






今天总算弄懂了01-分数规划问题。。。由于答案是double型的,,结果输出的时候是只允许用printf("%f"),也就是说,我一开始用了%lf,,结果。。。。一个上午就因为这样过去了。。。。 wa了一万次,,,我对着网上的代码一行一行查下来。。。结果就是因为在这里的一个错误???我的世界观再一次被颠覆了。。。
wa了一万次,,,我对着网上的代码一行一行查下来。。。结果就是因为在这里的一个错误???我的世界观再一次被颠覆了。。。
好啦,==是我基础不扎实,,,,不过也不能怪我,我除了c语言,,没有系统学过其他任何关于编程方面的课程,关键是,,c里好像double型好像就是对应%lf的吧 委屈过后,我看了网上牛人的解释,他说,
委屈过后,我看了网上牛人的解释,他说,
好吧,既然你是牛人,那我就信了(我也不得不信)
言归正传,01分数划分,就是在你不知道答案ans,但却知道k<ans是是怎么样的情况,k>ans时又是一个怎么样的情况,然后框定一个k的范围(注意要包含ans,,不然明显就是白搭),之后不断地用二分的方法,在k这个范围中找到合适的最接近ans的那个值。注意,这里ans并不是一个准确的值,它的精确程度取决于你想要让它精确到的程度。。
来看具体的例子把
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 9312 | Accepted: 3267 |
Description
In a certain course, you take n tests. If you get ai out ofbi questions correct on test i, your cumulative average is defined to be
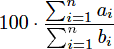 .
.
Given your test scores and a positive integer k, determine how high you can make your cumulative average if you are allowed to drop anyk of your test scores.
Suppose you take 3 tests with scores of 5/5, 0/1, and 2/6. Without dropping any tests, your cumulative average is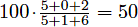 . However, if you drop the third test, your cumulative average becomes
. However, if you drop the third test, your cumulative average becomes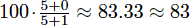 .
.
Input
The input test file will contain multiple test cases, each containing exactly three lines. The first line contains two integers, 1 ≤n ≤ 1000 and 0 ≤ k < n. The second line contains n integers indicatingai for all i. The third line contains n positive integers indicatingbi for all i. It is guaranteed that 0 ≤ ai ≤bi ≤ 1, 000, 000, 000. The end-of-file is marked by a test case withn = k = 0 and should not be processed.
Output
For each test case, write a single line with the highest cumulative average possible after droppingk of the given test scores. The average should be rounded to the nearest integer.
Sample Input
3 1 5 0 2 5 1 6 4 2 1 2 7 9 5 6 7 9 0 0
Sample Output
83 100
Hint
To avoid ambiguities due to rounding errors, the judge tests have been constructed so that all answers are at least 0.001 away from a decision boundary (i.e., you can assume that the average is never 83.4997).
分析:
最典型的一题,题意是,给你 a和b 两组数,它们两两对应(也就是绑在一起),每一对a和b可以看成一组,然后让你给你一个数字k,也就是不要的组数
(具体哪几组是不明确的),然后要你在这个前提下,找出剩余的组数,输出使得剩下的a元素之和与b元素之和的比率最大值。
题目求的是 max(∑a[i] * x[i] / (b[i] * x[i])) 其中a,b都是一一对应的。 x[i]取0,1 并且 ∑x[i] = n - k;
转化: 令r = ∑a[i] * x[i] / (b[i] * x[i]) 则必然∑a[i] * x[i] - ∑b[i] * x[i] * r= 0;(条件1)
并且任意的 ∑a[i] * x[i] - ∑b[i] * x[i] * max(r) <= 0 (条件2,只有当∑a[i] * x[i] / (b[i] * x[i]) = max(r) 条件2中等号才成立)
然后就可以枚举r , 对枚举的r, 求Q(r) = ∑a[i] * x[i] - ∑b[i] * x[i] * r 的最大值, 为什么要求最大值呢? 因为我们之前知道了条件2,所以当我们枚举到r为max(r)的值时,显然对于所有的情况Q(r)都会小于等于0,并且Q(r)的最大值一定是0.而我们求最大值的目的就是寻找Q(r)=0的可能性,这样就满足了条件1,最后就是枚举使得Q(r)恰好等于0时就找到了max(r)。而如果能Q(r)>0 说明该r值是偏小的,并且可能存在Q(r)=0,而Q(r)<0的话,很明显是r值偏大的,因为max(r)都是使Q(r)最大值为0,说明不可能存在Q(r)=0了。
代码(其中一部分可以作模板)
#include <cstdio>
#include <algorithm>
#include <string.h>
#include <iostream>
using namespace std;
double a[1005], b[1005];
double s[1005];
int n, k;
int main()
{
int n, k;
while(scanf("%d %d", &n, &k)){
if(n == 0 && k == 0)
