







1、查看配置文件
cd /usr/local/hadoop/hadoop-2.6.4/etc/hadoop
core-site.xml
hadoop-env.sh
hdfs-site.xml
slaves
yarn-env.sh
1) 、配置hadoop守护线程的参数(单机的操作)
vi core-site.xml
参数:fs.default.name
取值: NameNode的URL
备注: hdfs:// 主机名/
参数:mapred.job.tracker
取值: JobTracker的主机和端口
备注: 主机:端口
参数:dfs.name.dir
取值:NmaeNode持久储存名字的空间以及事务日志的本地文件的系统路径。
备注: 当这个值是一个逗号分隔的目录列表时,nametable诗句将会被复制到所有目录中做冗余备份。
参数:dfs.data.dir
取值: DataNode存放块数据的本地文件系统路径,逗号分隔的列表。
备注: 当这个值是逗号分隔的目录列表时,数据将储存在搜有目录下,分布在不同的设备上。
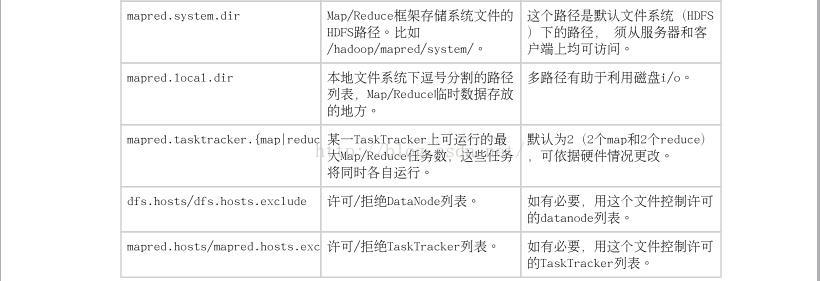
参数:mapred.system.dir
取值: Map/Reduce框架储存系统文件的HDFS路径,比如:/hadoop/mapred/system/
备注: 这个路径默认文件系统(hdfs) 下的路径,须从服务器和客户端均可访问。
参数:mapred.local.dir
取值: 本地文件系统下逗号分隔的路径列表,Map/Reduce临时数据存放的地方。
备注: 多路经有利于利用磁盘i/o
参数:mapred.tasktracker.{map/reduce}
取值: 某一TaskTracker上可运行的最大Map/Reduce任务数,这些任务将同时各自运行。
备注: 默认为2(2个map和2个Reduce),可依据硬件的情况更改。
参数:dfs.hosts/dfs.hosts.exclude
取值: 许可/拒绝DataNode列表
备注: 如必要,用这个文件控制DateNode列表
参数:mapred.hosts/mpred.hosts.exe
取值: 许可/拒绝TaskTracker列表
备注: 如有必要,用这个文件控制许可TaskTracker列表
具体如下:

现实世界中的集群配置:
这些事大规模集群上运行sort基准测试时使用到的一些非缺省的配置
运行sort900的一些非缺省配置值,sort900既在900个节点的集群上对9TB的数据进行排序
参数:dfs.block.size
取值:134217728
备注: 针对大文件系统,HDFS的快大小去128M
参数:dfs.namenode.handler.count
取值:40
备注:启动更多的NameNode服务线程去处理来自大量DataNode的RPC请求
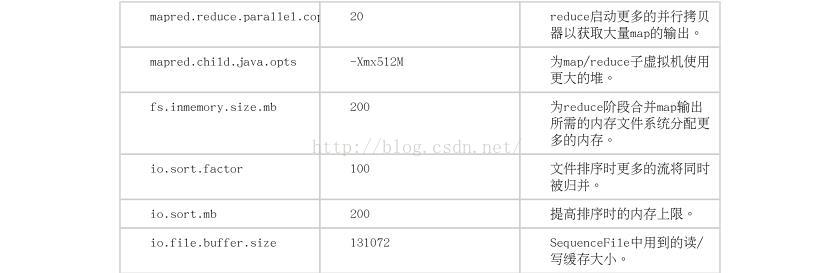
参数:mapred.reduce.parallel.com
取值:20
备注:reduce启动更多的并行拷贝器获取大量的Map的输出
参数:mapred.child.java.opts
取值:-Xmx512M
备注:位map/reduce子虚拟机使用更大的堆
参数:fs.inmemory.size.mb
取值:200
备注:位reduce阶段合并map输出所需的内存文件系统分配更多的内存
参数:io.sort.factor
取值:100
备注:文件排序更多的流将同时被归并
参数:io.sort.mb
取值:200
备注:提高排序时的内存的上限
参数:io.file.buffer.size
取值:131072
备注:sequenceFile中用到的读/写缓存的大小
下面是给予sort1400和sort2000时需要更新时的数据,
既在1400个节点上对14TB的数据进行排序和在2000个节点上对20TB的数据进行排序.
参数:mapred.jbo.tracker.handler
取值:60
备注:启动更多的JobTracker服务线程去处理来自大量的TaskTracker请求。
参数:mapred.reduce.paraller.com
取值:50
备注:
参数:tasktracker.http.threads
取值:50
备注:为TaskTracker的Http服务启动更多的工作线程,reduce通过http服务获取map的中间输出。
参数:mapred.child.java.opts
取值:-Xmx1024M
备注:使用更大的堆用于maps/reduces的子虚拟机



















 5266
5266

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











