







加载TMDB数据集
TMDb电影数据库”,数据集中包含来自1960-2016年上映的近11000部电影的基本信息,主要包括了电影类型、预算、票房、演职人员、时长、评分等信息。
本文作为自学练习小项目,将从最原始的数据格式化、数据清洗、数据分析进行全面的学习
并且事无巨细,展示练习全过程
参考文章 https://blog.csdn.net/moyue1002/article/details/80332186
python 3.7
pandas 0.23
numpy 1.18
metplotlib 2.2
import pandas as pd
credits = pd.read_csv('./tmdb_5000_credits.csv')
movies = pd.read_csv('./tmdb_5000_movies.csv')
查看各个dataframe的一般信息
# 这是movies表的信息
movies.head(1)
print(movies.info())
Out[3]:
budget genres homepage id ... tagline title vote_average vote_count
0 237000000 [{"id": 28, "name": "Action"}, {"id": 12, "nam... http://www.avatarmovie.com/ 19995 ... Enter the World of Pandora. Avatar 7.2 11800
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 20 columns):
budget 4803 non-null int64
genres 4803 non-null object
homepage 1712 non-null object
id 4803 non-null int64
keywords 4803 non-null object
original_language 4803 non-null object
original_title 4803 non-null object
overview 4800 non-null object
popularity 4803 non-null float64
production_companies 4803 non-null object
production_countries 4803 non-null object
release_date 4802 non-null object
revenue 4803 non-null int64
runtime 4801 non-null float64
spoken_languages 4803 non-null object
status 4803 non-null object
tagline 3959 non-null object
title 4803 non-null object
vote_average 4803 non-null float64
vote_count 4803 non-null int64
dtypes: float64(3), int64(4), object(13)
memory usage: 750.5+ KB
None
这是credits表的信息
print(credits.info())
credits.head(1)
Out[4]:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 4 columns):
movie_id 4803 non-null int64
title 4803 non-null object
cast 4803 non-null object
crew 4803 non-null object
dtypes: int64(1), object(3)
memory usage: 150.2+ KB
None
movie_id ... crew
0 19995 ... [{"credit_id": "52fe48009251416c750aca23", "de...
credits表的cast列很奇怪,数据很多
进行具体查看
# 查看credists表的cast列索引0的值,发现是一长串东西
print('cast格式:', type(credits['cast'][0])) # 查看其类型,为`str`类型,无法处理
Out[5]:
cast格式: <class 'str'>
json格式化数据处理
从表中看出,cast列其实是json格式化数据,应该用json包进行处理
json格式是[{},{}]
将json格式的字符串转换成Python对象用json.loads()
json.load()针对的是文件,从文件中读取json
import json
type(json.loads(credits['cast'][0]))
Out[6]:
list
从上面可以看出json.loads()将json字符串转成了list,可以知道list里面又包裹多个dict
接下来批量处理
import json
json_col = ['cast','crew']
for i in json_col:
credits[i] = credits[i].apply(json.loads)
credits['cast'][0][:3]
Out[7]:
[{'cast_id': 242,
'character': 'Jake Sully',
'credit_id': '5602a8a7c3a3685532001c9a',
'gender': 2,
'id': 65731,
'name': 'Sam Worthington',
'order': 0},
{'cast_id': 3,
'character': 'Neytiri',
'credit_id': '52fe48009251416c750ac9cb',
'gender': 1,
'id': 8691,
'name': 'Zoe Saldana',
'order': 1},
{'cast_id': 25,
'character': 'Dr. Grace Augustine',
'credit_id': '52fe48009251416c750aca39',
'gender': 1,
'id': 10205,
'name': 'Sigourney Weaver',
'order': 2}]
print('再次查看cast类型是:',type(credits['cast'][0]))
# 数据类型变成了list,可以用于循环处理
Out[8]:
再次查看cast类型是: <class 'list'>
提取其中的名字
credits['cast'][0][:3]
# credits第一行的cast,是个列表
Out[9]:
[{'cast_id': 242,
'character': 'Jake Sully',
'credit_id': '5602a8a7c3a3685532001c9a',
'gender': 2,
'id': 65731,
'name': 'Sam Worthington',
'order': 0},
{'cast_id': 3,
'character': 'Neytiri',
'credit_id': '52fe48009251416c750ac9cb',
'gender': 1,
'id': 8691,
'name': 'Zoe Saldana',
'order': 1},
{'cast_id': 25,
'character': 'Dr. Grace Augustine',
'credit_id': '52fe48009251416c750aca39',
'gender': 1,
'id': 10205,
'name': 'Sigourney Weaver',
'order': 2}]
credits['cast'][0][0]['name'] # 获取第一行第一个字典的人名
Out[10]:
'Sam Worthington'
dict字典常用的函数
dict.get() 返回指定键的值,如果值不在字典中返回default值
dict.items() 以列表返回可遍历的(键, 值) 元组数组
# 代码测试如下:
i = credits['cast'][0][0]
for x in i.items():
print(x)
Out[11]:
('cast_id', 242)
('character', 'Jake Sully')
('credit_id', '5602a8a7c3a3685532001c9a')
('gender', 2)
('id', 65731)
('name', 'Sam Worthington')
('order', 0)
创建get_names()函数,进一步分割cast
def get_names(x):
return ','.join(i['name'] for i in x)
credits['cast'] = credits['cast'].apply(get_names)
credits['cast'][:3]
Out[12]:
0 Sam Worthington,Zoe Saldana,Sigourney Weaver,S...
1 Johnny Depp,Orlando Bloom,Keira Knightley,Stel...
2 Daniel Craig,Christoph Waltz,Léa Seydoux,Ralph...
Name: cast, dtype: object
crew提取导演
credits['crew'][0][0]
Out[13]:
{'credit_id': '52fe48009251416c750aca23',
'department': 'Editing',
'gender': 0,
'id': 1721,
'job': 'Editor',
'name': 'Stephen E. Rivkin'}
# 需要创建循环,找到job是director的,然后读取名字并返回
def director(x):
for i in x:
if i['job'] == 'Director':
return i['name']
credits['crew'] = credits['crew'].apply(director)
print(credits[['crew']][:3])
credits.rename(columns = {'crew':'director'},inplace=True) #修改列名
credits[['director']][:3]
Out[[14]:
crew
0 James Cameron
1 Gore Verbinski
2 Sam Mendes
movies表进行json解析
>>> movies.head(1)
budget genres homepage id ... tagline title vote_average vote_count
0 237000000 [{"id": 28, "name": "Action"}, {"id": 12, "nam... http://www.avatarmovie.com/ 19995 ... Enter the World of Pandora. Avatar 7.2 11800
可以看出genres, keywords, spoken_languages, production_countries, producion_companies需要json解析的
# 方法同crew表
json_col = ['genres','keywords','spoken_languages','production_countries','production_companies']
for i in json_col:
movies[i] = movies[i].apply(json.loads)
movies[i] = movies[i].apply(get_names)
>>> movies.head(1)
budget genres homepage id ... tagline title vote_average vote_count
0 237000000 Action,Adventure,Fantasy,Science Fiction http://www.avatarmovie.com/ 19995 ... Enter the World of Pandora. Avatar 7.2 11800
开始分析数据
credits.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 4 columns):
movie_id 4803 non-null int64
title 4803 non-null object
cast 4803 non-null object
director 4773 non-null object
dtypes: int64(1), object(3)
memory usage: 150.2+ KB
movies.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 4803 entries, 0 to 4802
Data columns (total 20 columns):
budget 4803 non-null int64
genres 4803 non-null object
homepage 1712 non-null object
id 4803 non-null int64
keywords 4803 non-null object
original_language 4803 non-null object
original_title 4803 non-null object
overview 4800 non-null object
popularity 4803 non-null float64
production_companies 4803 non-null object
production_countries 4803 non-null object
release_date 4802 non-null object
revenue 4803 non-null int64
runtime 4801 non-null float64
spoken_languages 4803 non-null object
status 4803 non-null object
tagline 3959 non-null object
title 4803 non-null object
vote_average 4803 non-null float64
vote_count 4803 non-null int64
dtypes: float64(3), int64(4), object(13)
memory usage: 750.5+ KB
credits和movies都有一个id和title,他们是不是同一个东西?