break;
for(int i = 1; i <= n; i++)
scanf("%lf", &a[i]);
for(int i = 1; i <= n; i++)
scanf("%lf", &b[i]);
double left = 0.0, right = 1.0, mid;
while(right - left > 1e-4){
double sum = 0.0;
mid = (left + right) / 2.0;
for(int i = 1; i <= n; i++)
s[i] = a[i] - mid * b[i];
sort(s + 1, s + 1 + n);
for(int i = k + 1; i <= n; i++)
sum += s[i];
if(sum > 0)
left = mid;
else
right = mid;
}
printf("%.0f\n",mid*100);
}
return 0;
}是不是不够过瘾 那就再来一题
那就再来一题
题目地址http://poj.org/problem?id=3621
| Time Limit: 1000MS | Memory Limit: 65536K | |
| Total Submissions: 9312 | Accepted: 3267 |
Description
In a certain course, you take n tests. If you get ai out ofbi questions correct on test i, your cumulative average is defined to be
.
Given your test scores and a positive integer k, determine how high you can make your cumulative average if you are allowed to drop anyk of your test scores.
Suppose you take 3 tests with scores of 5/5, 0/1, and 2/6. Without dropping any tests, your cumulative average is. However, if you drop the third test, your cumulative average becomes.
Input
The input test file will contain multiple test cases, each containing exactly three lines. The first line contains two integers, 1 ≤n ≤ 1000 and 0 ≤ k < n. The second line contains n integers indicatingai for all i. The third line contains n positive integers indicatingbi for all i. It is guaranteed that 0 ≤ ai ≤bi ≤ 1, 000, 000, 000. The end-of-file is marked by a test case withn = k = 0 and should not be processed.
Output
For each test case, write a single line with the highest cumulative average possible after droppingk of the given test scores. The average should be rounded to the nearest integer.
Sample Input
3 1 5 0 2 5 1 6 4 2 1 2 7 9 5 6 7 9 0 0
Sample Output
83 100
Hint
To avoid ambiguities due to rounding errors, the judge tests have been constructed so that all answers are at least 0.001 away from a decision boundary (i.e., you can assume that the average is never 83.4997).
题目的意思是:求一个环的{点权和}除以{边权和},使得那个环在所有环中{点权和}除以{边权和}最大。
令在一个环里,点权为v[i],对应的边权为e[i],
即要求:∑(i=1,n)v[i]/∑(i=1,n)e[i]最大的环(n为环的点数),
设题目答案为ans,
即对于所有的环都有 ∑(i=1,n)(v[i])/∑(i=1,n)(e[i])<=ans
变形得ans* ∑(i=1,n)(e[i])>=∑(i=1,n)(v[i])
再得 ∑(i=1,n)(ans*e[i]-v[i]) >=0
稍分析一下,就有:
当k<ans时,就存在至少一个环∑(i=1,n)(k*e[i]-v[i])<0,即有负权回路(边权为k*e[i]-v[i]);
当k>=ans时,就对于所有的环∑(i=1,n)(k*e[i]-v[i])>=0,即没有负权回路。
然后我们就可以使新的边权为k*e[i]-v[i],用spfa来判断付权回路,二分ans。
#include <cstdio>
#include <algorithm>
#include <string.h>
#include <queue>
using namespace std;
int const inf = 0x3f3f3f3f;
int const MAX = 5005;
int val[MAX];
struct Edge
{
int w, to, next;
}e[MAX];
int head[MAX];
int n, m;
int spfa(double mid)
{
double dist[MAX];
int vis[MAX];
int in[MAX];
memset(vis, 0, sizeof(vis));
memset(in, 0, sizeof(in));
for(int i = 1; i <= n; i++){
dist[i] = inf;
}
queue<int> q;
dist[1] = 0;
q.push(1);
vis[1] = 1;
while(!q.empty()){
int u = q.front();
q.pop();
in[u]++;
vis[u] = 0;
if(in[u] > n)
return 1;
for(int i = head[u]; i != -1; i = e[i].next){
int v = e[i].to;
int w = e[i].w;
double we = w * mid - val[u];
if(dist[v] > dist[u] + we){
dist[v] = dist[u] + we;
if(!vis[v]){
q.push(v);
vis[v] = 1;
}
}
}
}
return 0;
}
int main()
{
