V2I链路的信噪比

第m个频谱子带上第k个V2V链路的信噪比


对于噪声的解释
论文中涉及的噪声都是电阻性元器件中的电子的热运动而产生的,是热噪声,又称为白噪声,大量自由电子的运动特性服从高斯分布,因此又称为高斯白噪声。
3 链路容量
容量一般有两种表示方式,两种度量单位。一种是每个符号能够传输的平均信息量的最大值;一种是用单位时间(s)内能够传输的平均信息量最大值。论文中选用的是第二种。
此处使用香农公式,由信噪功率比得出容量

这里就涉及一个问题,就是此消彼长问题,很明显,V2V链路和V2I是一种竞争关系,他们竞争的对象就是信道容量,那么这个此消彼长是怎么实现的呢,就是通过信噪比实现的

观察上面两个图不知道能不能发现,同样一个信号(拿虚线为例,虚线是V2I通信),在第一个图它是信号,但是到了第二个图,它就变成了噪声,同样V2V通信也是如此,所以就有了下面的图,这里以V2V的传输功率加大,那相应的V2V的容量会增加,V2I的容量会减少

这里为了弄明白我也写了一个博客,我是个计算机人,所以对于通信方向的信号和香农公式有点一知半解,所以这篇博客可能还有很多错处,欢迎大家进去讨论挑错,主要是挑错,我也可能会时不时补充一点,改一点。
二、 算法流程
将场景中的V2V信道、V2I信道、车和环境抽象为数据类型。V2V和V2I信道中主要有发送方和接收方的天线、基础设施位置(街区正中间)、通信功率等属性的初始化以及计算慢衰落(路径损失和阴影衰落)的方法;车类中设置车的属性:位置、速度、方向、邻居&通信方;环境类中则存在大量在强化学习过程中代理与环境进行交互时对环境进行的操作。
# 在Environment_marl.py中将主体抽象成类
class V2Vchannels:
# Simulator of the V2V Channels
def __init__(self):
self.t = 0
self.h_bs = 1.5
self.h_ms = 1.5
self.fc = 2
self.decorrelation_distance = 10
self.shadow_std = 3
def get_path_loss(self, position_A, position_B):
d1 = abs(position_A[0] - position_B[0])
d2 = abs(position_A[1] - position_B[1])
d = math.hypot(d1, d2) + 0.001
d_bp = 4 * (self.h_bs - 1) * (self.h_ms - 1) * self.fc * (10 ** 9) / (3 * 10 ** 8)
def PL_Los(d):
if d <= 3:
return 22.7 * np.log10(3) + 41 + 20 * np.log10(self.fc / 5)
else:
if d < d_bp:
return 22.7 * np.log10(d) + 41 + 20 * np.log10(self.fc / 5)
else:
return 40.0 * np.log10(d) + 9.45 - 17.3 * np.log10(self.h_bs) - 17.3 * np.log10(self.h_ms) + 2.7 * np.log10(self.fc / 5)
def PL_NLos(d_a, d_b):
n_j = max(2.8 - 0.0024 * d_b, 1.84)
return PL_Los(d_a) + 20 - 12.5 * n_j + 10 * n_j * np.log10(d_b) + 3 * np.log10(self.fc / 5)
if min(d1, d2) < 7:
PL = PL_Los(d)
else:
PL = min(PL_NLos(d1, d2), PL_NLos(d2, d1))
return PL # + self.shadow_std * np.random.normal()
def get_shadowing(self, delta_distance, shadowing):
return np.exp(-1 * (delta_distance / self.decorrelation_distance)) * shadowing \
+ math.sqrt(1 - np.exp(-2 * (delta_distance / self.decorrelation_distance))) * np.random.normal(0, 3) # standard dev is 3 db
class V2Ichannels:
# Simulator of the V2I channels
def __init__(self):
self.h_bs = 25
self.h_ms = 1.5
self.Decorrelation_distance = 50
self.BS_position = [750 / 2, 1299 / 2] # center of the grids
self.shadow_std = 8
def get_path_loss(self, position_A):
d1 = abs(position_A[0] - self.BS_position[0])
d2 = abs(position_A[1] - self.BS_position[1])
distance = math.hypot(d1, d2)
return 128.1 + 37.6 * np.log10(math.sqrt(distance ** 2 + (self.h_bs - self.h_ms) ** 2) / 1000) # + self.shadow_std * np.random.normal()
def get_shadowing(self, delta_distance, shadowing):
nVeh = len(shadowing)
self.R = np.sqrt(0.5 * np.ones([nVeh, nVeh]) + 0.5 * np.identity(nVeh))
return np.multiply(np.exp(-1 * (delta_distance / self.Decorrelation_distance)), shadowing) \
+ np.sqrt(1 - np.exp(-2 * (delta_distance / self.Decorrelation_distance))) * np.random.normal(0, 8, nVeh)
class Vehicle:
# Vehicle simulator: include all the information for a vehicle
def __init__(self, start_position, start_direction, velocity):
self.position = start_position
self.direction = start_direction
self.velocity = velocity
self.neighbors = []
self.destinations = []
算法流程如下:初始化、训练、测试

2.1 初始化
在实验中首先设置了模型应用的场景,也就是街区,按照3GPP TR 36.885(Technical Specification Group Radio Access Network; Study LTE-Based V2X Services; (Release 14), document 3GPP TR 36.885 V14.0.0, 3rd Generation Partnership Project, Jun. 2016.)附件A中为城市案例定义的评估方法定制了我们的模拟器,该方法详细描述了车辆跌落模型、密度、速度、移动方向、车辆通道、V2V数据流量等。M个V2I链路由M个车辆启动,每个车辆与其周围邻居之间形成K个V2V链路。

2.1.1设定地图数据,初始化车辆信息和邻居关系
地图信息使用的是3GPP TR 36.885中规定的街区地图:

其中每一个街区块如下图所示:

但是在仿真实验中,统一将地图缩小为原来的1/2。同时初始化车辆数为4n辆(n=1,2,…),初始每辆车默认有邻居k辆车(k<=4n-1),即V2I通信有4n个,V2V通信有4n*k个。
# main_marl_train.py中初始化地图大小以及车道在地图上的位置
up_lanes = [i/2.0 for i in # i/2.0表示仿真实验地图等比例缩小到原来的1/2
[3.5/2, 3.5/2 + 3.5, # 3.5车道宽度 3.5/2表示车在路中间行驶
250+3.5/2, 250+3.5+3.5/2, # 250一个街区的宽度
500+3.5/2, 500+3.5+3.5/2]]
down_lanes = [i/2.0 for i in
[250-3.5-3.5/2, 250-3.5/2,
500-3.5-3.5/2, 500-3.5/2,
750-3.5-3.5/2, 750-3.5/2]]
left_lanes = [i/2.0 for i in [3.5/2, 3.5/2 + 3.5,
433+3.5/2, 433+3.5+3.5/2,
866+3.5/2, 866+3.5+3.5/2]]
right_lanes = [i/2.0 for i in [433-3.5-3.5/2, 433-3.5/2,
866-3.5-3.5/2, 866-3.5/2,
1299-3.5-3.5/2,
1299-3.5/2]]
width = 750/2 # 等比例缩小
height = 1298/2
# 车辆数,邻居数,V2I信道数=车辆数(实验设置车辆数4n n=1,邻居数k=1)
n_veh = 4
n_neighbor = 1
n_RB = n_veh
# 初始化环境
env = Environment_marl.Environ(down_lanes, up_lanes, left_lanes, right_lanes, width, height, n_veh, n_neighbor)
# Environment_marl.py中初始化环境的代码部分
class Environ:
def __init__(self, down_lane, up_lane, left_lane, right_lane, width, height, n_veh, n_neighbor):
self.down_lanes = down_lane
self.up_lanes = up_lane
self.left_lanes = left_lane
self.right_lanes = right_lane
self.width = width
self.height = height
self.V2Vchannels = V2Vchannels()
self.V2Ichannels = V2Ichannels()
self.vehicles = []
self.demand = []
self.V2V_Shadowing = []
self.V2I_Shadowing = []
self.delta_distance = []
self.V2V_channels_abs = []
self.V2I_channels_abs = []
self.V2I_power_dB = 23 # dBm
self.V2V_power_dB_List = [23, 15, 5, -100] # the power levels
self.sig2_dB = -114
self.bsAntGain = 8
self.bsNoiseFigure = 5
self.vehAntGain = 3
self.vehNoiseFigure = 9
self.sig2 = 10 ** (self.sig2_dB / 10)
self.n_RB = n_veh
self.n_Veh = n_veh
self.n_neighbor = n_neighbor
self.time_fast = 0.001
self.time_slow = 0.1 # update slow fading/vehicle position every 100 ms
self.bandwidth = int(1e6) # bandwidth per RB, 1 MHz
# self.bandwidth = 1500
self.demand_size = int((4 * 190 + 300) * 8 * 2) # V2V payload: 1060 Bytes every 100 ms
# self.demand_size = 20
self.V2V_Interference_all = np.zeros((self.n_Veh, self.n_neighbor, self.n_RB)) + self.sig2
相关参数见下图(论文中给出)


2.1.2 初始化车辆位置
一辆车有4个属性:车辆位置横坐标,车辆位置纵坐标,车辆初始方向(每个方向车数相同为n,这也就是为什么车辆数要是4n),速度(随机10~15m/s)。
随机选择6种初始形态(下图,即选中四个方向列表中各自的第一个组成一种情况,各自的第二个组成一种情况…)的1个,再选中后,方向和其中一个坐标确定(横/纵),另一个坐标在不超出图边界情况下随机生成(纵/横)。
在生成车辆信息后,通信模型中的衰落可以根据上表TABLEⅡ进行初始化。

2.1.3 更新邻居关系
有了车辆的位置信息,进而可以确定需要进行V2V通信的邻居是哪一/几辆车。
在仿真实验中,设置的邻居数k=1,所以找出与当前车辆距离最近的一辆车作为V2V通信的对象。

在实验中设置为每辆车只有一个离他最近的车邻居进行V2V通信,邻居的位置将会和本车位置一同影响慢衰落中的阴影衰落
2.1.4 更新信道衰落信息
无线通信信道是一种时变信道,无线电信号通过信道时会遭受来自不同途径的衰落,接收信号总功率表现为路径损失,阴影衰落,多径效应三种效应的综合。
多径传播:电波遇到各种障碍物时会发生反射、绕射和散射现象,会对直射波形成干涉,也就是收发信机之间是有多条路径传播的。
1.路径损失:大范围内信号强度随距离变化(数百或数千个波长),应该是与距离的平方成正比,本质上表现为电波能量扩散现象。
2.阴影衰落:中范围信号电平中值慢变(数百个波长),由于传播环境中的地形起伏、建筑物及其他障碍物对电波遮蔽所引起的慢衰落,信号中值出现缓慢变动,衰落深度与频率、阻碍物有关。
3.多径效应(衰落):小范围信号瞬时值快变(数十个波长),由于多径传播引起的快衰落,接收信号场强的瞬时值呈现快速变化。
大尺度衰落:
(包括传输损失、阴影衰落;大尺度衰落都是慢衰落,但是慢衰落不一定是大尺度衰落。)
传输损失(路径损失):无线电信号通过大尺度距离的信道传输时,随传输路径的增加,电波能量扩散,导致接收信号平均功率衰减,其衰减量与传输距离有关,距离越大,衰减量越多。
阴影衰落:无线电信号在中尺度距离的信道中传输时,由于地形起伏或高大建筑物群等障碍物遮挡,在阻碍物的背后形成阴影区,导致接收信号平均功率随机变化。其衰落特性服从对数正态分布。
小尺度衰落:
(由多径效应或多普勒效应引起。当传输信道小尺度(距离或时间)变化时,无线电信号在传输过程中受周围阻碍物反射、绕射和散射,其幅度或相位快速变化。)
依据多径效应产生的时延扩展:
将小尺度衰落划分为频率选择性衰落(信道具有恒定增益且线性相位的带宽范围小于发送信号带宽)和频率非选择性/平坦衰落(无线信道带宽大于发送信号的带宽,且在带宽范围内有恒定增益和线性相位);
依据多普勒效应产生的多普勒(频域)扩展:
将小尺度衰落划分为快衰落(信道的相干时间比发送信号的周期短,且基带信号的带宽小于多普勒扩展)和慢衰落(信道上的相干时间远远大于发送信号的周期,且基带信号的带宽远远大于多普勒扩展)。
上述来自Luminosity_azur
在论文中,快衰落(符号时间T>>Tc):1ms更新一次,服从瑞利衰落(参考1 参考2 参考3);慢衰落(符号时间T<Tc):100ms更新一次,其中包含路径损失和阴影衰落(Tc:传输信号的周期)
路径损失(曼哈顿网格布局):计算两车辆出横纵坐标分别的差(|x1-x2|和|y1-y2|),如果其中至少一个绝对值<7m,则认为为无遮挡通信,否则认为是有遮挡通信。
阴影衰落(对数正态分布):