检测一下
(credits['movie_id'] == movies['id']).describe()
count 4803
unique 1
top True
freq 4803
dtype: object
(credits['title'] == movies['title']).describe()
count 4803
unique 1
top True
freq 4803
Name: title, dtype: object
两列相同,合并数据
df = credits.merge(right=movies,how='inner',left_on='movie_id',right_on='id')
>>> df.head()
movie_id title_x ... vote_average vote_count
0 19995 Avatar ... 7.2 11800
1 285 Pirates of the Caribbean: At World's End ... 6.9 4500
2 206647 Spectre ... 6.3 4466
3 49026 The Dark Knight Rises ... 7.6 9106
4 49529 John Carter ... 6.1 2124
df中有24个字段
movie_id:TMDB电影标识号
title_x & title_y: 这是合并时形成的两个一样的列,可删除一列,电影名称
cast:演员列表
direcor:导演
budget:预算
genres:电影风格
homepages:电影URL
id:同movie_id
original_language:电影语言
overview:剧情摘要
popularity:在database上的点击次数
production_companies:制作公司
production_countries:制作国家
release_date:上映时间
spoken_languages:口语
status:状态
tagline:电影标语
vote_average:平均评分
vote_count:评分次数
df.info()
# df[['movie_id','id']]
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4803 entries, 0 to 4802
Data columns (total 24 columns):
movie_id 4803 non-null int64
title_x 4803 non-null object
cast 4803 non-null object
director 4773 non-null object
budget 4803 non-null int64
genres 4803 non-null object
homepage 1712 non-null object
id 4803 non-null int64
keywords 4803 non-null object
original_language 4803 non-null object
original_title 4803 non-null object
overview 4800 non-null object
popularity 4803 non-null float64
production_companies 4803 non-null object
production_countries 4803 non-null object
release_date 4802 non-null object
revenue 4803 non-null int64
runtime 4801 non-null float64
spoken_languages 4803 non-null object
status 4803 non-null object
tagline 3959 non-null object
title_y 4803 non-null object
vote_average 4803 non-null float64
vote_count 4803 non-null int64
dtypes: float64(3), int64(5), object(16)
memory usage: 938.1+ KB
字段缺失值处理
del df['title_y']
del df['id']
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4803 entries, 0 to 4802
Data columns (total 22 columns):
movie_id 4803 non-null int64
title_x 4803 non-null object
cast 4803 non-null object
director 4773 non-null object
budget 4803 non-null int64
genres 4803 non-null object
homepage 1712 non-null object
keywords 4803 non-null object
original_language 4803 non-null object
original_title 4803 non-null object
overview 4800 non-null object
popularity 4803 non-null float64