memset(head, -1, sizeof(head));
scanf("%d %d", &n, &m);
for(int i = 1; i <= n; i++)
scanf("%d", &val[i]);
for(int i = 1; i <= m; i++){
int u, v, w;
scanf("%d %d %d", &u, &v, &w);
e[i].to = v;
e[i].w = w;
e[i].next = head[u];
head[u] = i;
}
double l = 0, r = 1000.0, mid;
while(r - l > 1e-6){
mid = (l + r) / 2;
if(spfa(mid))
l = mid;
else
r = mid;
}
printf("%.2f\n", mid);
}| Time Limit: 3000MS | Memory Limit: 65536K | |
| Total Submissions: 23824 | Accepted: 6648 |
Description
After days of study, he finally figured his plan out. He wanted the average cost of each mile of the channels to be minimized. In other words, the ratio of the overall cost of the channels to the total length must be minimized. He just needs to build the necessary channels to bring water to all the villages, which means there will be only one way to connect each village to the capital.
His engineers surveyed the country and recorded the position and altitude of each village. All the channels must go straight between two villages and be built horizontally. Since every two villages are at different altitudes, they concluded that each channel between two villages needed a vertical water lifter, which can lift water up or let water flow down. The length of the channel is the horizontal distance between the two villages. The cost of the channel is the height of the lifter. You should notice that each village is at a different altitude, and different channels can't share a lifter. Channels can intersect safely and no three villages are on the same line.
As King David's prime scientist and programmer, you are asked to find out the best solution to build the channels.
Input
Output
Sample Input
4 0 0 0 0 1 1 1 1 2 1 0 3 0
Sample Output
1.000
#include <cstdio>
#include <string.h>
#include <vector>
#include <math.h>
#include <algorithm>
using namespace std;
int const MAX = 1100;
int const inf = 0x3f3f3f3f;
int n;
int h[MAX], x[MAX], y[MAX];
double mp[MAX][MAX];
double prim(double mid)
{
int vis[MAX];
double low[MAX];
double ans = 0, mi;
// memset(low, inf, sizeof(low));
memset(vis, 0, sizeof(vis));
int pos = 1;
vis[pos] = 1;
for(int i = 1; i <= n; i++)
low[i] = abs(h[pos]-h[i]) - mid * mp[pos][i];
for(int i = 1; i < n; i++){
mi = inf;
pos = -1;
for(int j = 1; j <= n; j++)
if(!vis[j] && mi > low[j]){
pos = j;
mi = low[j];
}
if(pos == -1) break;
ans += mi;
vis[pos] = 1;
for(int j = 1; j <= n; j++){
double tmp = abs(h[pos]-h[j]) - mid * mp[pos][j];
if(!vis[j] && low[j] > tmp)
low[j] = tmp;
}
}
return ans;
}
int main()
{
while(scanf("%d", &n) && n != 0){
for(int i = 1; i <= n; i++){
scanf("%d %d %d", &x[i], &y[i], &h[i]);
}
for(int i = 1; i <= n; i++)
for(int j = i + 1; j <= n; j++)
mp[i][j] = mp[j][i] = sqrt((x[i]-x[j])*(x[i]-x[j]) + (y[i]-y[j])*(y[i]-y[j]));
double l = 0.0, r = 40.0, mid;
while((r - l) >= 1e-6){
mid = (l + r) / 2;
if(prim(mid) >= 0)
l = mid;
else
r = mid;
}
printf("%.3f\n", mid);
}
return 0;
}

















 965
965

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










对输出来说,没有不同。
在printf系列语句中,double 和 float 的格式化指示符都是 %f。实际上float会被提升为double再传入printf,所以对这两个浮点类型都应该用%f,虽然C标准也允许你写%lf。
在scanf系列语句中,double 类型对应 %lf,float 类型对应 %f。