# main_marl_train.py 中的入口
env.new_random_game() # initialize parameters in env
# Environment_marl.py中类Environ中的方法
class Environ:
# 开始新的场景
def new_random_game(self, n_Veh=0):
# make a new game
self.vehicles = []
if n_Veh > 0:
self.n_Veh = n_Veh
self.add_new_vehicles_by_number(int(self.n_Veh / 4)) # 初始化车辆位置
self.renew_neighbor() # 更新邻居关系
self.renew_channel() # 更新慢衰落
self.renew_channels_fastfading() # 计算衰落总和(附上快衰落后)
# 初始化V2V传输数据包的大小以及时限
self.demand = self.demand_size * np.ones((self.n_Veh, self.n_neighbor))
self.individual_time_limit = self.time_slow * np.ones((self.n_Veh, self.n_neighbor))
# 活跃的链接,也就是某通信任务还没完成则为1,数据包都传完了为0,用来计算V2V成功率,成功率=(最后active_links里为0的项的个数)/(V2V通信总数)
self.active_links = np.ones((self.n_Veh, self.n_neighbor), dtype='bool')
# 进行对比试验的随机基线方法的初始化
# random baseline
self.demand_rand = self.demand_size * np.ones((self.n_Veh, self.n_neighbor))
self.individual_time_limit_rand = self.time_slow * np.ones((self.n_Veh, self.n_neighbor))
self.active_links_rand = np.ones((self.n_Veh, self.n_neighbor), dtype='bool')
# 初始化车辆位置
def add_new_vehicles(self, start_position, start_direction, start_velocity):
self.vehicles.append(Vehicle(start_position, start_direction, start_velocity))
def add_new_vehicles_by_number(self, n):
for i in range(n):
ind = np.random.randint(0, len(self.down_lanes))
start_position = [self.down_lanes[ind], np.random.randint(0, self.height)]
start_direction = 'd' # velocity: 10 ~ 15 m/s, random
self.add_new_vehicles(start_position, start_direction, np.random.randint(10, 15))
start_position = [self.up_lanes[ind], np.random.randint(0, self.height)]
start_direction = 'u'
self.add_new_vehicles(start_position, start_direction, np.random.randint(10, 15))
start_position = [np.random.randint(0, self.width), self.left_lanes[ind]]
start_direction = 'l'
self.add_new_vehicles(start_position, start_direction, np.random.randint(10, 15))
start_position = [np.random.randint(0, self.width), self.right_lanes[ind]]
start_direction = 'r'
self.add_new_vehicles(start_position, start_direction, np.random.randint(10, 15))
# initialize channels
self.V2V_Shadowing = np.random.normal(0, 3, [len(self.vehicles), len(self.vehicles)])
self.V2I_Shadowing = np.random.normal(0, 8, len(self.vehicles))
self.delta_distance = np.asarray([c.velocity*self.time_slow for c in self.vehicles])
# 更新邻居关系
def renew_neighbor(self):
""" Determine the neighbors of each vehicles """
for i in range(len(self.vehicles)):
self.vehicles[i].neighbors = []
self.vehicles[i].actions = []
z = np.array([[complex(c.position[0], c.position[1]) for c in self.vehicles]])
t = z.T - z
Distance = abs(z.T - z)
for i in range(len(self.vehicles)):
sort_idx = np.argsort(Distance[:, i])
for j in range(self.n_neighbor):
self.vehicles[i].neighbors.append(sort_idx[j + 1])
destination = self.vehicles[i].neighbors
self.vehicles[i].destinations = destination
# 更新衰落
def renew_channel(self):
""" Renew slow fading channel """
self.V2V_pathloss = np.zeros((len(self.vehicles), len(self.vehicles))) + 50 * np.identity(len(self.vehicles))
self.V2I_pathloss = np.zeros((len(self.vehicles)))
self.V2V_channels_abs = np.zeros((len(self.vehicles), len(self.vehicles)))
self.V2I_channels_abs = np.zeros((len(self.vehicles)))
for i in range(len(self.vehicles)):
for j in range(i + 1, len(self.vehicles)):
self.V2V_Shadowing[j][i] = self.V2V_Shadowing[i][j] = self.V2Vchannels.get_shadowing(self.delta_distance[i] + self.delta_distance[j], self.V2V_Shadowing[i][j])
self.V2V_pathloss[j,i] = self.V2V_pathloss[i][j] = self.V2Vchannels.get_path_loss(self.vehicles[i].position, self.vehicles[j].position)
self.V2V_channels_abs = self.V2V_pathloss + self.V2V_Shadowing
self.V2I_Shadowing = self.V2Ichannels.get_shadowing(self.delta_distance, self.V2I_Shadowing)
for i in range(len(self.vehicles)):
self.V2I_pathloss[i] = self.V2Ichannels.get_path_loss(self.vehicles[i].position)
self.V2I_channels_abs = self.V2I_pathloss + self.V2I_Shadowing
def renew_channels_fastfading(self):
""" Renew fast fading channel """
V2V_channels_with_fastfading = np.repeat(self.V2V_channels_abs[:, :, np.newaxis], self.n_RB, axis=2)
self.V2V_channels_with_fastfading = V2V_channels_with_fastfading - 20 * np.log10(
np.abs(np.random.normal(0, 1, V2V_channels_with_fastfading.shape)
+ 1j * np.random.normal(0, 1, V2V_channels_with_fastfading.shape)) / math.sqrt(2))
V2I_channels_with_fastfading = np.repeat(self.V2I_channels_abs[:, np.newaxis], self.n_RB, axis=1)
self.V2I_channels_with_fastfading = V2I_channels_with_fastfading - 20 * np.log10(
np.abs(np.random.normal(0, 1, V2I_channels_with_fastfading.shape)
+ 1j * np.random.normal(0, 1, V2I_channels_with_fastfading.shape))/ math.sqrt(2))
2.2 训练train
首先罗列一下我画的流程图与论文伪代码以及源码中的代码之间的区别(相对应的位置标记为相同颜色):