production_companies 4803 non-null object
production_countries 4803 non-null object
release_date 4802 non-null object
revenue 4803 non-null int64
runtime 4801 non-null float64
spoken_languages 4803 non-null object
status 4803 non-null object
tagline 3959 non-null object
vote_average 4803 non-null float64
vote_count 4803 non-null int64
dtypes: float64(3), int64(4), object(15)
memory usage: 863.0+ KB
同时,从上面可以看到director,release_date,runtime有缺失值
director无法处理,只能处理release_date,runtime的缺失值
另外,homepage,original_tille,overview,spoken_language,tagline这几列数据我们也是用不到的,可以删除
df['release_date']=df['release_date'].fillna('2014-06-01')
df['runtime']=df['runtime'].fillna(df['runtime'].mean())
>>> df[['release_date','runtime']].isnull().describe()
release_date runtime
count 4803 4803
unique 1 1
top False False
freq 4803 4803
>>> df.head(3)
movie_id title_x ... vote_average vote_count
0 19995 Avatar ... 7.2 11800
1 285 Pirates of the Caribbean: At World's End ... 6.9 4500
2 206647 Spectre ... 6.3 4466
数据分析及可视化
处理日期时间
df.info()
<class 'pandas.core.frame.DataFrame'>
Int64Index: 4803 entries, 0 to 4802
Data columns (total 22 columns):
movie_id 4803 non-null int64
title_x 4803 non-null object
cast 4803 non-null object
director 4773 non-null object
budget 4803 non-null int64
genres 4803 non-null object
homepage 1712 non-null object
keywords 4803 non-null object
original_language 4803 non-null object
original_title 4803 non-null object
overview 4800 non-null object
popularity 4803 non-null float64
production_companies 4803 non-null object
production_countries 4803 non-null object
release_date 4803 non-null object
revenue 4803 non-null int64
runtime 4803 non-null float64
spoken_languages 4803 non-null object
status 4803 non-null object
tagline 3959 non-null object
vote_average 4803 non-null float64
vote_count 4803 non-null int64
dtypes: float64(3), int64(4), object(15)
memory usage: 863.0+ KB
# 从上面可以看出,release_time是object格式,因此要先转化为时间格式
df['release_year'] = pd.to_datetime(df.release_date,format='%Y-%m-%d').dt.year
df['release_month'] = pd.to_datetime(df.release_date,format='%Y-%m-%d').dt.month
>>> df.head(3)
movie_id title_x cast ... vote_count release_year release_month
0 19995 Avatar Sam Worthington,Zoe Saldana,Sigourney Weaver,S... ... 11800 2009 12
1 285 Pirates of the Caribbean: At World's End Johnny Depp,Orlando Bloom,Keira Knightley,Stel... ... 4500 2007 5
