







本博客知识记录自己学习中的笔记或者记录,如果有错误欢迎大家纠正。
本节学习c++11的新特性lambda表达式
10.14 编写lambda表达式,接收两个int返回他们的和
代码如下
#include <iostream>
int main()
{
//定义一个函数指针 指向lambda表达式,捕获列表为空。
//注意两个分号
auto fun = [](int a, int b){return a + b; };
//调用函数指针,并传入参数1和2
auto c = fun(1, 2);
std::cout << c << std::endl;
//保持窗口显示
std::cin.get();
return 0;
}输出结果为:

10.15编写一个lambda,捕获它所在函数的int,并接受一个int参数。lambda应该返回捕获的int和int参数的和。
#include <iostream>
int main()
{
//在main函数里定义一个int
int a = 1;
//在捕获列表中以引用的方式使用变量a,并返回他们的和
auto fun = [&a](int b){return a + b; };
auto c = fun(2);
std::cout << c << std::endl;
std::cin.get();
return 0;
}输出结果为

10.16使用lambda编写你自己版本的biggies。
原本程序代码如下,因为在原本biggies中以大量使用了lambda表达式,我这里就不改写了,吧这个程序补充完整让biggies能够运行。
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
//将words按字典排序,删除重复单词
void elimDups(std::vector<std::string> &words)
{
//排序
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end());
}
//make_plural(wc, "word ", "s ")当输入中文本中word数大于一是在word后加s,为words为word的复数!该函数是作者在前面章节自己定义的一个函数,因为跳着看 一直没注意到,自己写了一个
std::string make_plural(size_t ctr, const std::string &word, const std::string &ending)
{
return (ctr == 1) ? word : word + ending;
}
//这个已经使用了lambda表达式,我就不再改写
void biggies(std::vector<std::string> &words,
std::vector<std::string>::size_type sz)
{
elimDups(words);//将words按字典排序,删除重复单词
//按长度排序,长度相同的单词维持字典排序
stable_sort(words.begin(), words.end(),
[](const std::string &a, const std::string &b)
{return a.size() < b.size(); });
//获取一个迭代器,指向第一个满足size()>=sz的元素
auto wc = find_if(words.begin(), words.end(),
[sz](const std::string &a)
{return a.size() >= sz; });
//计算满足size>=sz的元素的数目
auto count = words.end() - wc;
std::cout << count << " "<< make_plural(count, "word", "s")
<< "of length " << sz << " or longer " << std::endl;
//打印长度大于等于给定值的单词,每个单词后面节一个空格
for_each(wc, words.end(),
[](const std::string &s){std::cout << s << " "; });
std::cout << std::endl;
}
int main()
{
std::vector<std::string>vecString;
std::string s = "";
//注意在win下使用ctrl+z结束输入
while (std::cin >> s)
{
vecString.push_back(s);
}
biggies(vecString, 4);
//std::cin.get();
system("pause");
return 0;
}输出结果为:
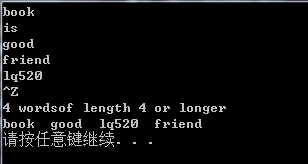
10.17重写10.3.1节练习10.12的程序,在对sort的调用中使用lambda来代替compareIsbn。
#include <vector>
#include <string>
#include "stdlib.h"
#include <iostream>
#include <iterator>
#include <algorithm>
#include "10.12.h"
void pritef(std::vector<Sales_data> &word)
{
for (auto s : word)
std::cout << s.ISBN<<" "<<s.revenue<<" "<<s.units_sold <<std::endl;
std::cout << std::endl;
}
bool isShorter(const Sales_data &s1, const Sales_data &s2)
{
return s1.ISBN.size() < s2.ISBN.size();
}
int main()
{
Sales_data book;
std::vector<Sales_data>vecSale;
while (std::cin >> book)
vecSale.push_back(book);
//正常调用
//stable_sort(vecSale.begin(), vecSale.end(), isShorter);
//使用lambda表达式
stable_sort(vecSale.begin(), vecSale.end(),
[](const Sales_data &s1, const Sales_data &s2)
{return s1.ISBN.size() < s2.ISBN.size(); });
pritef(vecSale);
system("pause");
return 0;
}10.18重写biggies,用partition代替find_if。在10.13中介绍了partition算法。
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
//将words按字典排序,删除重复单词
void elimDups(std::vector<std::string> &words)