区别1(红色部分):源码中对于车辆位置、邻居、衰落信息的更新包含在if i_episode % 100 == 0:,而伪代码中没有体现(流程图我自己画的,就不讲了),对此我进行猜测,对同一慢衰落作为大背景下,多训练几次(100次),提高模型准确度,即两个层次(1、对不同慢衰落进行训练 2、对相同慢衰落的不同的100个快衰落随机组合进行训练)
区别2(绿色部分):源码中对于记忆池中保存的数据组的更新(循环队列),在每一步(1ms)进行一次,训练数据也每一步(1ms)训练一次,从中抽样。而并非如伪代码所展现的一次迭代(100ms)训练一次
再梳理一下时间颗粒度,以伪代码为参照,红橘蓝绿框组合起来的整体,计算单位为一个慢衰落时间100ms,蓝色框中for循环内,计算单位为一个快衰落时间1ms.
# mian_marl_train.py 文件中
# ------------------------- Training -----------------------------
record_reward = np.zeros([n_episode*n_step_per_episode, 1])
record_loss = []
if IS_TRAIN:
for i_episode in range(n_episode):
print("-------------------------")
print('Episode:', i_episode)
if i_episode < epsi_anneal_length:
epsi = 1 - i_episode * (1 - epsi_final) / (epsi_anneal_length - 1) # epsilon decreases over each episode
else:
epsi = epsi_final
# 2.2.1 部分
if i_episode%100 == 0:
env.renew_positions() # update vehicle position
env.renew_neighbor()
env.renew_channel() # update channel slow fading
env.renew_channels_fastfading() # update channel fast fading
# 我觉得应该去掉if i_episode%100 == 0,直接
# env.renew_positions() # update vehicle position
# env.renew_neighbor()
# env.renew_channel() # update channel slow fading
# env.renew_channels_fastfading() # update channel fast fading
#最新想法:或许是同一种慢衰落情况下多训练几次使算法尽量多学多改善
# 2.2.2 部分
env.demand = env.demand_size * np.ones((env.n_Veh, env.n_neighbor))
env.individual_time_limit = env.time_slow * np.ones((env.n_Veh, env.n_neighbor))
env.active_links = np.ones((env.n_Veh, env.n_neighbor), dtype='bool')
# 2.2.3 部分
for i_step in range(n_step_per_episode):
time_step = i_episode*n_step_per_episode + i_step
state_old_all = []
action_all = []
action_all_training = np.zeros([n_veh, n_neighbor, 2], dtype='int32')
for i in range(n_veh):
for j in range(n_neighbor):
state = get_state(env, [i, j], i_episode/(n_episode-1), epsi)
state_old_all.append(state)
action = predict(sesses[i*n_neighbor+j], state, epsi)
action_all.append(action)
action_all_training[i, j, 0] = action % n_RB # chosen RB
action_all_training[i, j, 1] = int(np.floor(action / n_RB)) # power level
# All agents take actions simultaneously, obtain shared reward, and update the environment.
action_temp = action_all_training.copy()
train_reward = env.act_for_training(action_temp)
record_reward[time_step] = train_reward
env.renew_channels_fastfading()
env.Compute_Interference(action_temp)
for i in range(n_veh):
for j in range(n_neighbor):
state_old = state_old_all[n_neighbor * i + j]
action = action_all[n_neighbor * i + j]
state_new = get_state(env, [i, j], i_episode/(n_episode-1), epsi)
agents[i * n_neighbor + j].memory.add(state_old, state_new, train_reward, action) # add entry to this agent's memory
# 2.2.4 部分 training this agent
if time_step % mini_batch_step == mini_batch_step-1:
loss_val_batch = q_learning_mini_batch(agents[i*n_neighbor+j], sesses[i*n_neighbor+j])
record_loss.append(loss_val_batch)
if i == 0 and j == 0:
print('step:', time_step, 'agent',i*n_neighbor+j, 'loss', loss_val_batch)
if time_step % target_update_step == target_update_step-1:
update_target_q_network(sesses[i*n_neighbor+j])
if i == 0 and j == 0:
print('Update target Q network...')
print('Training Done. Saving models...')
for i in range(n_veh):
for j in range(n_neighbor):
model_path = label + '/agent_' + str(i * n_neighbor + j)
save_models(sesses[i * n_neighbor + j], model_path)
current_dir = os.path.dirname(os.path.realpath(__file__))
reward_path = os.path.join(current_dir, "model/" + label + '/reward.mat')
scipy.io.savemat(reward_path, {'reward': record_reward})
record_loss = np.asarray(record_loss).reshape((-1, n_veh*n_neighbor))
loss_path = os.path.join(current_dir, "model/" + label + '/train_loss.mat')
scipy.io.savemat(loss_path, {'train_loss': record_loss})
2.2.1 更新车辆位置、邻居、衰落信息(快慢衰落)
训练过程部分

这一部分计算的部分主要集中在环境

更新车辆位置:
考虑到实际情况,车辆并不是顺着一条直线一直开下去,所以模型考虑了转弯问题,当车辆当前位置加上下一个慢衰落时间会移动的![]() 会跨过一个路口,那么车辆会有一定概率进行转弯,向左向右转弯概率均为0.4,继续直行的概率为0.2。对于车辆行驶还有一个问题,就是当车辆下一刻即将超出地图范围如何处理,模型给出的处理是,一律顺时针转弯。
会跨过一个路口,那么车辆会有一定概率进行转弯,向左向右转弯概率均为0.4,继续直行的概率为0.2。对于车辆行驶还有一个问题,就是当车辆下一刻即将超出地图范围如何处理,模型给出的处理是,一律顺时针转弯。