2 206647 Spectre Daniel Craig,Christoph Waltz,Léa Seydoux,Ralph... ... 4466 2015 10
电影类型分析
df['genres'][1].split(',') #split()分割字符串
['Adventure', 'Fantasy', 'Action']
set()可创建一个集合,集合的最重要特性是元素不可重复性
因此可以以此来得到电影所有类型总共归属于哪些
genre = set()
for i in df['genres'].str.split(','):
genre=set().union(i,genre) # union()可以将i和genre合并到一起
genre
{'',
'Action',
'Adventure',
'Animation',
'Comedy',
'Crime',
'Documentary',
'Drama',
'Family',
'Fantasy',
'Foreign',
'History',
'Horror',
'Music',
'Mystery',
'Romance',
'Science Fiction',
'TV Movie',
'Thriller',
'War',
'Western'}
# 将上述集合转为list,并去除无用的‘’
genre = list(genre)
genre.remove('')
genre
['War',
'History',
'Science Fiction',
'Foreign',
'Western',
'Action',
'Comedy',
'Family',
'Documentary',
'Animation',
'Romance',
'Drama',
'Mystery',
'Music',
'Fantasy',
'Horror',
'TV Movie',
'Adventure',
'Thriller',
'Crime']
电影类型和数量
for i in genre:
df[i] = 0 # 创建名为i的列
df[i][df.genres.str.contains(i)] = 1 #genres列包含字符i时,赋值为1
>>> df.head(8)
movie_id title_x cast director ... Fantasy Romance Horror Foreign
0 19995 Avatar Sam Worthington,Zoe Saldana,Sigourney Weaver,S... James Cameron ... 1 0 0 0
1 285 Pirates of the Caribbean: At World's End Johnny Depp,Orlando Bloom,Keira Knightley,Stel... Gore Verbinski ... 1 0 0 0
2 206647 Spectre Daniel Craig,Christoph Waltz,Léa Seydoux,Ralph... Sam Mendes ... 0 0 0 0
3 49026 The Dark Knight Rises Christian Bale,Michael Caine,Gary Oldman,Anne ... Christopher Nolan ... 0 0 0 0
4 49529 John Carter Taylor Kitsch,Lynn Collins,Samantha Morton,Wil... Andrew Stanton ... 0 0 0 0
5 559 Spider-Man 3 Tobey Maguire,Kirsten Dunst,James Franco,Thoma... Sam Raimi ... 1 0 0 0
6 38757 Tangled Zachary Levi,Mandy Moore,Donna Murphy,Ron Perl... Byron Howard ... 0 0 0 0
7 99861 Avengers: Age of Ultron Robert Downey Jr.,Chris Hemsworth,Mark Ruffalo... Joss Whedon ... 0 0 0 0
# 这里有另外一种更好的方法:
# for i in genre:
# df[i] = df['genres'].str.contains(i).apply(lambda x:1 if x else 0)
建立包含电影类型和年份的dataframe
df_gy = df[genre+['release_year']]
>>> df_gy.head(10)
War Thriller Animation Action Adventure Music Science Fiction Documentary ... Family Drama Mystery Fantasy Romance Horror Foreign release_year
0 0 0 0 1 1 0 1 0 ... 0 0 0 1 0 0 0 2009
1 0 0 0 1 1 0 0 0 ... 0 0 0 1 0 0 0 2007
2 0 0 0 1 1 0 0 0 ... 0 0 0 0 0 0 0 2015
3 0 1 0 1 0 0 0 0 ... 0 1 0 0 0 0 0 2012
4 0 0 0 1 1 0 1 0 ... 0 0 0 0 0 0 0 2012
5 0 0 0 1 1 0 0 0 ... 0 0 0 1 0 0 0 2007
