







##基本概念
凸函数和凸优化
###优化方法
常见的几种最优化方法(梯度下降法、牛顿法、拟牛顿法、共轭梯度法等)
logistic回归|梯度下降|牛顿法总结
##什么是支持向量机(SVM)?
支持向量机 (SVM) 是一个类分类器,正式的定义是一个能够将不同类样本在样本空间分隔的超平面。 换句话说,给定一些标记(label)好的训练样本 (监督式学习), SVM算法输出一个最优化的分隔超平面。
如何来界定一个超平面是不是最优的呢? 考虑如下问题:
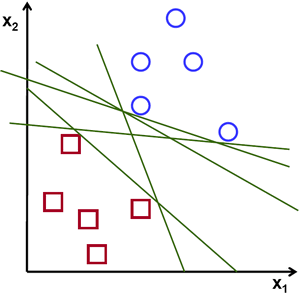
假设给定一些分属于两类的2维点,这些点可以通过直线分割, 我们要找到一条最优的分割线.
![此处输入图片的描述][1]
在上面的图中, 你可以直觉的观察到有多种可能的直线可以将样本分开。 那是不是某条直线比其他的更加合适呢? 我们可以凭直觉来定义一条评价直线好坏的标准:
距离样本太近的直线不是最优的,因为这样的直线对噪声敏感度高,泛化性较差。 因此我们的目标是找到一条直线,离所有点的距离最远。
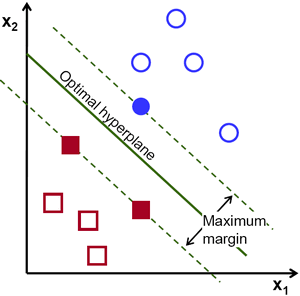
由此, SVM算法的实质是找出一个能够将某个值最大化的超平面,这个值就是超平面离所有训练样本的最小距离。这个最小距离用SVM术语来说叫做 间隔(margin) 。 概括一下,最优分割超平面 最大化 训练数据的间隔。
![此处输入图片的描述][2]
##如何计算最优超平面?
下面的公式定义了超平面的表达式:
![此处输入图片的描述][3]
![此处输入图片的描述][4] 叫做 权重向量 , ![此处输入图片的描述][5] 叫做 偏置(bias) 。
最优超平面可以有无数种表达方式,即通过任意的缩放 ![此处输入图片的描述][6] 和 ![此处输入图片的描述][7] 。 习惯上我们使用以下方式来表达最优超平面:
![此处输入图片的描述][8]
式中 x 表示离超平面最近的那些点。 这些点被称为**支持向量****。 **该超平面也称为 canonical 超平面.
通过几何学的知识,我们知道点 x 到超平面 (![此处输入图片的描述][9] , ![此处输入图片的描述][10] ) 的距离为:
![此处输入图片的描述][11]
特别的,对于 canonical 超平面, 表达式中的分子为1,因此支持向量到canonical 超平面的距离是:
![此处输入图片的描述][12]
刚才我们介绍了间隔(margin),这里表示为 M, 它的取值是最近距离的2倍:
![此处输入图片的描述][13]
最后最大化![此处输入图片的描述][14]转化为在附加限制条件下最小化函数 L(![此处输入图片的描述][15] ) 。 限制条件隐含超平面将所有训练样本 ![此处输入图片的描述][16]正确分类的条件:
![此处输入图片的描述][17]
式中![此处输入图片的描述][18]表示样本的类别标记。
这是一个拉格朗日优化问题,可以通过拉格朗日乘数法得到最优超平面的权重向量 ![此处输入图片的描述][19] 和偏置![此处输入图片的描述][20] 。
##代码实现
// TestProj.cpp : 定义控制台应用程序的入口点。
//
#include "stdafx.h"
#include <iostream>
#include <opencv2/core/core.hpp>
#include <opencv2/highgui/highgui.hpp>
#include <opencv2/imgproc/imgproc.hpp>
#include <opencv2/imgcodecs/imgcodecs.hpp>
#include <opencv2/ml/ml.hpp>
using namespace std;
using namespace cv;
using namespace cv::ml;
int main()
{
// Data for visual representation
int width = 512, height = 512;
Mat image = Mat::zeros(height, width, CV_8UC3);
// Set up training data
int labels[4] = { 1, -1, -1, -1 };
Mat labelsMat(4, 1, CV_32SC1, labels); //将labels转换成4行1列的32位单通道字符型阵列
float trainingData[4][2] = { { 501, 10 }, { 255, 10 }, { 501, 255 }, { 10, 501 } };
Mat trainingDataMat(4, 2, CV_32FC1, trainingData);
// Set up SVM's parameters
Ptr<SVM> mySvm;
mySvm = SVM::create();//建立一个空的svm文件
mySvm->setType(SVM::Types::C_SVC);
mySvm->setKernel(SVM::KernelTypes::LINEAR);
mySvm->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6));//SVM的迭代训练过程的终止条件
// Train the SVM
Ptr<TrainData> tData = TrainData::create(trainingDataMat, ROW_SAMPLE, labelsMat);
mySvm->train(tData);
Vec3b green(0, 255, 0), blue(255, 0, 0);
// Show the decision regions given by the SVM