更新邻居:
随着车辆位置的改变,距离发送方车辆最近的一个(或几个)车辆会发生变化,通信的对象相应的也要发生变化。
更新衰落信息:
更新衰落信息:快衰落变化快,几乎时时在发生变化;慢衰落随着两车的位移会分别改变阴影衰落(移动距离影响)和路径损失(相对位置影响),所以在更新过车辆位置后就需要进行一次计算
# Environment_marl.py中
class Environ:
# 更新车辆位置
def renew_positions(self):
# ===============
# This function updates the position of each vehicle
# ===============
i = 0
while (i < len(self.vehicles)):
delta_distance = self.vehicles[i].velocity * self.time_slow
change_direction = False
if self.vehicles[i].direction == 'u':
# print ('len of position', len(self.position), i)
for j in range(len(self.left_lanes)):
if (self.vehicles[i].position[1] <= self.left_lanes[j]) and ((self.vehicles[i].position[1] + delta_distance) >= self.left_lanes[j]): # came to an cross
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.vehicles[i].position[0] - (delta_distance - (self.left_lanes[j] - self.vehicles[i].position[1])), self.left_lanes[j]]
self.vehicles[i].direction = 'l'
change_direction = True
break
if change_direction == False:
for j in range(len(self.right_lanes)):
if (self.vehicles[i].position[1] <= self.right_lanes[j]) and ((self.vehicles[i].position[1] + delta_distance) >= self.right_lanes[j]):
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.vehicles[i].position[0] + (delta_distance + (self.right_lanes[j] - self.vehicles[i].position[1])), self.right_lanes[j]]
self.vehicles[i].direction = 'r'
change_direction = True
break
if change_direction == False:
self.vehicles[i].position[1] += delta_distance
if (self.vehicles[i].direction == 'd') and (change_direction == False):
# print ('len of position', len(self.position), i)
for j in range(len(self.left_lanes)):
if (self.vehicles[i].position[1] >= self.left_lanes[j]) and ((self.vehicles[i].position[1] - delta_distance) <= self.left_lanes[j]): # came to an cross
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.vehicles[i].position[0] - (delta_distance - (self.vehicles[i].position[1] - self.left_lanes[j])), self.left_lanes[j]]
# print ('down with left', self.vehicles[i].position)
self.vehicles[i].direction = 'l'
change_direction = True
break
if change_direction == False:
for j in range(len(self.right_lanes)):
if (self.vehicles[i].position[1] >= self.right_lanes[j]) and (self.vehicles[i].position[1] - delta_distance <= self.right_lanes[j]):
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.vehicles[i].position[0] + (delta_distance + (self.vehicles[i].position[1] - self.right_lanes[j])), self.right_lanes[j]]
# print ('down with right', self.vehicles[i].position)
self.vehicles[i].direction = 'r'
change_direction = True
break
if change_direction == False:
self.vehicles[i].position[1] -= delta_distance
if (self.vehicles[i].direction == 'r') and (change_direction == False):
# print ('len of position', len(self.position), i)
for j in range(len(self.up_lanes)):
if (self.vehicles[i].position[0] <= self.up_lanes[j]) and ((self.vehicles[i].position[0] + delta_distance) >= self.up_lanes[j]): # came to an cross
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.up_lanes[j], self.vehicles[i].position[1] + (delta_distance - (self.up_lanes[j] - self.vehicles[i].position[0]))]
change_direction = True
self.vehicles[i].direction = 'u'
break
if change_direction == False:
for j in range(len(self.down_lanes)):
if (self.vehicles[i].position[0] <= self.down_lanes[j]) and ((self.vehicles[i].position[0] + delta_distance) >= self.down_lanes[j]):
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.down_lanes[j], self.vehicles[i].position[1] - (delta_distance - (self.down_lanes[j] - self.vehicles[i].position[0]))]
change_direction = True
self.vehicles[i].direction = 'd'
break
if change_direction == False:
self.vehicles[i].position[0] += delta_distance
if (self.vehicles[i].direction == 'l') and (change_direction == False):
for j in range(len(self.up_lanes)):
if (self.vehicles[i].position[0] >= self.up_lanes[j]) and ((self.vehicles[i].position[0] - delta_distance) <= self.up_lanes[j]): # came to an cross
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.up_lanes[j], self.vehicles[i].position[1] + (delta_distance - (self.vehicles[i].position[0] - self.up_lanes[j]))]
change_direction = True
self.vehicles[i].direction = 'u'
break
if change_direction == False:
for j in range(len(self.down_lanes)):
if (self.vehicles[i].position[0] >= self.down_lanes[j]) and ((self.vehicles[i].position[0] - delta_distance) <= self.down_lanes[j]):
if (np.random.uniform(0, 1) < 0.4):
self.vehicles[i].position = [self.down_lanes[j], self.vehicles[i].position[1] - (delta_distance - (self.vehicles[i].position[0] - self.down_lanes[j]))]
change_direction = True
self.vehicles[i].direction = 'd'
break
if change_direction == False:
self.vehicles[i].position[0] -= delta_distance
# if it comes to an exit
if (self.vehicles[i].position[0] < 0) \
or (self.vehicles[i].position[1] < 0) \
or (self.vehicles[i].position[0] > self.width) \
or (self.vehicles[i].position[1] > self.height):
# delete
# print ('delete ', self.position[i])
if (self.vehicles[i].direction == 'u'):
self.vehicles[i].direction = 'r'
self.vehicles[i].position = [self.vehicles[i].position[0], self.right_lanes[-1]]
else:
if (self.vehicles[i].direction == 'd'):
self.vehicles[i].direction = 'l'
self.vehicles[i].position = [self.vehicles[i].position[0], self.left_lanes[0]]
else:
if (self.vehicles[i].direction == 'l'):
self.vehicles[i].direction = 'u'
self.vehicles[i].position = [self.up_lanes[0], self.vehicles[i].position[1]]
else:
if (self.vehicles[i].direction == 'r'):
self.vehicles[i].direction = 'd'
self.vehicles[i].position = [self.down_lanes[-1], self.vehicles[i].position[1]]
i += 1
# 之前提到
# 更新邻居 def renew_neighbor(self)
# 更新慢衰落 def renew_channel(self)
# 更新快衰落 def renew_channels_fastfading(self)
2.2.2 初始化传输信息量、时限、待传输的V2V通信
训练过程部分

这一部分计算的部分主要集中在环境
信息量在训练过程中固定一个V2V通信在一个慢衰落中需要传输2 × 1060B的数据(但在测试过程中数据大小随机n×1060B)
时限为一个慢衰落(100ms),大循环时间颗粒度为一个慢衰落时间(100ms)
待传输的V2V通信为全1矩阵(数据维度:车辆数*邻居数 的矩阵),主要是用于计算V2V_success
信息量和时限表明V2V传输的安全信息具有时效性,在规定时限内传输完需要传输的所有数据视为此V2V通信传输成功,成功后此通信在本时限内不需要再传输安全信息,所以待传输矩阵中相应位置置为0,时限结束后统计成功率时统计所有位置为0的个数,除以总通信条数,作为最后的成功率
2.2.3 分步计算部分(重复100次)
此部分为流程图、伪代码和源码比较部分的蓝框部分,内容比较多,此部分不截图了。
这一部分计算集中在观察值、行为和代理中

