






背景
💡 想法源于在一次 Code Review 时,向 Claude 询问哪种写法代码更优雅得来。当时就想能不能让 AI 帮我们辅助做 Code Review?
痛点
-
信息安全合规问题:公司内代码直接调 ChatGPT / Claude 会有安全/合规问题,为了使用 ChatGPT / Claude 需要对代码脱敏,只提供抽象逻辑,这往往更花时间。
-
三星引入 ChatGPT 不到 20 天,被曝发生 3 次芯片机密泄露[1]
-
低质量代码耗费时间:达人业务每天至少 10~20 个 MR 需要 CR,虽然提交时 MR 经过 单测 + Lint 过滤了一些低级错误,但还有些问题(代码合理性、经验、MR 相关业务逻辑等)需要花费大量时间,最后可以先经过自动化 CR,再进行人工 CR,可大大提升 CR 效率!
-
团队 Code Review 规范缺少执行:大部分团队的 Code Review 停留在文档纸面上,成员之间口口相传,并没有一个工具根据规范来严格执行。
介绍
一句话介绍就是:基于开源大模型 + 知识库的 Code Review 实践,类似一个代码评审助手(CR Copilot)。
特性
符合公司安全规范,所有代码数据不出内网,所有推理过程均在内网完成。
-
🌈 开箱即用:基于 Gitlab CI,仅 10 几行配置完成接入,即可对 MR 进行 CR。
-
🔒 数据安全:基于开源大模型做私有化部署,隔离外网访问,确保代码 CR 过程仅在内网环境下完成。
-
♾ 无调用次数限制:部署在内部平台,只有 GPU 租用成本。
-
📚 自定义知识库:CR 助手基于提供的飞书文档进行学习,将匹配部分作为上下文,结合代码变更进行 CR,这将大大提升 CR 的准确度,也更符合团队自身的 CR 规范。
