







Research works related to defense against Spam over Internet Telephony consist of the following categories:
#1. Machine learning. This work uses semi-supervised machine learning for detection of SPIT calls. It extends K-Means algorithm to classify the callers. But they focus too much on the implementation of algorithm. It leverages too many features, many of which are difficult to obtain. And it rejects all the possible fraud calls, which violates the original purpose of VoIP.
#2. Filter model based on credits. There are some works use the interval/duration of a call to determine the callers’ and callees’ reputation. The papers consider that low-reputation customers always avoid talking too long, worrying about being discovered. I don’t think it’s a reasonable way because it costs much time to gain the victims’ belief. Some others
#3. Filter model on the basis of user patterns. Namely, through the call habits (such as the frequency of incoming calls and outgoing calls), we can evaluate and establish the user’s profile of call activity, which can be used to determine the good or bad callers (e.g., as for a bad caller, he always/almost has few outgoing calls instead of incoming calls).
#4. Other work tries to establish a call record reservation system in the cloud, which is expensive. It proposes to implement a communication and reservation server added in the existed telephony infrastructures and then transfer the collected data into cloud to analyze.
In my opinion, most existed works have noticed the importance of SPIT. However, there are few works aimed at the spoofed caller id fraud. Most of them lack a detailed and specific solution. I intend to secure people from vishing with two-side protection,rejection and real-time warning. Rejection takes before alerting the callees via the mismatching between the specified caller IDs and their URIs. Real-time warning is implemented by an attestation of identified spoofed id in the attestation center in the cloud.
CCS’10: PinDr0p: Using Single-Ended Audio Features To Determine Call Provenance.
Research background: The current telephony infrastructure allows users to communicate using a variety of technologies, mainly classified into 3 categories: PSTN, cellular and VoIP.
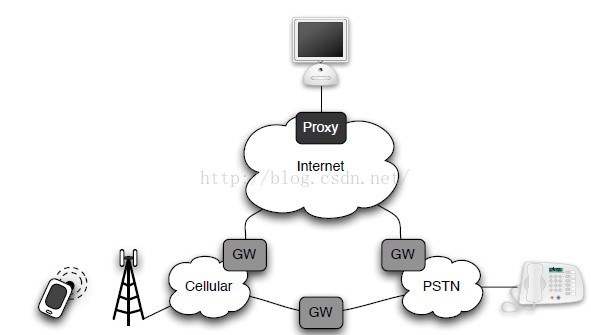
Terminologies explanation
PSTN represents traditional circuit-switched telephony, which supports lossless connections and high fidelity audio.
VoIP runs on top of IP links and generally shares the same paths as all other Internet-based traffic.
Cellular can be treated as the mixture of PSTN and VoIP, namely it is the PSTN network with partial replacement of the Internet.
Voice is encoded and decoded in each of these networks using a variety of codecs and they use different codecs. Thus, transition of these codecs take place frequently.
Research Issue: The diversification of telephony technologies admits a call data transfer without verification, namely call ID spoofing,which can be exploited by scammers to criminalize victims.
Research Solution: This paper aims at identifying the provenance of a call. The authors believe that the data loss of these codecs transitions can be manipulated by the scammers although they can modify the phone number.Thus, they analyze the data loss of the call data while being transformed among different telephony networks. And then use neural algorithm to classify the call provenance by the data loss profile.
One interesting method is that they measure data loss by conserving the energy trace of the signal instead of analyzing the datagram. Namely, it’s sometime convenient to obtain one’s profile in another perspective. Energy. Energy!















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









