






先说几个PTrade软件使用中可能遇到的小问题
-
ptrade策略里面的发送邮件功能,只支持QQ邮箱为发送方
-
ptrade可以客户端修改密码,QMT不可以,清算时间不支持密码修改。
-
PTrade模拟环境升级后,PTrade财务数据已经先放在本地
-
如果为了安全考虑,客户可以申请绑定授权Mac地址,不控制IP
-
查询“可转债发行规模和溢价率”,用 PTrade get_cb_info 这个接口
Ptrade和QMT软件常见问题和解决方法会继续更新,欢迎关注或者留言提问。
也可以查看我的公众号 QMT量化服务
一、PTrade软件中完整策略的上传和导出
有朋友遇到把完整策略上传PTrade失败的情况,如图
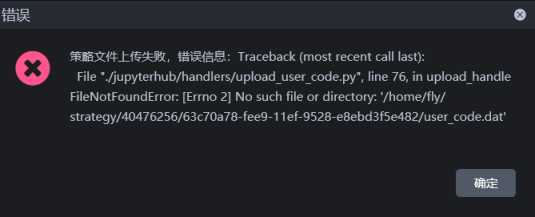
并且这个策略就是Ptrade软件导出来的,解决方法,考虑用get_research_path() 替换
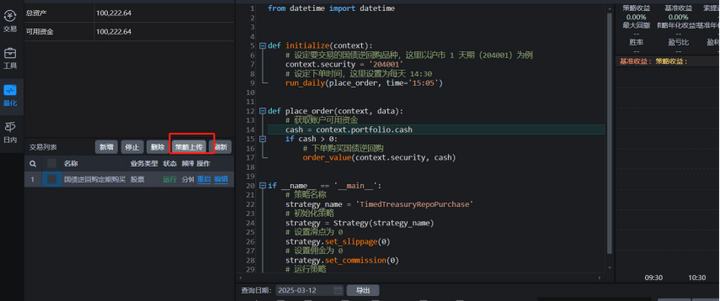
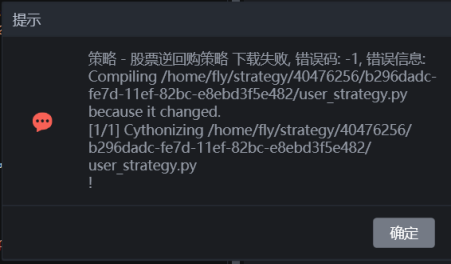
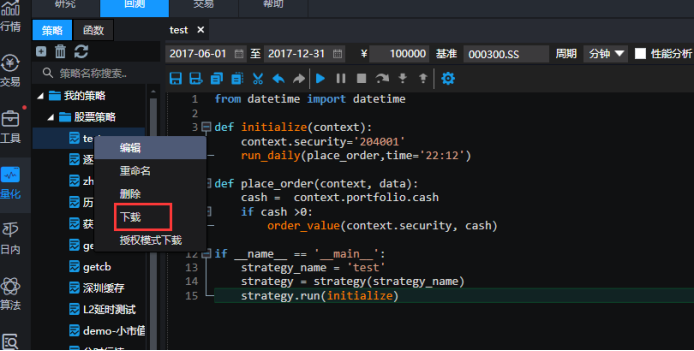
同时,在导出策略时,如果遇到报错,实盘软件用下图中的“下载”选项就可以了,默认加密的。不建议用授权模式。
二、Py 3.11 支持的三方库列表,需要可以查询。
Python3.11支持的三方库180.169.107.9:7766/hub/data/pip_list_py311
三、PTrade软件更新后,三方库变动对照表
(表格比较大,可用control +f 检索关键词查询。)
| 类名/函数名 | Python3.5实现 | Python3.11实现 | 说明 | |
|---|---|---|---|---|
| Numpy | numpy.linalg.lstsq | def lstsq(a, b, rcond=-1): | def lstsq(a, b, rcond="warn"): | 参数默认值改变 |
| Pandas | pandas.concat | def concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=None, copy=True): | def concat(objs:Iterable[NDFrame]|Mapping[HashableT, NDFrame], axis:Axis=0, join:str="outer", ignore_index:bool=False, keys=None, levels=None, names=None, verify_integrity:bool=False, sort:bool=False, copy:bool=True)->DataFrame|Series: | 弃用join_axes参数 |
| pandas.DatetimeIndex | def __new__(cls, data=None, freq=None, start=None, end=None, periods=None, tz=None, normalize=False, closed=None, ambiguous='raise', dayfirst=False, yearfirst=False, dtype=None, copy=False, name=None, verify_integrity=True): | def __new__(cls, data=None, freq:str|BaseOffset|lib.NoDefault=lib.no_default, tz=None, normalize:bool=False, closed=None, ambiguous="raise", dayfirst:bool=False, yearfirst:bool=False, dtype:Dtype|None=None, copy:bool=False, name:Hashable=None)->DatetimeIndex: | 弃用start参数 | |
| pandas.DataFrame.append | def append(self, other, ignore_index=False, verify_integrity=False, sort=None): | def append(self, other, ignore_index:bool=False, verify_integrity:bool=False, sort:bool=False)->DataFrame: | 参数默认值改变 | |
| pandas.DataFrame.apply | def apply(self, func, axis=0, broadcast=None, raw=False, reduce=None, result_type=None, args=(), **kwds): | def apply(self, func:AggFuncType, axis:Axis=0, raw:bool=False, result_type:Literal["expand", "reduce", "broadcast"]|None=None, args=(), **kwargs): | 弃用broadcast参数 | |
| pandas.DataFrame.astype | def astype(self, dtype, copy=True, errors='raise', **kwargs): | def astype(self:NDFrameT, dtype, copy:bool_t=True, errors:IgnoreRaise="raise")->NDFrameT: | 不再支持以kwargs方式传入额外入参 | |
| pandas.DataFrame.quantile | def quantile(self, q=0.5, axis=0, numeric_only=True, interpolation='linear'): | def quantile(self, q:float|AnyArrayLike|Sequence[float]=0.5, axis:Axis=0, numeric_only:bool|lib.NoDefault=no_default, interpolation:QuantileInterpolation="linear", method:Literal["single", "table"]="single")->Series|DataFrame: | 参数默认值改变 | |
| pandas.DataFrame.replace | def replace(self, to_replace=None, value=None, inplace=False, limit=None, regex=False, method='pad'): | def replace(self, to_replace=None, value=lib.no_default, inplace:bool=False, limit:int|None=None, regex:bool=False, method:Literal["pad", "ffill", "bfill"]|lib.NoDefault=lib.no_default)->DataFrame|None: | 参数默认值改变 | |