对于环境的观测值(![]() )作为神经网络的输入数据,经过神经网络的权重计算,得出代理需要做出的行为(
)作为神经网络的输入数据,经过神经网络的权重计算,得出代理需要做出的行为(![]() ),在环境对代理做出的行为进行反应后,得到新的环境观测值(
),在环境对代理做出的行为进行反应后,得到新的环境观测值(![]() )并且环境还对此次行为做出了反馈(
)并且环境还对此次行为做出了反馈(![]() )。
)。
重复100步:慢衰落时间内进行100次快衰落(1ms)计算,即更新慢衰落时长/更新快衰落时长
代理:获得环境的状态𝑍𝑡

更新快衰落:小循环时间颗粒度为一个快衰落时间(1ms)
存入记忆池:将数据组![]() 存入记忆池留作后续抽样对代理(神经网络)进行训练。
存入记忆池留作后续抽样对代理(神经网络)进行训练。
2.2.4 训练神经网络DQN&double DQN
论文中提到两种方法训练神经网络:DQN(deep Q-learning)和double DQN
(通过对每个代理记忆池中的数据组[前状态,行为,回报,后状态]进行抽样,抽取一部分进行训练)
强化学习关于Q-learning的问题详见 此篇文章
2.3 测试test
测试部分大体与训练部分相似,区别就是训练的目标是通过数据进行模型的训练,而测试部分则是通过数据和模型得出几个数据来对不同的算法性能进行对比,同时观察是否达到最初计划的性能等。

在Environment_marl.py中主要进行对比的就是随机基线方法和MARL的对比,在作者的论文给出的源码中还给出了相同团队之前论文SARL的源码,SARL也是论文中进行性能对比的方法之一。
测试部分主要计算三个评价标准:V2I容量、V2V容量和V2V成功率,其中主要观察V2I容量和V2V成功率
因为之前提到在本应用场景中存在的主要难题有
1、车辆行驶工程中,车辆的位置变化会影响信道信息(衰落信息),对资源分配造成很大的不确定性
2、尽量使V2V通信完成任务同时,减少对频谱上原有的V2I通信的影响,即同时最大化V2V和V2I的吞吐量和可靠性
其中
V2I容量→V2I吞吐量
V2V成功率→V2V可靠性
2.3.1 V2V成功率
总结如何计算出V2V成功率
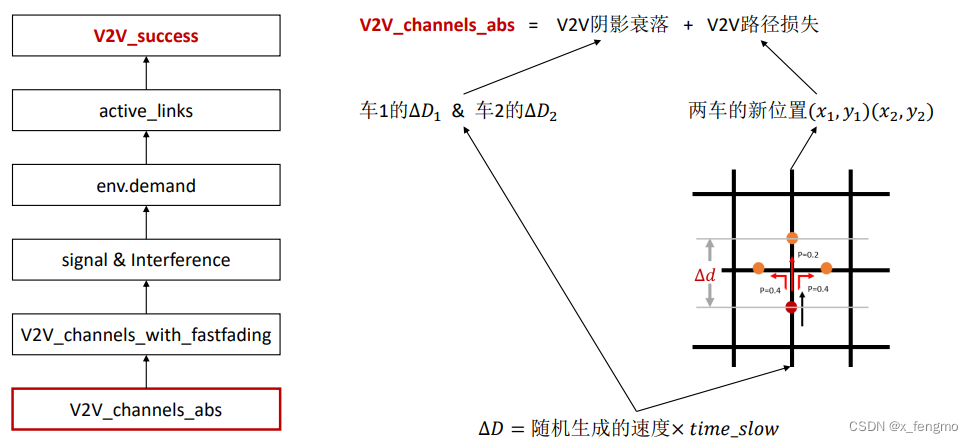
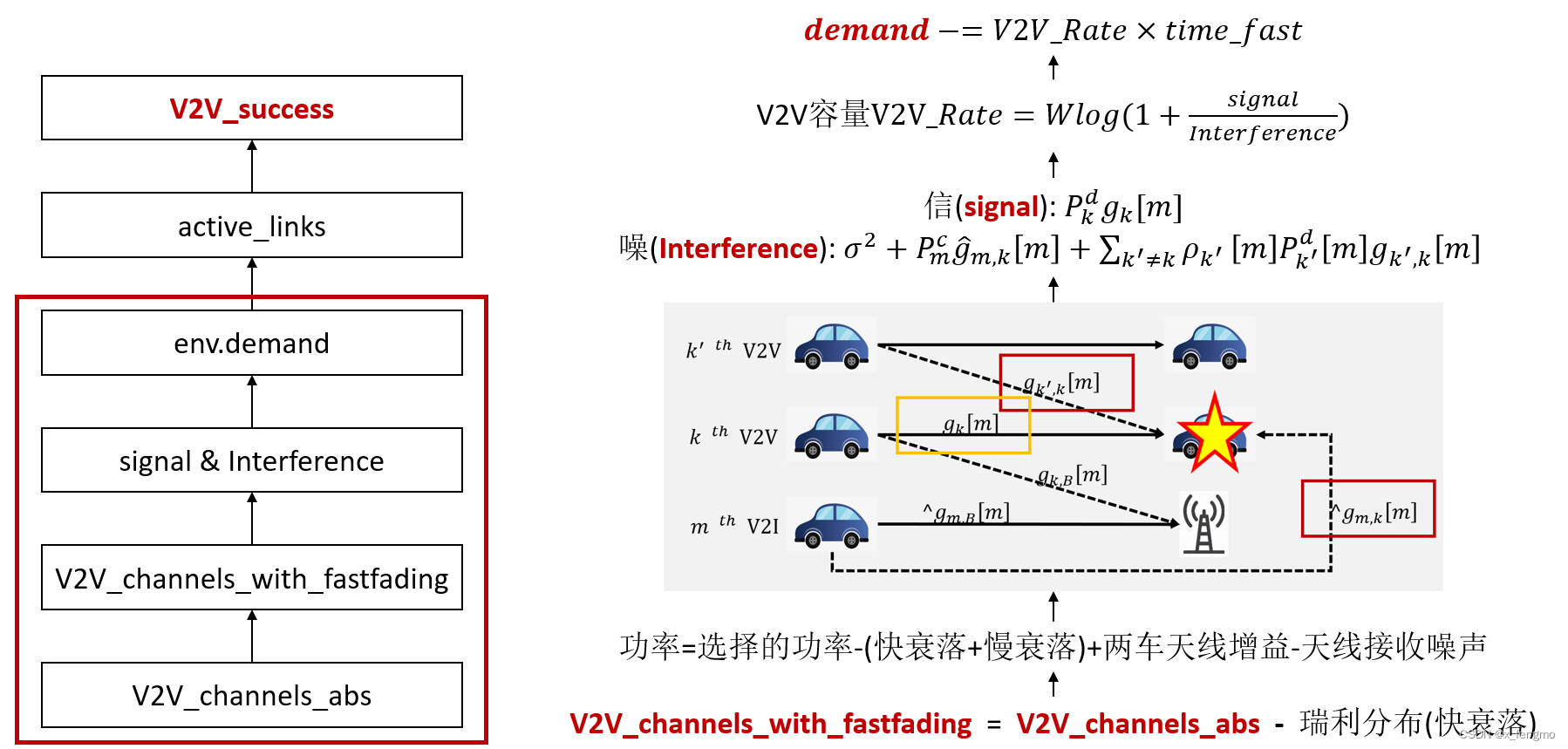

