






生成*.yy.c
在学习到编译原理的词法分析器阶段,为了学习使用lex做分析,在网上找了一些资料学习。
lex代码来源:https://blog.csdn.net/wang_yr/article/details/106004464,
AUXILIARY DEFINITION
letter->A|B|…|Z
digit->0|1|…|9
RECOGNITION RULES
1 DIM {RETURN(1,-)}
2 IF {RETURN(2,-)}
3 DO {RETURN(3,-)}
4 STOP {RETURN(4,-)}
5 END {RETURN(5,-)}
6 letter(letter|digit)* {RETURN(6,TOKEN)}
7 digit(digit)* {RETURN(7,DTB)}
8 = {RETURN(8,-)}
9 + {RETURN(9,-)}
10 * {RETURN(10,-)}
11 ** {RETURN(11,-)}
12 , {RETURN(12,-)}
13 ( {RETURN(13,-)}
14 ) {RETURN(14,-)}
使用win_flex.exe编译,win_flex.exe --wincompat --outfile=yy.c输出位置 .l文件位置,如下
win_flex.exe --wincompat --outfile=D:\lxc\nbu\software\win_flex_bison-latest\my_code_test/a.yy.c D:\lxc\nbu\software\win_flex_bison-latest\my_code_test\a.l

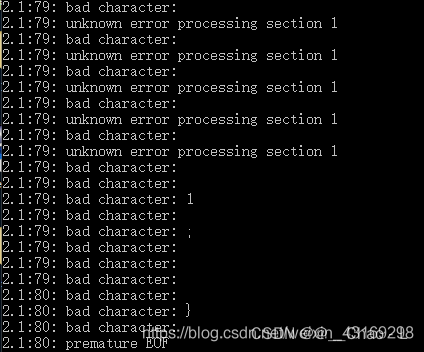
但是在使用lex编译时出现了下面的的一些错误:如bad character和error processing section 1、aa.l:19: premature EOF等等。
经过一顿百度之后,在百度词条里面看到了下面这么一段,所以我在想是不是把AUXILIARY DEFINITION、RECOGNITION RULES换成双百分号%%就好了呢,

新代码如下
%%
letter->A|B|...|Z
digit ->0|1|...|9
%%
1 DIM { RETURN (1,-) }
2 IF { RETURN (2,-) }
3 DO { RETURN (3,-) }
4 STOP { RETURN (4,-) }
5 END { RETURN (5,-) }
6 letter(letter|digit)* { RETURN (6,TOKEN) }
7 digit(digit)* { RETURN (7,DTB) }
8 = { RETURN (8,-) }
9 + { RETURN (9,-) }
10 * { RETURN (10,-) }
11 ** { RETURN (11,-) }
12 , { RETURN (12,-) }
13 ( { RETURN (13,-) }
14 ) { RETURN (14,-) }
再次编译:D:\lxc\nbu\software\win_flex_bison-latest>win_flex.exe --wincompat --outfile=D:\lxc\nbu\software\win_flex_bison-latest\my_code_test/a.yy.c D:\lxc\nbu\software\win_flex_bison-latest\my_code_test\a.l