| pandas.DataFrame.resample | def resample(self, rule, how=None, axis=0, fill_method=None, closed=None, label=None, convention='start', kind=None, loffset=None, limit=None, base=0, on=None, level=None): | def resample(self, rule, axis:Axis=0, closed:str|None=None, label:str|None=None, convention:str="start", kind:str|None=None, loffset=None, base:int|None=None, on:Level=None, level:Level=None, origin:str|TimestampConvertibleTypes="start_day", offset:TimedeltaConvertibleTypes|None=None, group_keys:bool|lib.NoDefault=no_default, )->Resampler: | 弃用how参数 | |
| pandas.DataFrame.sort_index | def sort_index(self, axis=0, level=None, ascending=True, inplace=False, kind='quicksort', na_position='last', sort_remaining=True, by=None): | def sort_index(self, axis:Axis=0, level:IndexLabel=None, ascending:bool|Sequence[bool]=True, inplace:bool=False, kind:SortKind="quicksort", na_position:NaPosition="last", sort_remaining:bool=True, ignore_index:bool=False, key:IndexKeyFunc=None)->DataFrame|None: | 弃用by参数 | |
| pandas.DataFrame.to_csv | def to_csv(self, path_or_buf=None, sep=",", "", na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression=None, quoting=None, quotechar='"', line_terminator='\n', chunksize=None, tupleize_cols=None, date_format=None, doublequote=True, escapechar=None, decimal='.'): | def to_csv(self, path_or_buf:FilePath|WriteBuffer[bytes]|WriteBuffer[str]|None=None, sep:str=",", na_rep:str="", float_format:str|Callable|None=None, columns:Sequence[Hashable]|None=None, header:bool_t|list[str]=True, index:bool_t=True, index_label:IndexLabel|None=None, mode:str="w", encoding:str|None=None, compression:CompressionOptions="infer", quoting:int|None=None, quotechar:str='"', lineterminator:str|None=None, chunksize:int|None=None, date_format:str|None=None, doublequote:bool_t=True, escapechar:str|None=None, decimal:str=".", errors:str="strict", storage_options:StorageOptions=None)->str|None: | 参数默认值改变 | |
| pandas.DataFrame.to_excel | def to_excel(self, excel_writer, sheet_name='Sheet1', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep='inf', verbose=True, freeze_panes=None): | def to_excel(self, excel_writer, sheet_name:str="Sheet1", na_rep:str="", float_format:str|None=None, columns:Sequence[Hashable]|None=None, header:Sequence[Hashable]|bool_t=True, index:bool_t=True, index_label:IndexLabel=None, startrow:int=0, startcol:int=0, engine:str|None=None, merge_cells:bool_t=True, encoding:lib.NoDefault=lib.no_default, inf_rep:str="inf", verbose:lib.NoDefault=lib.no_default, freeze_panes:tuple[int, int]|None=None, storage_options:StorageOptions=None)->None: | 参数默认值改变 | |
| pandas.DataFrame.to_html | def to_html(self, buf=None, columns=None, col_space=None, header=True, index=True, na_rep='NaN', formatters=None, float_format=None, sparsify=None, index_names=True, justify=None, bold_rows=True, classes=None, escape=True, max_rows=None, max_cols=None, show_dimensions=False, notebook=False, decimal='.', border=None, table_id=None): | def