







漫画:什么是Bitmap算法?




两个月之前——





为满足用户标签的统计需求,小灰利用 Mysql 设计了如下的表结构,每一个维度的标签都对应着 Mysql 表的一列:

要想统计所有90后的程序员该怎么做呢?
用一条求交集的SQL语句即可:
Select count(distinct Name) as 用户数 from table whare age = ‘90后’ and Occupation = ‘程序员’ ;
要想统计所有使用苹果手机或者00后的用户总合该怎么做?
用一条求并集的SQL语句即可:
Select count(distinct Name) as 用户数 from table whare Phone = ‘苹果’ or age = ‘00后’ ;

两个月之后——









1. 给定长度是 10 的 bitmap,每一个 bit 位分别对应着从 0 到 9 的 10 个整型数。此时 bitmap 的所有位都是 0。

2. 把整型数 4 存入 bitmap,对应存储的位置就是下标为4的位置,将此 bit 置为 1。

3. 把整型数2存入bitmap,对应存储的位置就是下标为2的位置,将此bit置为1。

4. 把整型数1存入bitmap,对应存储的位置就是下标为1的位置,将此bit置为1。

5. 把整型数3存入bitmap,对应存储的位置就是下标为3的位置,将此bit置为1。

要问此时 bitmap 里存储了哪些元素?显然是 4,3,2,1,一目了然。
Bitmap 不仅方便查询,还可以去除掉重复的整型数。






- 建立用户名和用户 ID 的映射:
- 让每一个标签存储包含此标签的所有用户 ID,每一个标签都是一个独立的 Bitmap。

3. 这样,实现用户的去重和查询统计,就变得一目了然:





- 如何查找使用苹果手机的程序员用户?
- 如何查找所有男性或者00后的用户?

一周之后…




我们以上一期的用户数据为例,用户基本信息如下。按照年龄标签,可以划分成 90 后、00 后两个 Bitmap:

用更加形象的表示,90 后用户的 Bitmap 如下:

这时候可以直接求得非90后的用户吗?直接进行非运算?

显然,非 90 后用户实际上只有 1 个,而不是图中得到的 8 个结果,所以不能直接进行非运算。


同样是刚才的例子,我们给定 90 后用户的 Bitmap,再给定一个全量用户的 Bitmap。最终要求出的是存在于全量用户,但又不存在于 90 后用户的部分。

如何求出呢?我们可以使用异或操作,即相同位为 0,不同位为 1。


































25769803776 L = 11000000000000000000000000000000000 B
8589947086 L = 1000000000000000000011000011001110 B






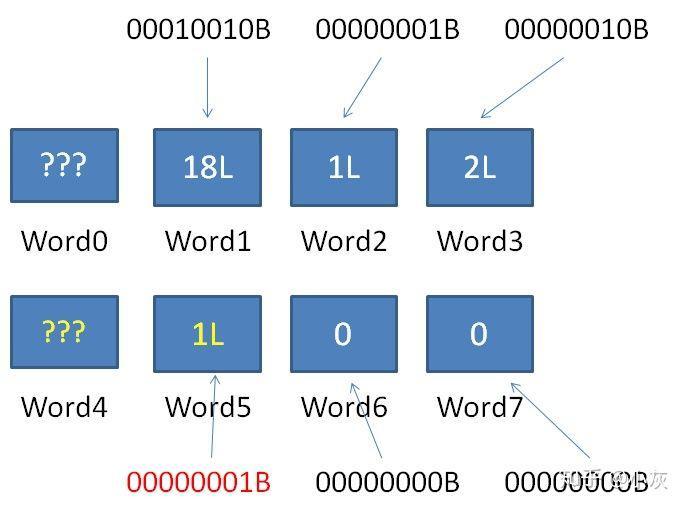
1.解析 Word 0,得知当前 RLW 横跨的空 Word 数量为 0,后面有连续 3 个普通 Word。
2.计算出当前 RLW 后方连续普通 Word 的最大 ID 是 64 X (0 + 3) -1 = 191。
3. 由于 191 < 400003,所以新 ID 必然在下一个 RLW(Word4)之后。
4.解析 Word 4,得知当前 RLW 横跨的空 Word 数量为 6247,后面有连续 1 个普通 Word。
5.计算出当前 RLW(Word4)后方连续普通 Word 的最大 ID 是 191 + (6247 + 1)X64 = 400063。
6.由于 400003 < 400063,因此新 ID 400003 的正确位置就在当前 RLW(Word4)的后方普通 Word,也就是 Word 5 当中。
最终插入结果如下:





官方说明如下:
Though you can set the bits in any order (e.g., set(100), set(10), set(1),
you will typically get better performance if you set the bits in increasing order (e.g., set(1), set(10), set(100)).
Setting a bit that is larger than any of the current set bit
is a constant time operation. Setting a bit that is smaller than an
already set bit can require time proportional to the compressed
size of the bitmap, as the bitmap may need to be rewritten.

几点说明:
- 该项目最初的技术选型并非Mysql,而是内存数据库hana。本文为了便于理解,把最初的存储方案写成了Mysq数据库。
- 文中介绍的Bitmap优化方法在一定程度上做了简化,源码中的逻辑要复杂得多。比如对于插入数据400003的定位,和实际步骤是有出入的。
- 如果同学们有兴趣,可以亲自去阅读源码,甚至是尝试实现自己的Bitmap算法。虽然要花不少时间,但这确实是一种很好的学习方法。
python BitMap实现
假设有20亿个int类型不重复非负数的数字,而我们只有4G的内存空间,如何将其排序?
一个int类型数据占据4个Byte,而1个Byte占据8个bit位。20亿个int大概需要7.45GB的内存。那么4G的空间是决计不够的
我们可以用1bit来存储一个int的目的,只要遍历一下这个bitmap,就可以自然地得到数字序列的排序。并且理论上它所占用的空间只有原来的1/32,20亿个数字,现在只需要230MB左右即可实现。
python 中的int 是有符号的,所以只支持31 个数
# -*- coding:utf-8 -*-
class BitMap():
def __init__(self, maxValue):
self._size = int((maxValue + 31 - 1) / 31) # 向上取正 确定数组大小
# self._size = num / 31 # 向下取正 确定数组大小
self.array = [0 for i in range(self._size)] # 初始化为0
def getElemIndex(self, num): # 获取该数的数组下标
return num // 31
def getBitIndex(self, num): # 获取该数所在数组的位下标
return num % 31
def set(self, num): # 将该数所在的位置1
elemIndex = self.getElemIndex(num)
bitIndex = self.getBitIndex(num)
self.array[elemIndex] = self.array[elemIndex] | (1 << bitIndex)
def clean(self, num): # 将该数所在的位置0
elemIndex = self.getElemIndex(num)
bitIndex = self.getBitIndex(num)
self.array[elemIndex] = self.array[elemIndex] & (~(1 << bitIndex))
def find(self, num): # 查找该数是否存在
elemIndex = self.getElemIndex(num)
bitIndex = self.getBitIndex(num)
if self.array[elemIndex] & (1 << bitIndex):
return True
return False
if __name__ == '__main__':
array_list = [45, 2, 78, 35, 67, 90, 879, 0, 340, 123, 46]
results = []
bitmap = BitMap(maxValue=max(array_list))
for num in array_list:
bitmap.set(num)
for i in range(max(array_list) + 1):
if bitmap.find(i):
results.append(i)
print(array_list)
print(results)
结果:
原始数据 [45, 2, 78, 35, 67, 90, 879, 0, 340, 123, 46]
排序后数据 [0, 2, 35, 45, 46, 67, 78, 90, 123, 340, 879]
来源:https://www.sohu.com/a/300039010_114877
https://blog.csdn.net/zy13270867781/article/details/89500573
https://my.oschina.net/goal/blog/200347














 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