for (int i = 0; i < image.rows; ++i)
for (int j = 0; j < image.cols; ++j)
{
Mat sampleMat = (Mat_<float>(1, 2) << i, j);//将每个i, j按照顺序输入进Mat
float response = mySvm->predict(sampleMat);
if (response == 1)
image.at<Vec3b>(j, i) = green;
else if (response == -1)
image.at<Vec3b>(j, i) = blue;
}
// Show the training data
int thickness = -1;
int lineType = 8;
circle(image, Point(501, 10), 5, Scalar(0, 0, 0), thickness, lineType);
circle(image, Point(255, 10), 5, Scalar(255, 255, 255), thickness, lineType);
circle(image, Point(501, 255), 5, Scalar(255, 255, 255), thickness, lineType);
circle(image, Point(10, 501), 5, Scalar(255, 255, 255), thickness, lineType);
// Show support vectors
thickness = 2;
lineType = 8;
Mat sv = mySvm->getUncompressedSupportVectors();
for (int i = 0; i < sv.rows; ++i)
{
const float* v = sv.ptr<float>(i);
circle(image, Point((int)v[0], (int)v[1]), 6, Scalar(0, 0, 255), thickness, lineType);
}
//imwrite("result.png", image); // save the image
imshow("SVM Simple Example", image); // show it to the user
waitKey(0);
cout << "done" << endl;
}
##代码解释
###版本差异说明
此代码主要参考中文官网文档,并作修改。因为官网代码是2.3版本,本次运行的是3.2版本,许多函数已经废弃了。
###建立训练样本
本例中的训练样本由分属于两个类别的2维点组成, 其中一类包含一个样本点,另一类包含三个点。
// Set up training data
int labels[4] = { 1, -1, -1, -1 };
Mat labelsMat(4, 1, CV_32SC1, labels); //将labels转换成4行1列的32位单通道字符型阵列
float trainingData[4][2] = { { 501, 10 }, { 255, 10 }, { 501, 255 }, { 10, 501 } };
Mat trainingDataMat(4, 2, CV_32FC1, trainingData);
###设置SVM参数
我们以可线性分割的分属两类的训练样本简单讲解了SVM的基本原理。 然而,SVM的实际应用情形可能复杂得多 (比如非线性分割数据问题,SVM核函数的选择问题等等)。 总而言之,我们需要在训练之前对SVM做一些参数设定。
// Set up SVM's parameters
Ptr<SVM> mySvm;
mySvm = SVM::create();//建立一个空的svm文件
mySvm->setType(SVM::Types::C_SVC);
mySvm->setKernel(SVM::KernelTypes::LINEAR);
mySvm->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 100, 1e-6));//SVM的迭代训练过程的终止条件
####SVM类型
- 这里我们选择了 SVM::C_SVC 类型,该类型可以用于n-类分类问题 (n >= 2)。
SVM::C_SVC 类型的重要特征是它可以处理非完美分类的问题 (及训练数据不可以完全的线性分割)。在本例中这一特征的意义并不大,因为我们的数据是可以线性分割的,我们这里选择它是因为它是最常被使用的SVM类型。
SVM::NU_SVC : 类支持向量分类机。n类似然不完全分类的分类器。参数为取代C(其值在区间【0,1】中,nu越大,决策边界越平滑)。
SVM::ONE_CLASS : 单分类器,所有的训练数据提取自同一个类里,然后SVM建立了一个分界线以分割该类在特征空间中所占区域和其它类在特征空间中所占区域。
SVM::EPS_SVR : 类支持向量回归机。训练集中的特征向量和拟合出来的超平面的距离需要小于p。异常值惩罚因子C被采用。
SVM::NU_SVR : 类支持向量回归机。 代替了 p。
####SVM 核函数(4种)
SVM 核类型. 我们没有讨论核函数,因为对于本例的样本,核函数的讨论没有必要。然而,有必要简单说一下核函数背后的主要思想, 核函数的目的是为了将训练样本映射到更有利于可线性分割的样本集。 映射的结果是增加了样本向量的维度,这一过程通过核函数完成。 此处我们选择的核函数类型是 CvSVM::LINEAR 表示不需要进行映射。
SVM::LINEAR : 线性内核,没有任何向映射至高维空间,线性区分(或回归)在原始特征空间中被完成,这是最快的选择。