-
🎯 评论到变更行:CR 助手将结果评论到变更代码行上,通过 Gitlab CI 通知,更及时获取 CR 助手给出的评论。
名词解释
| 名词 | 释义 |
|---|---|
| CR / Code Review | 越来越多的企业都要求研发团队在代码的开发过程中要进行 CodeReview(简称 CR),在保障代码质量的同时,促进团队成员之间的交流,提高代码水平。 |
| llm / 大规模语言模型 | 大规模语言模型(Large Language Models,LLMs)是自然语言处理中使用大量文本数据训练的神经网络模型,可以生成高质量的文本并理解语言。如 GPT、BERT 等。 |
| AIGC | 利用 NLP、NLG、计算机视觉、语音技术等生成文字、图像、视频等内容。全称是人工智能生成/创作内容(Artificial Intelligence Generated Content);是继 UGC,PGC 后,利用人工智能技术,自动生成内容的生产方式;AIGC 底层技术的发展,驱动围绕不同内容类型(模态)和垂直领域的应用加速涌现。 |
| LLaMA | Meta(Facebook)的大型多模态语言模型。 |
| ChatGLM | ChatGLM 是一个开源的、支持中英双语的对话语言模型,底座是 GLM 语言模型。 |
| Baichuan | Baichuan 2 是百川智能推出的新一代开源大语言模型,采用 2.6 万亿 Tokens 的高质量语料训练。 |
| Prompt | 一段文本或语句,用于指导机器学习模型生成特定类型、主题或格式的输出。在自然语言处理领域中,Prompt 通常由一个问题或任务描述组成,例如“给我写一篇有关人工智能的文章”、“翻译这个英文句子到法语”等等。在图像识别领域中,Prompt 则可以是一个图片描述、标签或分类信息。 |
