







HTTP
HTTP是一个客户端(用户)和服务器端(网站)之间进行请求和应答的标准。通过使用网页浏览器、网络爬虫或者其他工具,客户端可以向服务器上的指定端口(默认端口为80)发起一个HTTP请求。这个客户端成为客户代理(user agent)。应答服务器上存储着一些资源码,比如HTML文件和图像。这个应答服务器成为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。尽管TCP/IP是互联网最流行的协议,但HTTP中并没有规定必须使用它或它支持的层。
事实上。HTTP可以在互联网协议或其他网络上实现。HTTP假定其下层协议能够提供可靠的传输,因此,任何能够提供这种保证的协议都可以使用。使用TCP/IP协议族时RCP作为传输层。通常由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP链接。HTTP服务器则在该端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态(比如“THTTP/1.1 200 OK”),以及请求的文件、错误信息等响应内容。
HTTP的请求方法有很多种,主要包括以下几个:
-
GET:向指定的资源发出“显示”请求。GET方法应该只用于读取数据,而不应当被用于“副作用”的操作中(例如在Web Application中)。其中一个原因是GET可能会被网络蜘蛛等随意访问。
-
HEAD:与GET方法一样,都是向服务器发出直顶资源的请求,只不过服务器将不会出传回资源的内容部分。它的好处在于,使用这个方法可以在不必传输内容的情况下,将获取到其中“关于该资源的信息”(元信息或元数据)。
-
POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求文本中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
-
PUT:向指定资源位置上传输最新内容。
-
DELETE:请求服务器删除Request-URL所标识的资源,或二者皆有。
-
TRACE:回显服务器收到的请求,主要用于测试或诊断。
-
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用“*”来代表资源名称向Web服务器发送OPTIONS请求,可以测试服务器共能是否正常。
-
CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的连接(经由非加密的HTTP代理服务器)。方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
requests.get
一个网络爬虫程序最普遍的过程:
1.访问站点;
2.定位所需的信息;
3.得到并处理信息。
import requests
url = 'https://www.python.org/dev/peps/pep-0020/'
res = requests.get(url)
text = res.text
text
可以看到返回的其实就是开发者工具下Elements的内容,只不过是字符串类型,接下来我们要用python的内置函数find来定位“python之禅”的索引,然后从这段字符串中取出它
通过观察网站,我们可以发现这段话在一个特殊的容器中,通过审查元素,使用快捷键Ctrl+shift+c快速定位到这段话也可以发现这段话包围在pre标签中,因此我们可以由这个特定用find函数找出具体内容
< pre >标签可定义预格式化的文本。 被包围在 < pre > 标签 元素中的文本通常会保留空格和换行符。而文本也会呈现为等宽字体。
## 爬取python之禅并存入txt文件
with open('zon_of_python.txt', 'w') as f:
f.write(text[text.find('<pre')+28:text.find('</pre>')-1])
print(text[text.find('<pre')+28:text.find('</pre>')-1])
Beautiful is better than ugly.
Explicit is better than implicit.
Simple is better than complex.
…
urllib是python3的标准库,包含了很多基本功能,比如向网络请求数据、处理cookie、自定义请求头等,显然,就代码量而言,urllib的工作量比Requests要大,而且看起来也不甚简洁。
requests.post
首先进入金山词霸首页http://www.iciba.com/
然后打开开发者工具下的“Network”,翻译一段话,比如刚刚我们爬到的第一句话“Beautiful is better than ugly.”
点击翻译后可以发现Name下多了一项请求方法是POST的数据,点击Preview可以发现数据中有我们想要的翻译结果
 我们目前需要用到的两部分信息是Request Headers中的User-Agent,和Form Data
我们目前需要用到的两部分信息是Request Headers中的User-Agent,和Form Data