to_html(self, buf:FilePath|WriteBuffer[str]|None=None, columns:Sequence[Level]|None=None, col_space:ColspaceArgType|None=None, header:bool|Sequence[str]=True, index:bool=True, na_rep:str="NaN", formatters:FormattersType|None=None, float_format:FloatFormatType|None=None, sparsify:bool|None=None, index_names:bool=True, justify:str|None=None, max_rows:int|None=None, max_cols:int|None=None, show_dimensions:bool|str=False, decimal:str=".", bold_rows:bool=True, classes:str|list|tuple|None=None, escape:bool=True, notebook:bool=False, border:int|bool|None=None, table_id:str|None=None, render_links:bool=False, encoding:str|None=None)->str|None: | 参数顺序改变 | |
| pandas.DataFrame.to_json | def to_json(self, path_or_buf=None, orient=None, date_format=None, double_precision=10, force_ascii=True, date_unit='ms', default_handler=None, lines=False, compression=None, index=True): | def to_json(self, path_or_buf:FilePath|WriteBuffer[bytes]|WriteBuffer[str]|None=None, orient:str|None=None, date_format:str|None=None, double_precision:int=10, force_ascii:bool_t=True, date_unit:str="ms", default_handler:Callable[[Any], JSONSerializable]|None=None, lines:bool_t=False, compression:CompressionOptions="infer", index:bool_t=True, indent:int|None=None, storage_options:StorageOptions=None)->str|None: | 参数默认值改变 | |
| pandas.DataFrame.to_records | def to_records(self, index=True, convert_datetime64=None): | def to_records(self, index:bool=True, column_dtypes=None, index_dtypes=None)->np.recarray: | 弃用convert_datetime64参数 | |
| pandas.DataFrame.to_string | def to_string(self, buf=None, columns=None, col_space=None, header=True, index=True, na_rep='NaN', formatters=None, float_format=None, sparsify=None, index_names=True, justify=None, line_width=None, max_rows=None, max_cols=None, show_dimensions=False): | def to_string(self, buf:FilePath|WriteBuffer[str]|None=None, columns:Sequence[str]|None=None, col_space:int|list[int]|dict[Hashable, int]|None=None, header:bool|Sequence[str]=True, index:bool=True, na_rep:str="NaN", formatters:fmt.FormattersType|None=None, float_format:fmt.FloatFormatType|None=None, sparsify:bool|None=None, index_names:bool=True, justify:str|None=None, max_rows:int|None=None, max_cols:int|None=None, show_dimensions:bool=False, decimal:str=".", line_width:int|None=None, min_rows:int|None=None, max_colwidth:int|None=None, encoding:str|None=None)->str|None: | 参数顺序改变 | |
| pandas.DataFrame.update | def update(self, other, join='left', overwrite=True, filter_func=None, raise_conflict=False): | def update(self, other, join:str="left", overwrite:bool=True, filter_func=None, errors:str="ignore")->None: | 弃用raise_conflict参数 | |
| pandas.Panel | def __init__(self, data=None, items=None, major_axis=None, minor_axis=None, copy=False, dtype=None): | 在pandas(0.25.0)版本已弃用 | ||
| pandas.read_excel | def read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, **kwds): | def read_excel(io, sheet_name:str|int|list[IntStrT]|None=0, header:int|Sequence[int]|None=0, names:list[str]|None=None, index_col:int|Sequence[int]|None=None, usecols:int|str|Sequence[int]|Sequence[str]|Callable[[str], bool]|None=None, squeeze:bool|None=None, dtype:DtypeArg|None=None, engine:Literal["xlrd", "openpyxl", "odf", "pyxlsb"]|None=None, converters:dict[str, Callable]|dict[int, Callable]|None=None, true_values:Iterable[Hashable]|None=None, false_values:Iterable[Hashable]|None=None, skiprows:Sequence[int]|int|Callable[[int], object]|None=None, nrows:int|None=None, na_values=None, keep_def