









1、什么是Hive?
Hive是基于Hadoop文件系统之上的数据仓库架构,它为数据仓库的管理提供了许多功能:数据ETL(抽取、转换、加载)工具、数据存储管理和大型数据集的查询和分析能力。同时Hive还定义了类SQL的语言--Hive QL,Hive QL允许用户进行和SQL相似的操作,它可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能。还允许开发人员方便的使用Mapper和Reduce操作,可以将SQL语句转换为MapReduce任务运行,这对MapReduce框架来说是一个强有力的支持。
2、Hive体系结构
Hive是Hadoop中的一个重要的子项目,从下图我们可以大致了解Hive在Hadoop中的位置和关系。
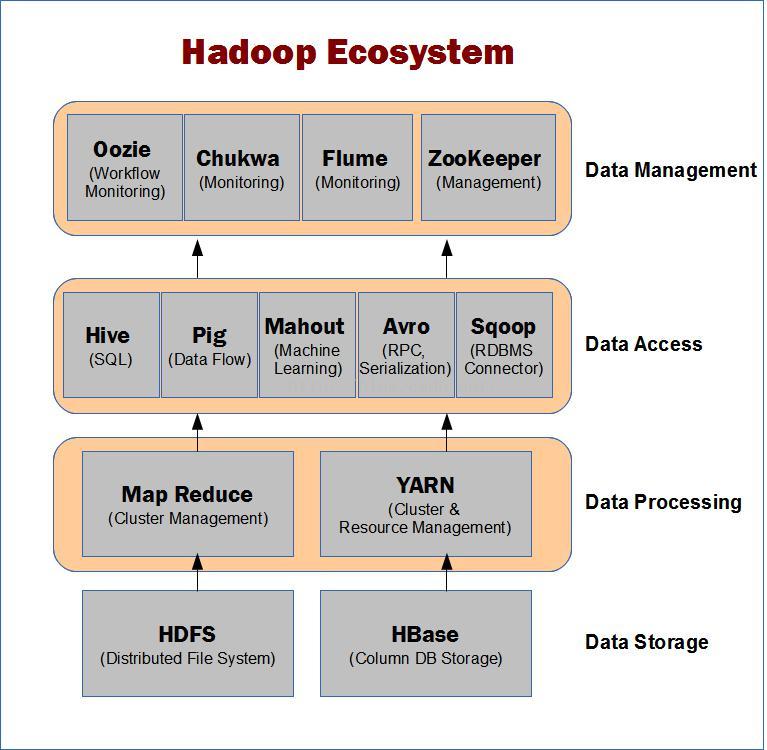
上图描述Hadoop EcoSystem 中的各层系统,而Hive本身的体系架构如下:
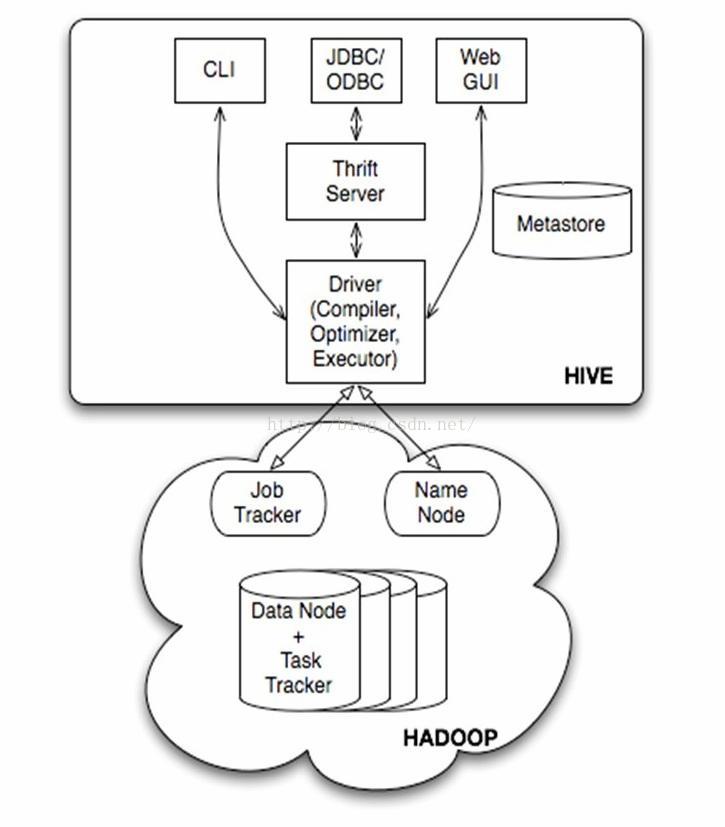
从图中我们可以看出Hive其基本组成可以分为:
- 用户接口,包括 CLI, JDBC/ODBC, WebUI
- 元数据存储、通常是存储在关系数据库如MySQL, Derby中
- 解释器、编译器、优化器、执行器
- Hadoop,用HDFS进行存储,利用MapReduce进行计算
Hive在很多方面与传统关系数据库类似(例如支持SQL接口),但是其底层对HDFS和MapReduce的依赖意味着它的体系结构有别于传统关系数据库,而这些区别又影响着Hive所支持的特性,进而影响着Hive的使用。
4、Hive应用场景
通过对Hive与传统关系数据库比较之后,其实我们不难得出Hive可以应用于那些场景。
Hive架构在基于静态批处理的Hadoop之上,Hadoop通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive不适合在大规模数据集上实现低延迟快速的查询。
5、Hive的数据存储
Hive的存储是建立Hadoop文件系统之上,Hive本身没有专门的数据存储格式,也不能为数据建立索引,因此用户可以 非常自由的组织Hive中的表,只需要在创建的时候告诉Hive数据中的列分隔符就可以解析数据了。
Hive中主要包括4中数据模型:表(table)、外部表(External Table)、分区(Partition)以及桶(Bucket)。
Hive的表和数据库中的表在概念上没有什么本质区别,在Hive中每个表都有一个对应的存储目录,而外部表纸箱HDFS中存在的数据,也可以创建分区。Hive中每个分区都对应数据库中相应分区列的一个索引,但是其对分区的组织方式和传统关系数据库不同,桶在指定列进行Hash计算时,会根据哈希值切分数据,使每个桶对应一个文件。















 1551
1551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