SVM::POLY : 多项式内核:

SVM::RBF : 基于径向的函数,对于大多数情况都是一个较好的选择:

SVM::SIGMOID : Sigmoid函数内核:

####内核参数
- degree:内核函数(POLY)的参数degree。
- gamma:内核函数(POLY/ RBF/ SIGMOID)的参数。
- coef0:内核函数(POLY/ SIGMOID)的参数coef0。
- Cvalue:SVM类型(C_SVC/ EPS_SVR/ NU_SVR)的参数C。
- nu:SVM类型(NU_SVC/ ONE_CLASS/ NU_SVR)的参数 。
- p:SVM类型(EPS_SVR)的参数。
- class_weights:C_SVC中的可选权重,赋给指定的类,乘以C以后变成 。所以这些权重影响不同类别的错误分类惩罚项。权重越大,某一类别的误分类数据的惩罚项就越大。
- term_crit:SVM的迭代训练过程的中止条件,解决部分受约束二次最优问题。您可以指定的公差和/或最大迭代次数。
当我们选择LINEAR为内核的时候,上述内核参数都是不需要的,另外三个内核的时候,需要对其分别进行设置,设置后可以进行直接训练:
svm_ = cv::ml::SVM::create();
svm_->setType(cv::ml::SVM::C_SVC);
svm_->setKernel(cv::ml::SVM::RBF);
svm_->setDegree(0.1);
// 1.4 bug fix: old 1.4 ver gamma is 1 //1.4版本bug修复
svm_->setGamma(1);
svm_->setCoef0(0.1);
svm_->setC(1);
svm_->setNu(0.1);
svm_->setP(0.1);
svm_->setTermCriteria(cvTermCriteria(CV_TERMCRIT_ITER, 20000, 0.0001));
svm_->train(train_data);
算法终止条件.
SVM训练的过程就是一个通过 迭代 方式解决约束条件下的二次优化问题,这里我们指定一个最大迭代次数和容许误差,以允许算法在适当的条件下停止计算。 该参数定义在 cvTermCriteria 结构中。
#define CV_TERMCRIT_ITER 1
#define CV_TERMCRIT_NUMBER CV_TERMCRIT_ITER
#define CV_TERMCRIT_EPS 2
typedef struct CvTermCriteria {
int type; /* CV_TERMCRIT_ITER 和CV_TERMCRIT_EPS二值之一,或者二者的组合 */
int max_iter; /* 最大迭代次数 */
double epsilon; /* 结果的精确性 */
}
CvTermCriteria;
/* 构造函数 */
inline CvTermCriteria cvTermCriteria( int type, int max_iter, double epsilon );
//训练完成后保存txt或者xml文件
svm->save("svm_image.xml");
// 载入模型的语句:
Ptr<SVM> svmp = SVM::load<SVM>("svm_image.xml");
/*载入之后就可以进行预测了*/
//返回的是预测数据距离决策面(超平面)的几何距离
float response = svmp->predict(sampleMat, noArray(), StatModel::Flags::RAW_OUTPUT);
//返回的是标签分类
float response = svmp->predict(sampleMat, noArray(), 0);
float response = svmp->predict(sampleMat);
###SVM区域分割
函数 CvSVM::predict 通过重建训练完毕的支持向量机来将输入的样本分类。 本例中我们通过该函数给向量空间着色, 及将图像中的每个像素当作卡迪尔平面上的一点,每一点的着色取决于SVM对该点的分类类别:绿色表示标记为1的点,蓝色表示标记为-1的点。
###支持向量
这里用了几个函数来获取支持向量的信息。 函数 CvSVM::get_support_vector_count 输出支持向量的数量,函数 CvSVM::get_support_vector 根据输入支持向量的索引来获取指定位置的支持向量。 通过这一方法我们找到训练样本的支持向量并突出显示它们。
// Show support vectors
thickness = 2;
lineType = 8;
Mat sv = mySvm->getUncompressedSupportVectors();
for (int i = 0; i < sv.rows; ++i)
{
const float* v = sv.ptr<float>(i);
circle(image, Point((int)v[0], (int)v[1]), 6, Scalar(0, 0, 255), thickness, lineType);
}
##运行结果
- 程序创建了一张图像,在其中显示了训练样本,其中一个类显示为白色圆圈,另一个类显示为黑色圆圈。
- 训练得到SVM,并将图像的每一个像素分类。 分类的结果将图像分为蓝绿两部分,中间线就是最优分割超平面。
- 最后支持向量通过红色边框加重显示。