ault_na:bool=True, na_filter:bool=True, verbose:bool=False, parse_dates:list|dict|bool=False, date_parser:Callable|None=None, thousands:str|None=None, decimal:str=".", comment:str|None=None, skipfooter:int=0, convert_float:bool|None=None, mangle_dupe_cols:bool=True, storage_options:StorageOptions=None)->DataFrame|dict[IntStrT, DataFrame]: | 参数默认值改变 | |
| pandas.read_json | def read_json(path_or_buf=None, orient=None, typ='frame', dtype=True, convert_axes=True, convert_dates=True, keep_def ault_dates=True, numpy=False, precise_float=False, date_unit=None, encoding=None, lines=False, chunksize=None, compression='infer'): | def read_json(path_or_buf:FilePath|ReadBuffer[str]|ReadBuffer[bytes], orient:str|None=None, typ:Literal["frame", "series"]="frame", dtype:DtypeArg|None=None, convert_axes=None, convert_dates:bool|list[str]=True, keep_def ault_dates:bool=True, numpy:bool=False, precise_float:bool=False, date_unit:str|None=None, encoding:str|None=None, encoding_errors:str|None="strict", lines:bool=False, chunksize:int|None=None, compression:CompressionOptions="infer", nrows:int|None=None, storage_options:StorageOptions=None)->DataFrame|Series|JsonReader: | 参数默认值改变 | |
| pandas.testing.assert_frame_equal | def assert_frame_equal(left, right, check_dtype=True, check_index_type='equiv', check_column_type='equiv', check_frame_type=True, check_less_precise=False, check_names=True, by_blocks=False, check_exact=False, check_datetimelike_compat=False, check_categorical=True, check_like=False, obj='DataFrame'): | def assert_frame_equal(left, right, check_dtype:bool|Literal["equiv"]=True, check_index_type:bool|Literal["equiv"]="equiv", check_column_type="equiv", check_frame_type=True, check_less_precise=no_default, check_names=True, by_blocks=False, check_exact=False, check_datetimelike_compat=False, check_categorical=True, check_like=False, check_freq=True, check_flags=True, rtol=1.0e-5, atol=1.0e-8, obj="DataFrame")->None: | 参数默认值改变 | |
| pandas.to_datetime | def to_datetime(arg, errors='raise', dayfirst=False, yearfirst=False, utc=None, box=True, format=None, exact=True, unit=None, infer_datetime_format=False, origin='unix', cache=False): | def to_datetime(arg:DatetimeScalarOrArrayConvertible|DictConvertible, errors:DateTimeErrorChoices="raise", dayfirst:bool=False, yearfirst:bool=False, utc:bool|None=None, format:str|None=None, exact:bool=True, unit:str|None=None, infer_datetime_format:bool=False, origin="unix", cache:bool=True)->DatetimeIndex|Series|DatetimeScalar|NaTType|None: | 弃用box参数 | |
| pandas.to_pickle | def to_pickle(obj, path, compression='infer', protocol=pkl.HIGHEST_PROTOCOL): | def to_pickle(obj:Any, filepath_or_buffer:FilePath|WriteBuffer[bytes], compression:CompressionOptions="infer", protocol:int=pickle.HIGHEST_PROTOCOL, storage_options:StorageOptions=None) -> None: | protocol表示二进制数据序列化协议,Python3.5默认使用4版本协议,Python3.11默认使用5版本协议。使用5版本协议保存的pickle文件将无法在Python3.5版本读取。 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