| langchain | LangChain 是一个开源 Python 库,由 Harrison Chase 开发,旨在支持使用大型语言模型(LLM)和外部资源(如数据源或语言处理系统)开发应用程序。它提供了标准的接口,与其他工具集成,并为常见应用程序提供端到端链 。 |
| embedding | 将任意文本映射到固定维度的向量空间中,相似语义的文本,其向量在空间中的位置会比较接近。在 LLM 应用中常用于相似性的文本搜索。 |
| 向量数据库 (Vector stores) | 存储向量表示的数据库,用于相似性搜索。如 Milvus、Pinecone 等。 |
| Similarity Search | 在向量数据库中搜索离查询向量最近的向量,用于检索相似项。 |
| 知识库 | 存储结构化知识的数据库,LLM 可以利用这些知识增强自己的理解能力。 |
| In-context Learning | In-Context Learning 是机器学习领域的一个概念,指不调整模型自身参数,而是在 Prompt 上下文中包含特定问题相关的信息,就可以赋予模型解决新问题能力的一种方式。 |
| Finetune / 微调 | 在预训练模型基础上使用特定数据集进行微调,提升模型在某任务上的性能。 |
实现思路
流程图

系统架构
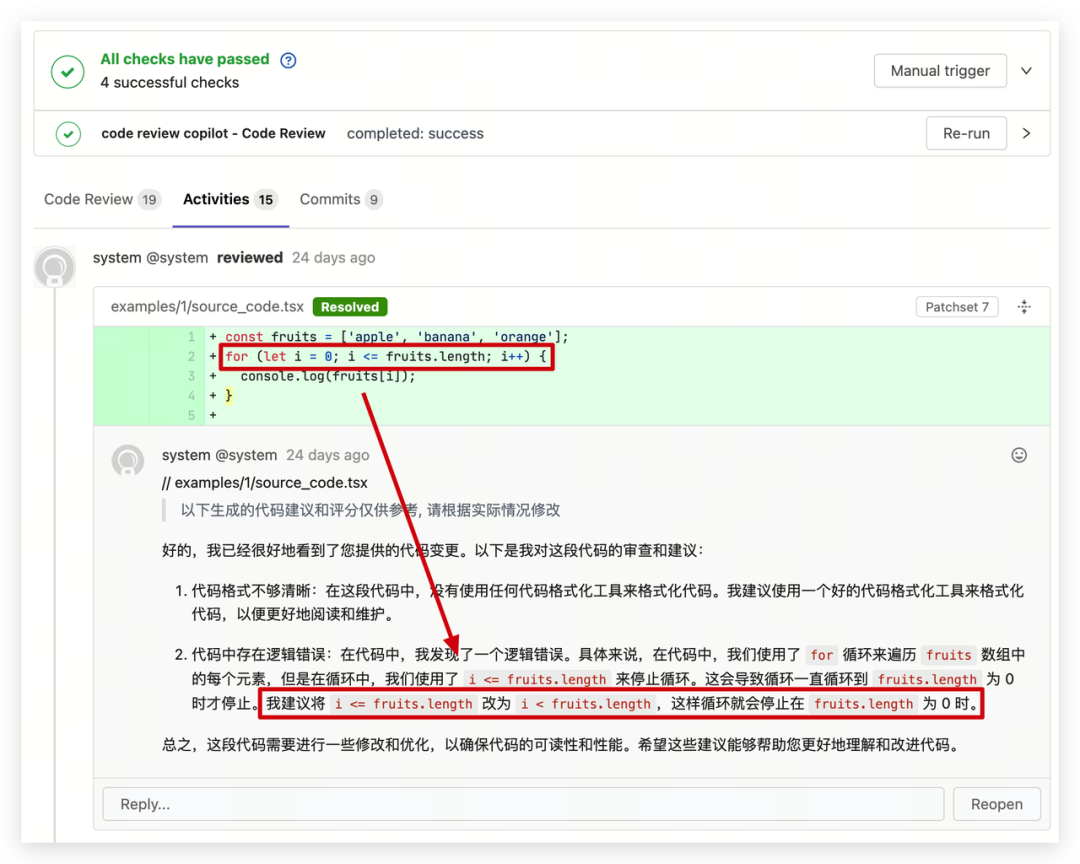
完成一次 CR 流程,需要用到如下技术模块:
LLMs / 开源大模型选型
CR Copilot 功能的核心在于大语言模型基座,基于不同大模型基座生成的 CR 质量也不尽相同。对于 CR 这个场景,我们需要选型的模型满足以下几个条件:
-
理解代码