{
//排序
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end());
}
//make_plural(wc, "word ", "s ")当输入中文本中word数大于一是在word后加s,为words为word的复数!
std::string make_plural(size_t ctr, const std::string &word, const std::string &ending)
{
return (ctr == 1) ? word : word + ending;
}
//原版
void biggies(std::vector<std::string> &words,
std::vector<std::string>::size_type sz)
{
elimDups(words);//将words按字典排序,删除重复单词
//按长度排序,长度相同的单词维持字典排序
stable_sort(words.begin(), words.end(),
[](const std::string &a, const std::string &b)
{return a.size() < b.size(); });
/*partition的算法,它接收一个谓词,对容器内容精选划分,使得谓词为true的值会排在容器前半段,而使谓词为false的值会排在后半段,算法返回一个迭代器,指向最后一个使谓词为true 的元素之后的位置位置*/
//获取一个迭代器,指向第一个满足size()>=sz的元素
auto wc = partition(words.begin(), words.end(),
[sz](const std::string &a)
{return a.size() < sz; });//注意同时应该改变比较值
//计算满足size>=sz的元素的数目
auto count = words.end() - wc;
std::cout << count << " "<< make_plural(count, "word", "s")
<< " of length " << sz << " or longer " << std::endl;
//打印长度大于等于给定值的单词,每个单词后面节一个空格
for_each(wc, words.end(),
[](const std::string &s){std::cout << s << " "; });
std::cout << std::endl;
}
int main()
{
std::vector<std::string>vecString;
std::string s = "";
//注意在win下使用ctrl+z结束输入
while (std::cin >> s)
{
vecString.push_back(s);
}
biggies(vecString, 4);
//std::cin.get();
system("pause");
return 0;
}输出结果为 改变条件
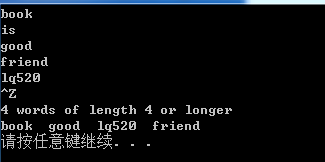
10.19用table_partition重写前一题的程序,与stable_sort类似,在划分后的序列中维持原有元素的顺序。
#include <iostream>
#include <vector>
#include <string>
#include <algorithm>
//将words按字典排序,删除重复单词
void elimDups(std::vector<std::string> &words)
{
//排序
sort(words.begin(), words.end());
auto end_unique = unique(words.begin(), words.end());
words.erase(end_unique, words.end());
}
//make_plural(wc, "word ", "s ")当输入中文本中word数大于一是在word后加s,为words为word的复数!
std::string make_plural(size_t ctr, const std::string &word, const std::string &ending)
{
return (ctr == 1) ? word : word + ending;
}
//原版
void biggies(std::vector<std::string> &words,
std::vector<std::string>::size_type sz)
{
elimDups(words);//将words按字典排序,删除重复单词
//按长度排序,长度相同的单词维持字典排序
// stable_sort(words.begin(), words.end(),
// [](const std::string &a, const std::string &b)
// {return a.size() >= b.size(); });
stable_partition(words.begin(), words.end(),
[sz](const std::string &a)
{return a.size() <= sz; });
//获取一个迭代器,指向第一个满足size()>=sz的元素
auto wc = partition(words.begin(), words.end(),
[sz](const std::string &a)
{return a.size() >= sz; });
//计算满足size>=sz的元素的数目
auto count = words.end() - wc;
std::cout << count << " " << make_plural(count, "word", "s")
<< " of length " << sz << " or longer " << std::endl;
//打印长度大于等于给定值的单词,每个单词后面节一个空格
//注意改变输出范围 才能得到和stable_sort相同结果
for_each(words.begin(), wc,
[](const std::string &s){std::cout << s << " "; });
std::cout << std::endl;
}
int main()
{
std::vector<std::string>vecString;
std::string s = "";
//注意在win下使用ctrl+z结束输入
while (std::cin >> s)
{
vecString.push_back(s);
}
biggies(vecString, 4);
//std::cin.get();
system("pause");
return 0;
}输出为
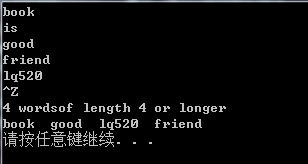
谢谢。















 3426
3426











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