*.yy.c文件生成之后就是使用MinGW编译c文件成exe了。安装MinGW:https://blog.csdn.net/jiqiren_dasheng/article/details/103775488。
用*.yy.c编译成*.exe
注意,下面的pl.l文件内容和上面的不一样了,
下面来测试使用lex生成PL语言的词法分析器,aa.l文件代码来源:https://blog.csdn.net/JYLCG/article/details/106126107,
/* PL词法分析器 */
/* 功能:能够识别出PL支持的所有单词符号并给出种别值 */
/* 说明:在下面的begin和end之间添加代码,已经实现了标识符和整常量的识别,你需要完成剩下的部分,加油吧! */
/* 提示:因为是顺序匹配,即从上至下依次匹配规则,所以需要合理安排顺序~ */
%{
#include <stdio.h>
%}
/* begin */
OFSYM of
ARRAYSYM array
PROGRAMSYM program
MODSYM mod
ANDSYM and
NOTSYM not
ORSYM or
BEGINSYM begin
ENDSYM end
IFSYM if
THENSYM then
ELSESYM else
WHILESYM while
DOSYM do
CALLSYM call
CONSTSYM const
VARSYM var
TYPESYM type
PROCSYM procedure
CHARCON \'[^\']*\'
INTCON [\-]?[1-9][0-9]*|0
IDENT [A-Za-z][A-Za-z0-9]*
PLUS \+
MINUS \-
TIMES \*
DIVSYM \/
EQL =
NEQ <>
LSS <
LEQ <=
GTR >
GEQ >=
LBRACK \[
RBRACK \]
LPAREN \(
RPAREN \)
COMMA ,
SEMICOLON ;
COLON :
PERIOD \.
BECOME :=
ERROR [^ \t\n]
/* end */
%%
{CHARCON} {printf("%s: CHARCON\n", yytext);}
{PLUS} {printf("%s: PLUS\n", yytext);}
{MINUS} {printf("%s: MINUS\n", yytext);}
{TIMES} {printf("%s: TIMES\n", yytext);}
{DIVSYM} {printf("%s: DIVSYM\n", yytext);}
{EQL} {printf("%s: EQL\n", yytext);}
{NEQ} {printf("%s: NEQ\n", yytext);}
{LSS} {printf("%s: LSS\n", yytext);}
{LEQ} {printf("%s: LEQ\n", yytext);}
{GTR} {printf("%s: GTR\n", yytext);}
{GEQ} {printf("%s: GEQ\n", yytext);}
{LBRACK} {printf("%s: LBRACK\n", yytext);}
{RBRACK} {printf("%s: RBRACK\n", yytext);}
{LPAREN} {printf("%s: LPAREN\n", yytext);}
{RPAREN} {printf("%s: RPAREN\n", yytext);}
{COMMA} {printf("%s: COMMA\n", yytext);}
{SEMICOLON} {printf("%s: SEMICOLON\n", yytext);}
{COLON} {printf("%s: COLON\n", yytext);}
{PERIOD} {printf("%s: PERIOD\n", yytext);}
{BECOME} {printf("%s: BECOME\n", yytext);}
{OFSYM} {printf("%s: OFSYM\n", yytext);}
{ARRAYSYM} {printf("%s: ARRAYSYM\n", yytext);}
{PROGRAMSYM} {printf("%s: PROGRAMSYM\n", yytext);}
{MODSYM} {printf("%s: MODSYM\n", yytext);}
{ANDSYM} {printf("%s: ANDSYM\n", yytext);}
{NOTSYM} {printf("%s: NOTSYM\n", yytext);}
{ORSYM} {printf("%s: ORSYM\n", yytext);}
{BEGINSYM} {printf("%s: BEGINSYM\n", yytext);}
{ENDSYM} {printf("%s: ENDSYM\n", yytext);}
{IFSYM} {printf("%s: IFSYM\n", yytext);}
{THENSYM} {printf("%s: THENSYM\n", yytext);}
{ELSESYM} {printf("%s: ELSESYM\n", yytext);}
{WHILESYM} {printf("%s: WHILESYM\n", yytext);}
{DOSYM} {printf("%s: DOSYM\n", yytext);}
{CALLSYM} {printf("%s: CALLSYM\n", yytext);}
{CONSTSYM} {printf("%s: CONSTSYM\n", yytext);}
{VARSYM} {printf("%s: VARSYM\n", yytext);}
{TYPESYM} {printf("%s: TYPESYM\n", yytext);}
{PROCSYM} {printf("%s: PROCSYM\n", yytext);}
{INTCON} {printf("%s: INTCON\n", yytext);}
{IDENT} {printf("%s: IDENT\n", yytext);}
{ERROR} {printf("%s: ERROR\n", yytext);}
\n {}
. {}
%%
int yywrap() { return 1; }
int main(int argc, char **argv)
{
if (argc > 1) {
if (!(yyin = fopen(argv[1], "r"))) {
perror(argv[1]);
return 1;
}
}
while (yylex());
return 0;
}
先使用win_flex.exe编译pl.l,win_flex.exe --wincompat --outfile=D:\lxc\nbu\software\win_flex_bison-latest\my_code_test/pl.yy.c D:\lxc\nbu\software\win_flex_bison-latest\my_code_test\pl.l