-
对中文支持好
-
较强的上下文学习能力
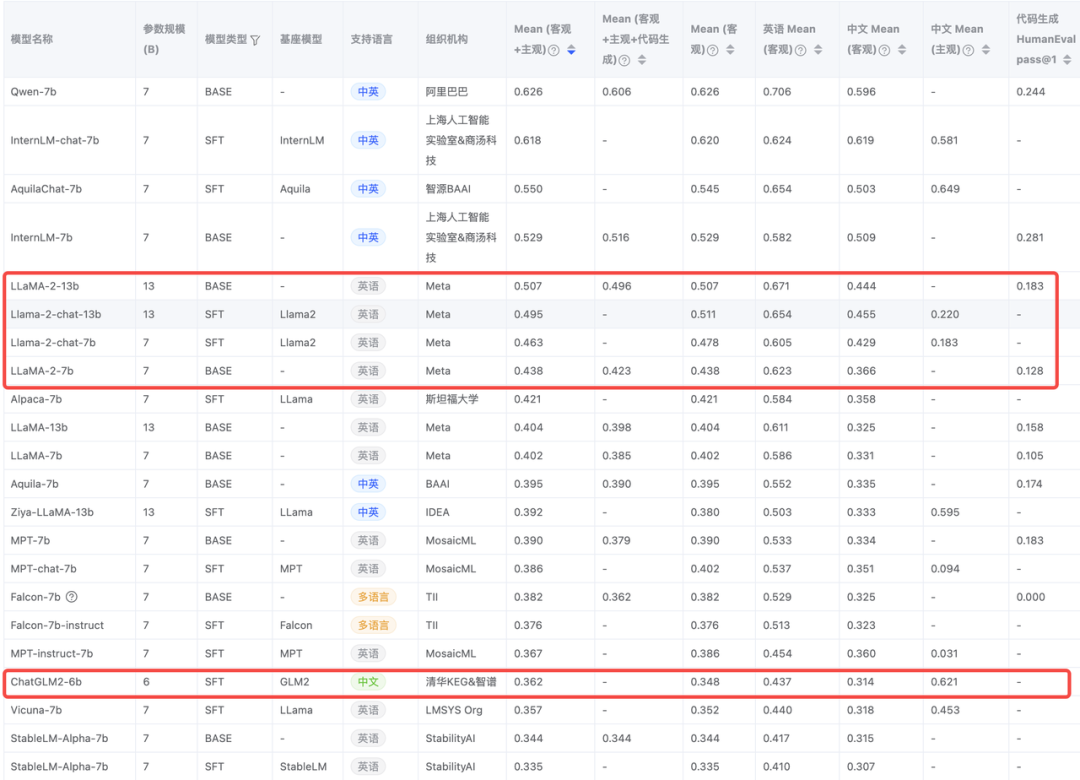 FlagEval 8 月大模型评测榜单(https://flageval.baai.ac.cn/#/trending)
FlagEval 8 月大模型评测榜单(https://flageval.baai.ac.cn/#/trending)
模型后面的
-{n}b指n*10亿参数量,比如 13b 就是 130 亿参数,个人试用下来参数量的多少并不能决定效果怎样,根据实际情况来判断。
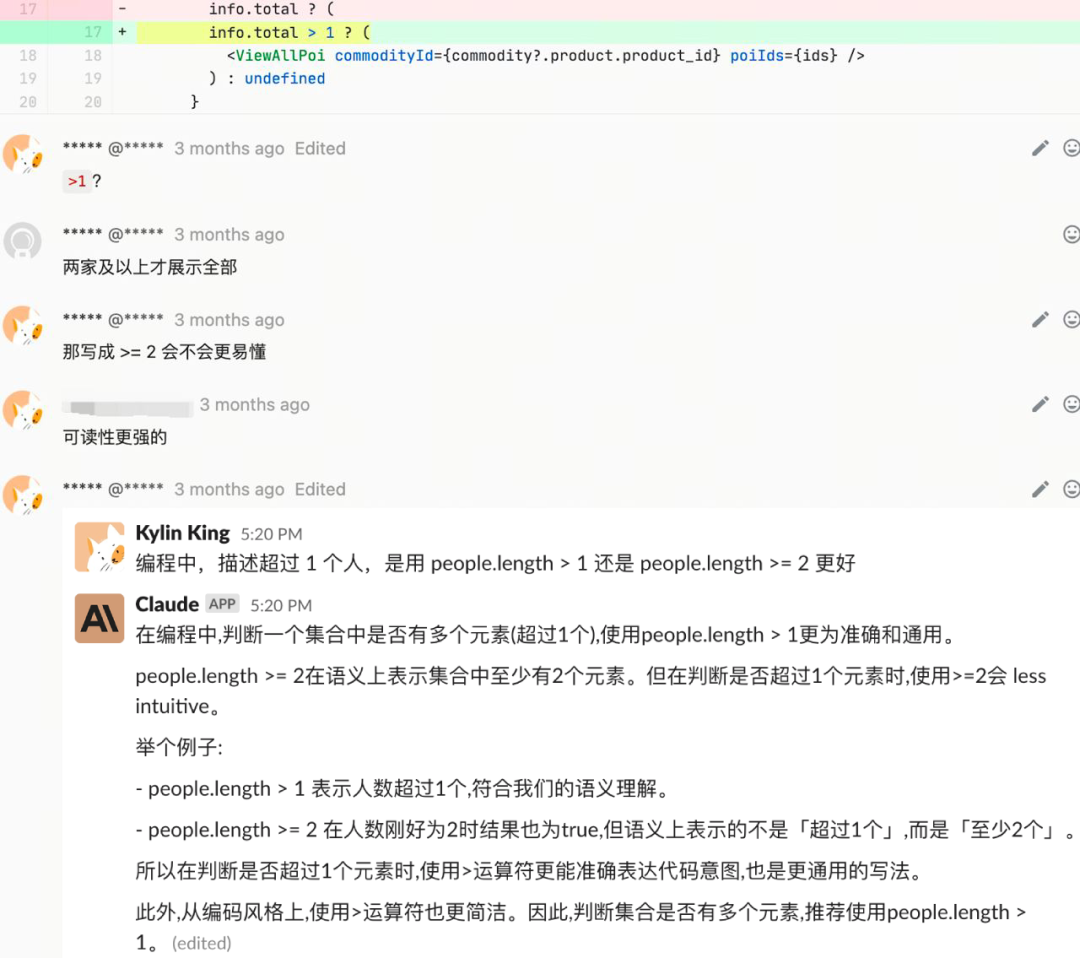
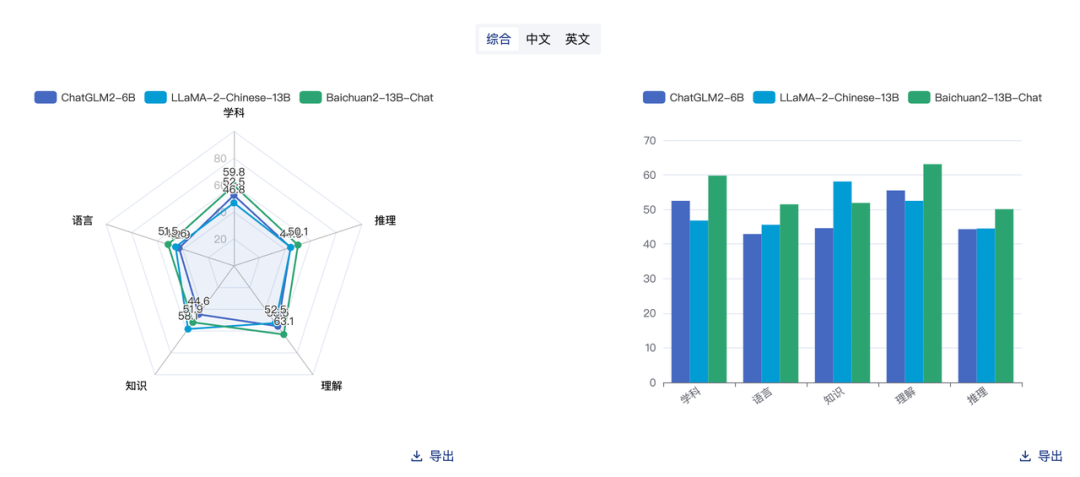
起初在众多大模型中选择『Llama2-Chinese-13b-Chat[2]』和『chatglm2-6b[3]』、『Baichuan2-13B-Chat[4]』,通过一段时间模型赛马 🐎,主观上感觉 Llama2 会更适用于 CR 场景,而 ChatGLM2 更像是文科生,对代码评审没有太多建设性建议,但在中文 AIGC 上会比较有优势!

两个模型执行过程中的记录
因大模型合规问题,CR Copilot 会默认使用 ChatGLM2-6B,如有使用 Llama2 模型需求需要向 Meta 申请[5],通过后可使用。
 Llama 2 要求企业的月活用户数不超过 7 亿
Llama 2 要求企业的月活用户数不超过 7 亿
目前支持的模型可选,仅供参考的评分[6]如下:
-
chatglm2-6b[7](默认)
-
Llama2-Chinese-13b-Chat[8](推荐)
-
Baichuan2-13B-Chat[9]
知识库设计
为什么需要知识库?