对应于论文中实验结果为此图

2.3.2 V2I容量
总结如何计算出V2I容量
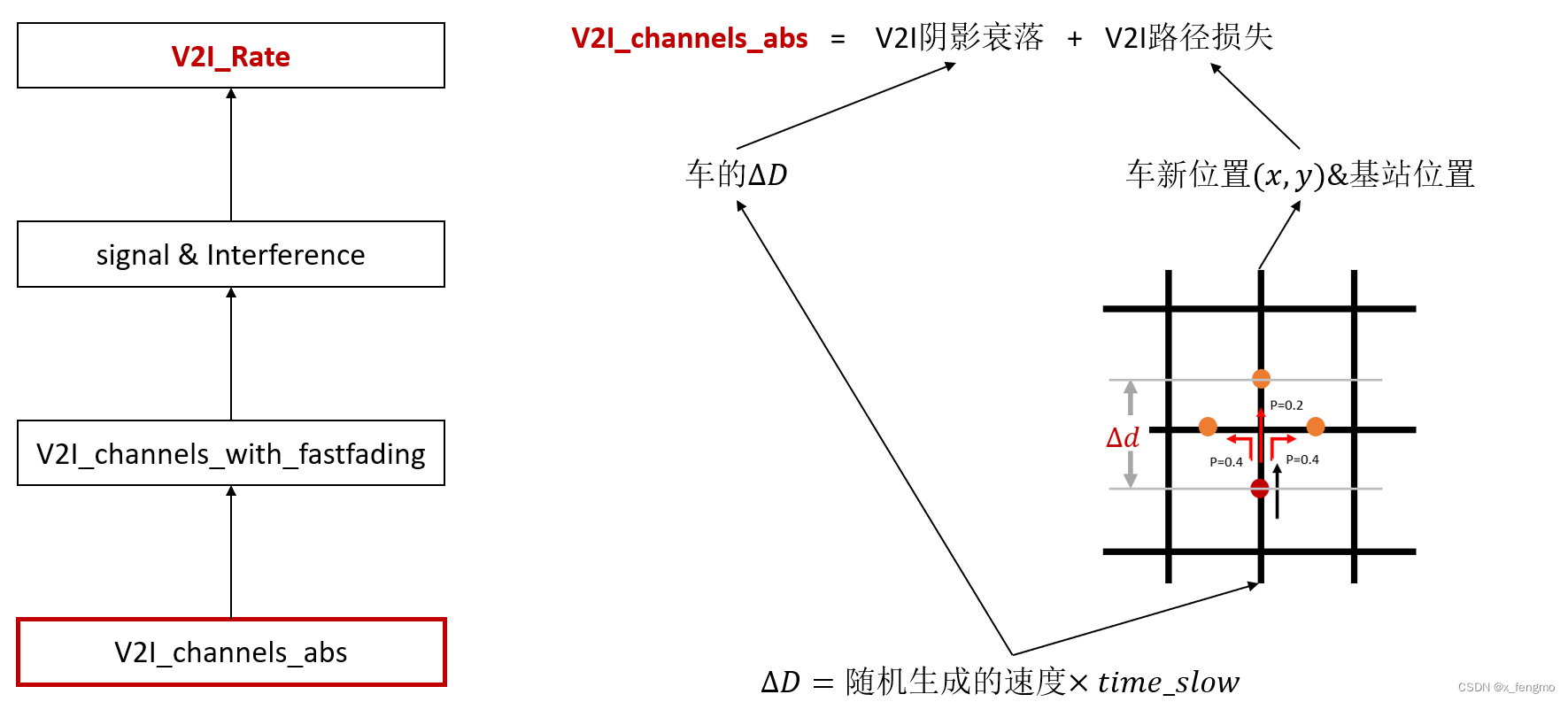
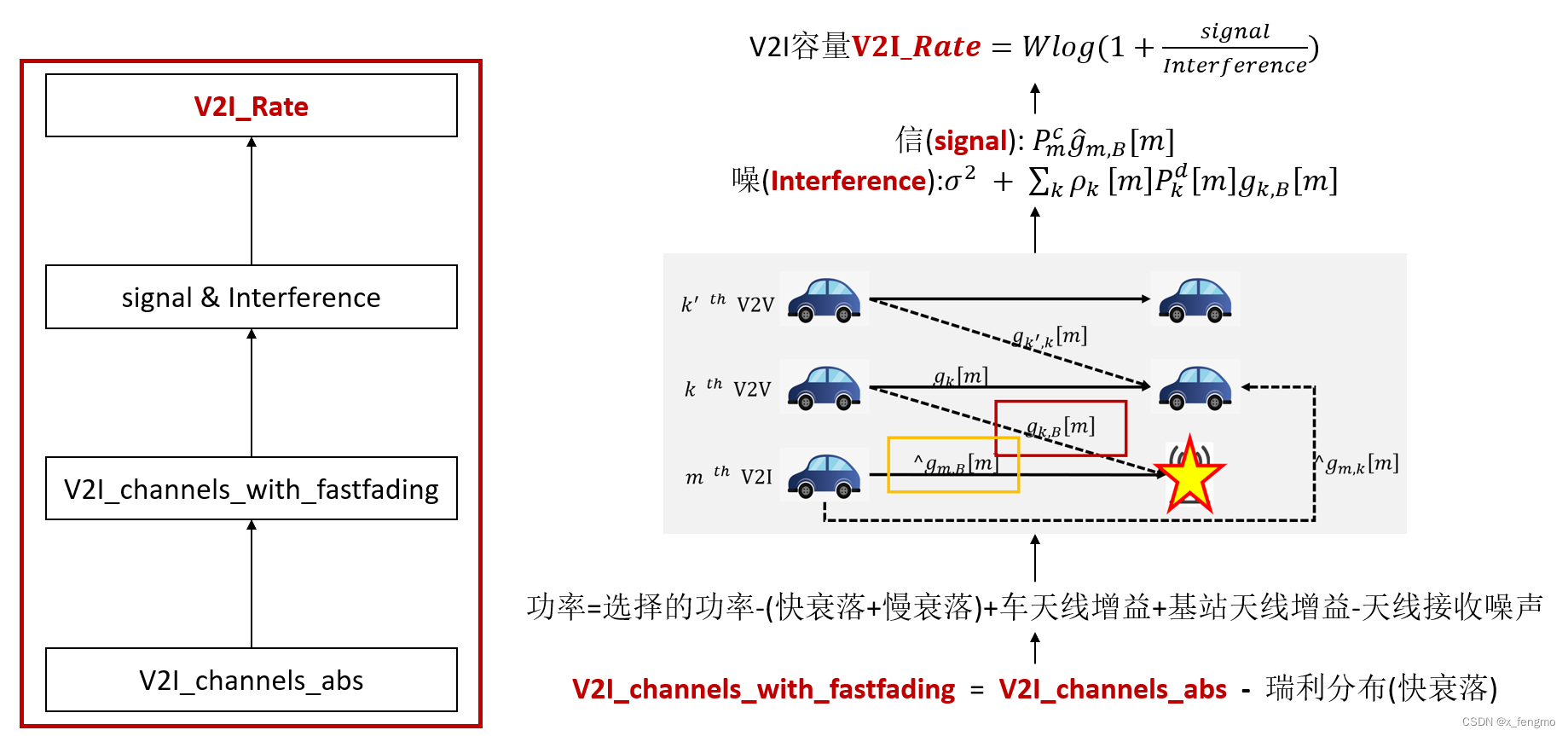
对应于论文中实验结果为此图

# Environment_marl.py中
if IS_TEST:
print("\nRestoring the model...")
for i in range(n_veh):
for j in range(n_neighbor):
model_path = label + '/agent_' + str(i * n_neighbor + j)
load_models(sesses[i * n_neighbor + j], model_path)
V2I_rate_list = []
V2V_success_list = []
V2I_rate_list_rand = []
V2V_success_list_rand = []
rate_marl = np.zeros([n_episode_test, n_step_per_episode, n_veh, n_neighbor])
rate_rand = np.zeros([n_episode_test, n_step_per_episode, n_veh, n_neighbor])
demand_marl = env.demand_size * np.ones([n_episode_test, n_step_per_episode+1, n_veh, n_neighbor])
demand_rand = env.demand_size * np.ones([n_episode_test, n_step_per_episode+1, n_veh, n_neighbor])
power_rand = np.zeros([n_episode_test, n_step_per_episode, n_veh, n_neighbor])
for idx_episode in range(n_episode_test):
print('----- Episode', idx_episode, '-----')
env.renew_positions()
env.renew_neighbor()
env.renew_channel()
env.renew_channels_fastfading()
env.demand = env.demand_size * np.ones((env.n_Veh, env.n_neighbor))
env.individual_time_limit = env.time_slow * np.ones((env.n_Veh, env.n_neighbor))
env.active_links = np.ones((env.n_Veh, env.n_neighbor), dtype='bool')
env.demand_rand = env.demand_size * np.ones((env.n_Veh, env.n_neighbor))
env.individual_time_limit_rand = env.time_slow * np.ones((env.n_Veh, env.n_neighbor))
env.active_links_rand = np.ones((env.n_Veh, env.n_neighbor), dtype='bool')
V2I_rate_per_episode = []
V2I_rate_per_episode_rand = []
for test_step in range(n_step_per_episode):
# trained models
action_all_testing = np.zeros([n_veh, n_neighbor, 2], dtype='int32')
for i in range(n_veh):
for j in range(n_neighbor):
state_old = get_state(env, [i, j], 1, epsi_final)