##参考
1、支持向量机(五)SMO算法
2、支持向量机(SVM)介绍
2、opencv3.1线性可分svm例子及函数分析
[1]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/separating-lines.png
[2]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/optimal-hyperplane.png
[3]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/0f0cfaabeda8398aa556af98b2c8a6180317ccfd.png
[4]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/fdb63b9e51abe6bbb16acfb5d7b773ddbb5bf4a8.png
[5]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/c9495563b51f641afe9d2cf2145b039aa94d6b04.png
[6]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/fdb63b9e51abe6bbb16acfb5d7b773ddbb5bf4a8.png
[7]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/c9495563b51f641afe9d2cf2145b039aa94d6b04.png
[8]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/078d5267c94cc552ac7e204ee0329628b7ad4af9.png
[9]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/fdb63b9e51abe6bbb16acfb5d7b773ddbb5bf4a8.png
[10]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/c9495563b51f641afe9d2cf2145b039aa94d6b04.png
[11]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/56659fa815649f884aed47f5cf79fbd0f7bb82e5.png
[12]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/db288cbae16c3dbf5c88195808cf65745b72f2ca.png
[13]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/12e0bd6b43a65d7def91193ca44bd72e2c93a169.png
[14]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/5d1e4485dc90c450e8c76826516c1b2ccb8fce16.png
[15]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/fdb63b9e51abe6bbb16acfb5d7b773ddbb5bf4a8.png
[16]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/837682bc6103a4c6740c8273434e1a2c771a2514.png
[17]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/f62195b02da495294dbd35da208211e447ab7084.png
[18]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/8061ee572c06de48dfc2c0d05e4c23da64bcd74a.png
[19]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/fdb63b9e51abe6bbb16acfb5d7b773ddbb5bf4a8.png
[20]: http://www.opencv.org.cn/opencvdoc/2.3.2/html/_images/math/c9495563b51f641afe9d2cf2145b039aa94d6b04.png















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}
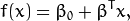{kind=link}
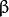{kind=link}
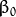{kind=link}
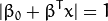{kind=link}
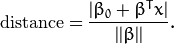{kind=link}
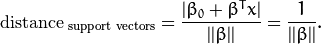{kind=link}
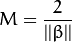{kind=link}
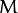{kind=link}
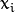{kind=link}
{kind=link}
{kind=link}