6 0 0 1 0 0 0 0 0 ... 1 0 0 0 0 0 0 2010
7 0 0 0 1 1 0 1 0 ... 0 0 0 0 0 0 0 2015
8 0 0 0 0 1 0 0 0 ... 1 0 0 1 0 0 0 2009
9 0 0 0 1 1 0 0 0 ... 0 0 0 1 0 0 0 2016
可视化电影年度趋势
import matplotlib.pyplot as plt
x = df_gy['release_year'].value_counts().sort_index()
plt.plot(x) # 绘制电影数与时间的总的密度图
plt.xlabel('Time (year)')
plt.ylabel('Counts')
plt.show()
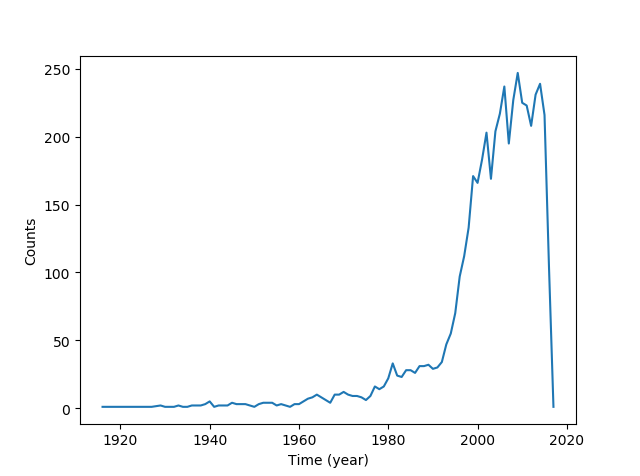
绘制分类型电影-时间图
x = df_gy.groupby('release_year').sum(axis = 1)
plt.figure(figsize=(12,6))
plt.xticks(range(1915,2018,5))
plt.plot(x)
plt.legend(x.columns.values,fontsize = 9)
plt.xlabel('Time (year)')
plt.ylabel('Counts')
plt.show()
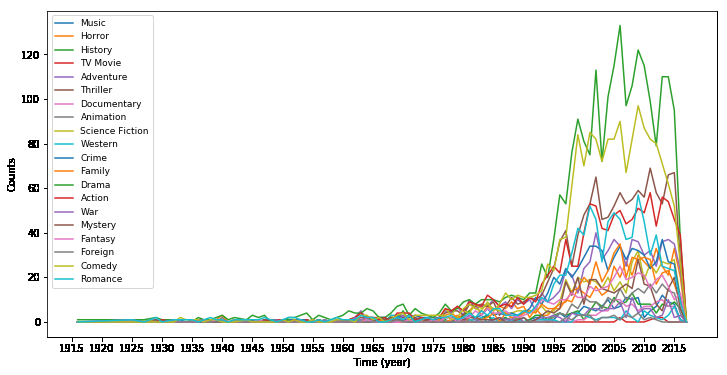
绘制电影总量柱状图
y = x.sum().sort_values()
plt.figure(figsize=(12,6))
plt.xlabel('Counts',fontsize = 15)
plt.ylabel('Category',fontsize = 15)
plt.barh(y.index,y)
plt.show()
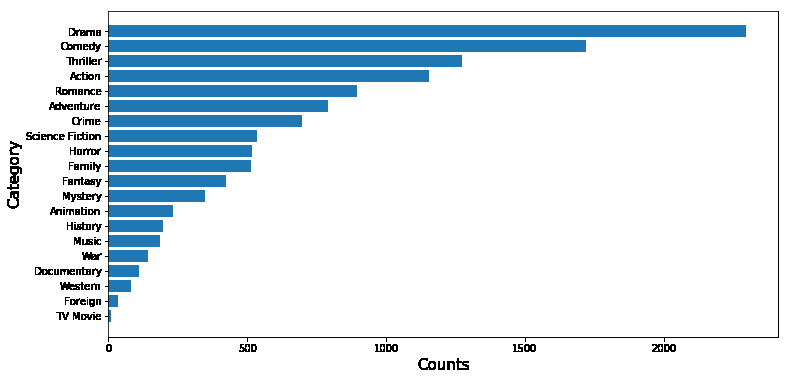
饼状图
bl = y / y.sum()
plt.figure(figsize=(6,6))
plt.pie(bl,labels=bl.index,autopct='%1.1f%%',explode=(bl>=0.06)/20+0.02)
plt.title('Pie of Category')
plt.show()
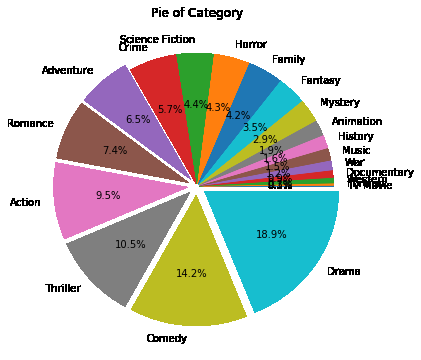
分析电影票房与哪些因素有关
df_revenue = df.groupby('release_year')['revenue'].sum() # 统计票房
df_revenue[:5]
release_year
1916 8394751
1925 22000000
1927 650422
1929 4358000
1930 8000000
Name: revenue, dtype: int64
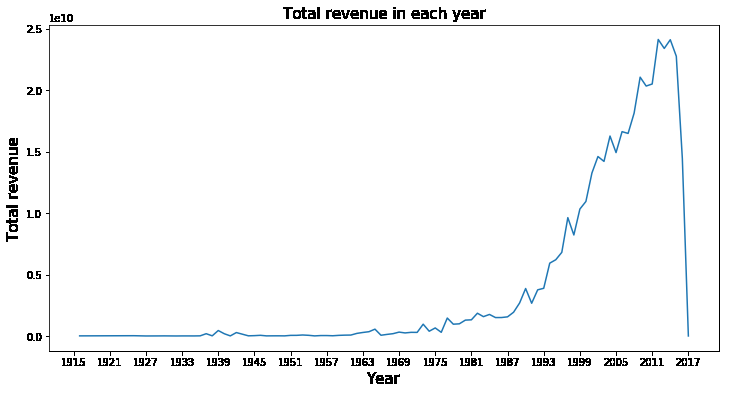
年份和票房
df_revenue.plot(figsize=(12,6))
plt.xticks(range(1915,2018,6))
plt.title('Total revenue in each year',fontsize = 15)
plt.xlabel('Year',fontsize = 15)
plt.ylabel('Total revenue',fontsize = 15)
plt.show()
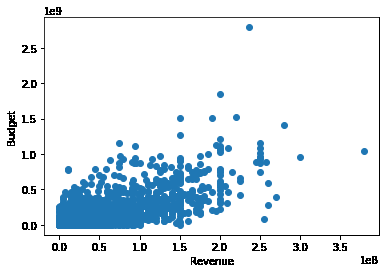
电影预算和票房的关系
plt.scatter(x=df.budget,y = df.revenue)
plt.xlabel('Revenue')
plt.ylabel('Budget')
plt.show()
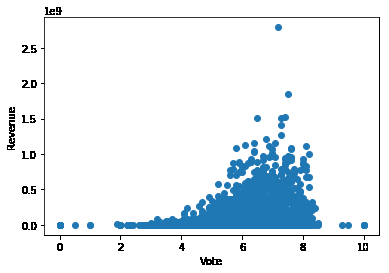
评分和票房的关系
plt.scatter(x = df.vote_average,y = df.revenue)
plt.xlabel('Vote')
plt.ylabel('Revenue')
plt.show()
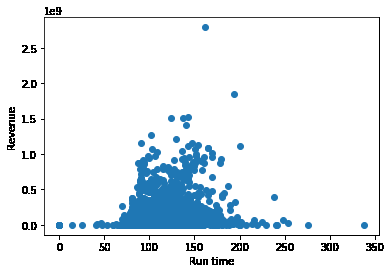
电影时长和票房的关系
plt.scatter(df.runtime,df.revenue)
plt.xlabel('Run time')
plt.ylabel('Revenue')
plt.show()
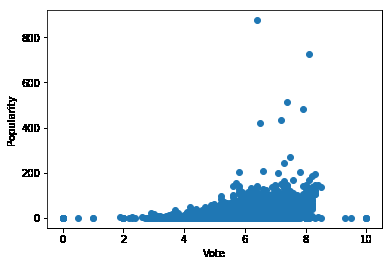
评分和受欢迎程度
plt.scatter(df.vote_average,df.popularity)
plt.xlabel('Vote')
plt.ylabel('Popularity')
plt.show()
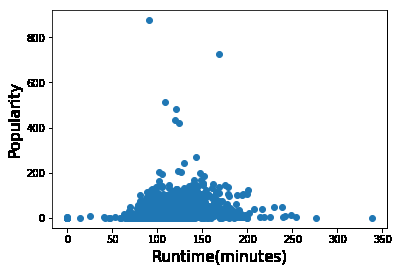
时长和受欢迎程度
plt.scatter(df.runtime,df.popularity)
plt.xlabel('Runtime(minutes)',fontsize = 15)
plt.ylabel('Popularity',fontsize = 15)
plt.show() # 看起来观众更喜欢60-160之间的电影















 1743
1743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