action = predict(sesses[i*n_neighbor+j], state_old, epsi_final, True)
action_all_testing[i, j, 0] = action % n_RB # chosen RB
action_all_testing[i, j, 1] = int(np.floor(action / n_RB)) # power level
action_temp = action_all_testing.copy()
V2I_rate, V2V_success, V2V_rate = env.act_for_testing(action_temp)
V2I_rate_per_episode.append(np.sum(V2I_rate)) # sum V2I rate in bps
rate_marl[idx_episode, test_step,:,:] = V2V_rate
demand_marl[idx_episode, test_step+1,:,:] = env.demand
# random baseline
action_rand = np.zeros([n_veh, n_neighbor, 2], dtype='int32')
action_rand[:, :, 0] = np.random.randint(0, n_RB, [n_veh, n_neighbor]) # band
action_rand[:, :, 1] = np.random.randint(0, len(env.V2V_power_dB_List), [n_veh, n_neighbor]) # power
V2I_rate_rand, V2V_success_rand, V2V_rate_rand = env.act_for_testing_rand(action_rand)
V2I_rate_per_episode_rand.append(np.sum(V2I_rate_rand)) # sum V2I rate in bps
rate_rand[idx_episode, test_step, :, :] = V2V_rate_rand
demand_rand[idx_episode, test_step+1,:,:] = env.demand_rand
for i in range(n_veh):
for j in range(n_neighbor):
power_rand[idx_episode, test_step, i, j] = env.V2V_power_dB_List[int(action_rand[i, j, 1])]
# update the environment and compute interference
env.renew_channels_fastfading()
env.Compute_Interference(action_temp)
if test_step == n_step_per_episode - 1:
V2V_success_list.append(V2V_success)
V2V_success_list_rand.append(V2V_success_rand)
V2I_rate_list.append(np.mean(V2I_rate_per_episode))
V2I_rate_list_rand.append(np.mean(V2I_rate_per_episode_rand))
print(round(np.average(V2I_rate_per_episode), 2), 'rand', round(np.average(V2I_rate_per_episode_rand), 2))
print(V2V_success_list[idx_episode], 'rand', V2V_success_list_rand[idx_episode])
三、 实验结果分析
详见 此篇文章















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