使用gcc编译pl.yy.c时出现如下,gcc pl.yy.c -o pl


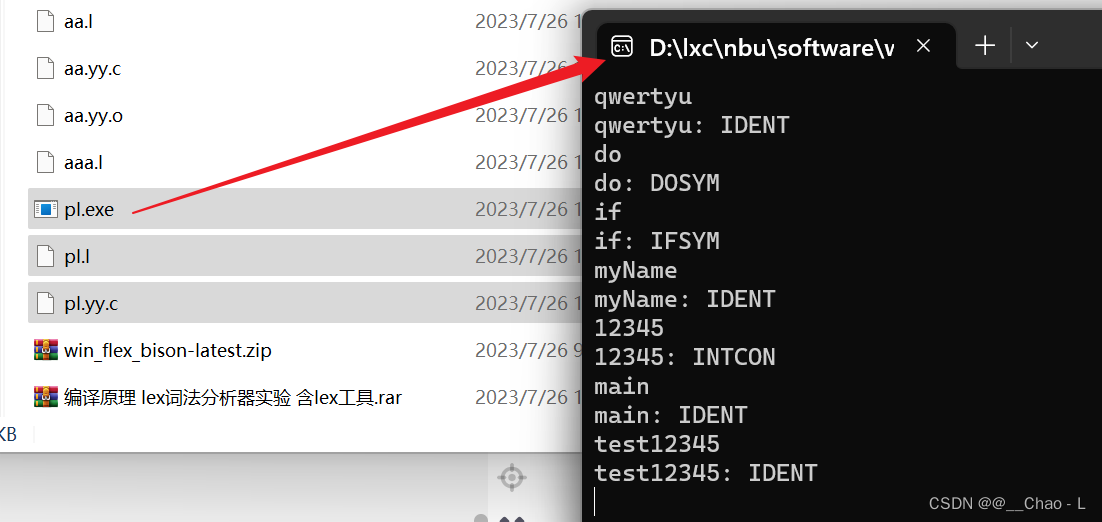
双击运行,pl.exe,简单的测试一下词法分析器的能力
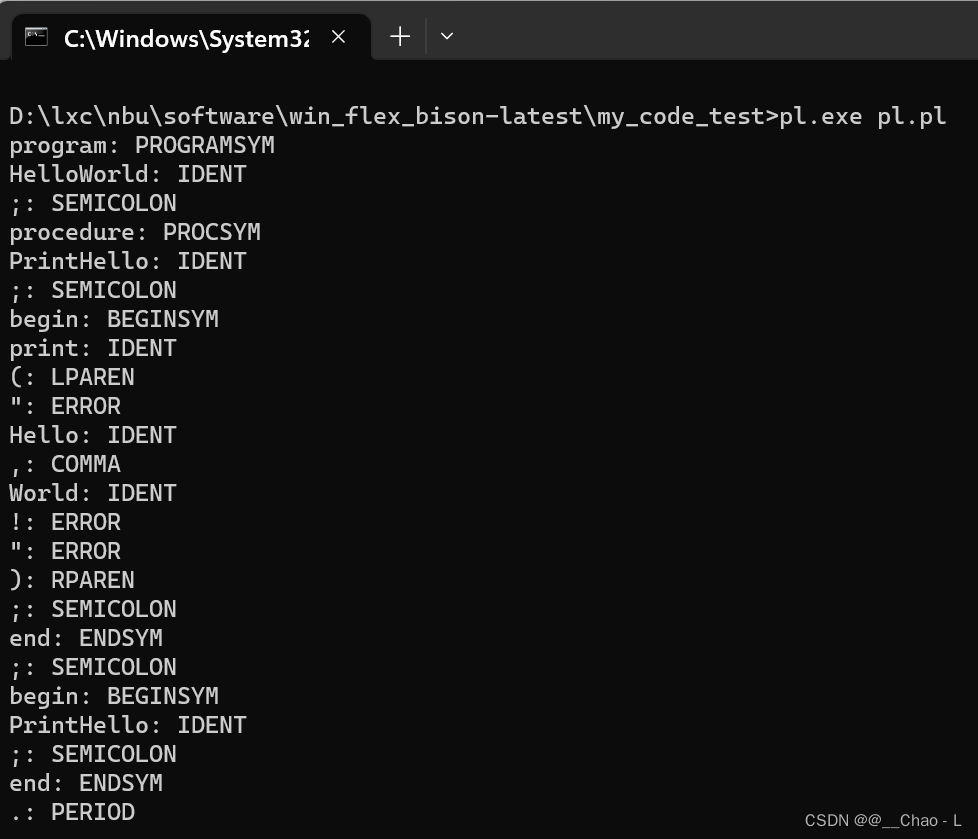
下面测试一个PL语言的Hello world文件的词法分析,PL语言的HelloWorld如下
program HelloWorld;
procedure PrintHello;
begin
print("Hello, World!");
end;
begin
PrintHello;
end.
命令行启动pl.exe,并传入文件D:\lxc\nbu\software\win_flex_bison-latest\my_code_test>pl.exe pl.pl
整个实验过程完整资源下载:https://download.csdn.net/download/xianchao0127/88103102
本文参考:lex原理:https://www.bwangel.me/2019/12/15/flex/、安装lex:https://zhuanlan.zhihu.com/p/551669070、使用:https://blog.csdn.net/wang_yr/article/details/106004464、b站学习课程:https://www.bilibili.com/video/BV11t411V74n















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