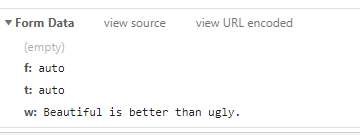
信息都能采集到到,所以我们利用金山词霸来翻译我们刚刚爬出来的python之禅
import requests
def translate(word):
url="http://fy.iciba.com/ajax.php?a=fy"
data={
'f': 'auto',
't': 'auto',
'w': word,
}
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36',
}#User-Agent会告诉网站服务器,访问者是通过什么工具来请求的,如果是爬虫请求,一般会拒绝,如果是用户浏览器,就会应答。
response = requests.post(url,data=data,headers=headers) #发起请求
json_data=response.json() #获取json数据
#print(json_data)
return json_data
def run(word):
result = translate(word)['content']['out']
print(result)
return result
def main():
with open('zon_of_python.txt') as f:
zh = [run(word) for word in f]
with open('zon_of_python_zh-CN.txt', 'w') as g:
for i in zh:
g.write(i + '\n')
if __name__ == '__main__':
main()
request.get进阶:爬取豆瓣电影
import requests
import os
if not os.path.exists('image'):
os.mkdir('image')
def parse_html(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36"}
res = requests.get(url, headers=headers)
text = res.text
item = []
for i in range(25):
text = text[text.find('alt')+3:]
item.append(extract(text))
return item
def extract(text):
text = text.split('"')
name = text[1]
image = text[3]
return name, image
def write_movies_file(item, stars):
print(item)
with open('douban_film.txt','a',encoding='utf-8') as f:
f.write('排名:%d\t电影名:%s\n' % (stars, item[0]))
r = requests.get(item[1])
with open('image/' + str(item[0]) + '.jpg', 'wb') as f:
f.write(r.content)
def main():
stars = 1
for offset in range(0, 250, 25):
url = 'https://movie.douban.com/top250?start=' + str(offset) +'&filter='
for item in parse_html(url):
write_movies_file(item, stars)
stars += 1
if __name__ == '__main__':
main()
使用API
信息网址:http://lbsyun.baidu.com/apiconsole/key
创建一个html文件,例如test.html,复制下面代码,输入自己的AK
<!DOCTYPE html>
<html>
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<meta name="viewport" content="initial-scale=1.0, user-scalable=no" />
<style type="text/css">
body,
html,
#allmap {
width: 100%;
height: 100%;
overflow: hidden;
margin: 0;
font-family: "微软雅黑";
}
</style>
<script type="text/javascript" src="http://api.map.baidu.com/api?v=3.0&ak="></script> //在 ak=后面输入你的ak
<title>地图展示</title>
</head>
<body>
<div id="allmap"></div>
</body>
</html>
<script type="text/javascript">
// 百度地图API功能
var map = new BMap.Map("allmap"); // 创建Map实例
map.centerAndZoom(new BMap.Point(116.404, 39.915), 11); // 初始化地图,设置中心点坐标和地图级别
//添加地图类型控件
map.addControl(new BMap.MapTypeControl({
mapTypes: [
BMAP_NORMAL_MAP,
BMAP_HYBRID_MAP
]
}));
map.setCurrentCity("北京"); // 设置地图显示的城市 此项是必须设置的
map.enableScrollWheelZoom(true); //开启鼠标滚轮缩放
</script>
实现地理编码功能:
import requests
def getUrl(*address):
ak = '' ## 填入你的api key
if len(address) < 1:
return None
else:
for add in address:
url = 'http://api.map.baidu.com/geocoding/v3/?address={0}&output=json&ak={1}'.format(add,ak)
yield url
def getPosition(url):
'''返回经纬度信息'''
res = requests.get(url)
#print(res.text)
json_data = eval(res.text)
if json_data['status'] == 0:
lat = json_data['result']['location']['lat'] #纬度
lng = json_data['result']['location']['lng'] #经度
else:
print("Error output!")
return json_data['status']
return lat,lng
if __name__ == "__main__":
address = ['北京市清华大学','北京市北京大学','保定市华北电力大学','上海市复旦大学','武汉市武汉大学']
for add in address:
add_url = list(getUrl(add))[0]
print('url:', add_url)
try:
lat,lng = getPosition(add_url)
print("{0}|经度:{1}|纬度:{2}.".format(add,lng,lat))
except Error as e:
print(e)















 1593
1593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