大模型基座只包含互联网上的公开数据,对公司内部的框架知识和使用文档并不了解。
举个例子 🌰:公司内有个框架叫 Lynx,让大模型从内部文档中知道『什么是 Lynx?』、『怎么写 Lynx? 』
 一图胜千言
一图胜千言
这里的『强化模式』会使用向量数据库,并将匹配的知识库片段和问题『什么是 Lynx?』生成 Prompt,发送到 LLM 执行。
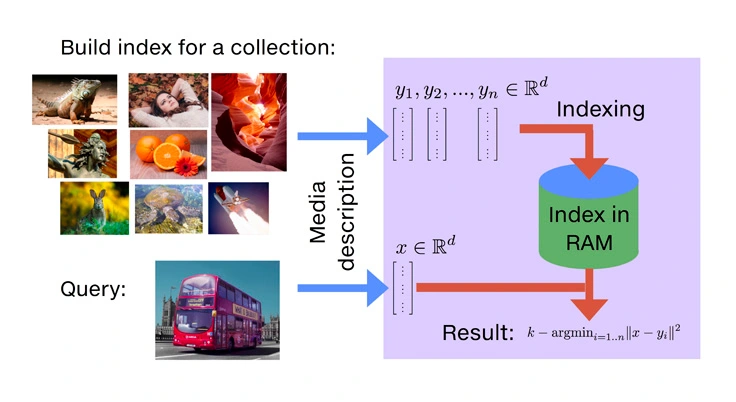
怎样找到相关度高的知识?
有了知识库后,怎样将我们『搜索的问题/代码』在『知识库』中找到『相关度最高的内容』?
答案是通过三个过程:
-
Text Embeddings(文本向量化)
-
Vector Stores(向量存储)
-
Similarity Search(相似性搜索)
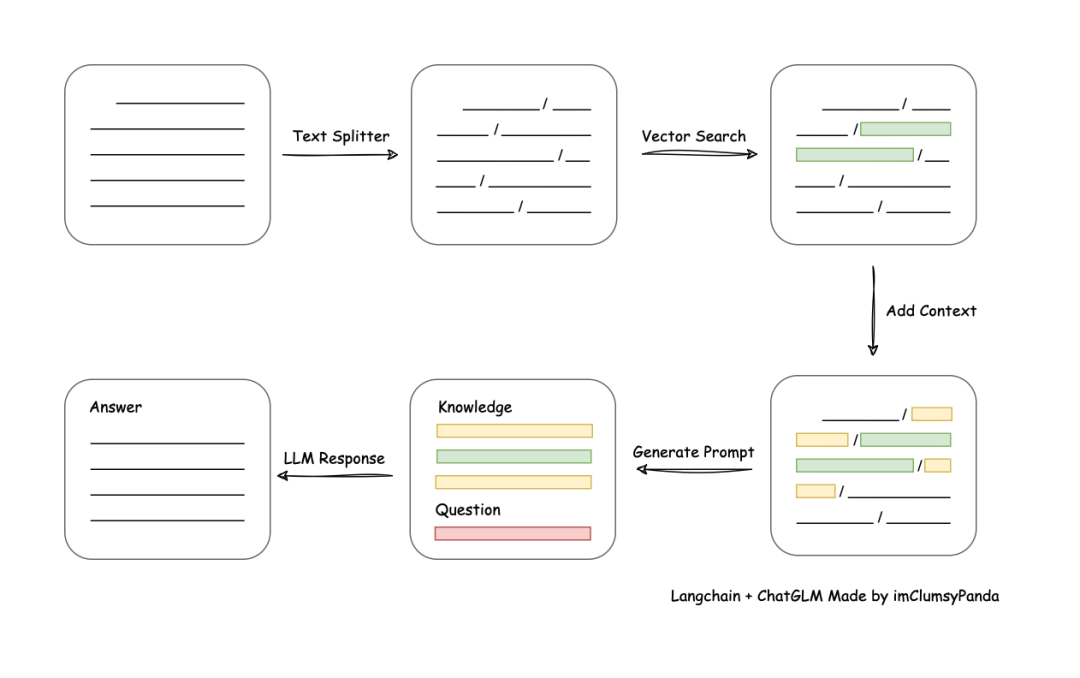 文本相似度匹配流程图,图源 Langchain-Chatchat
文本相似度匹配流程图,图源 Langchain-Chatchat
Text Embeddings(文本向量化)
不同于传统数据库的模糊搜索/匹配关键字,我们需要进行语义/特征匹配。
例如:你搜索『猫』,只能得到带 『猫』 关键字匹配的结果,没办法得到 『布偶』、『蓝白』 等结果,传统数据库认为『布偶』是『布偶』、『猫』是『猫』。要实现关联语义搜索,是通过人工打特征标签,这个过程也被称为特征工程(Feature Engineering)。
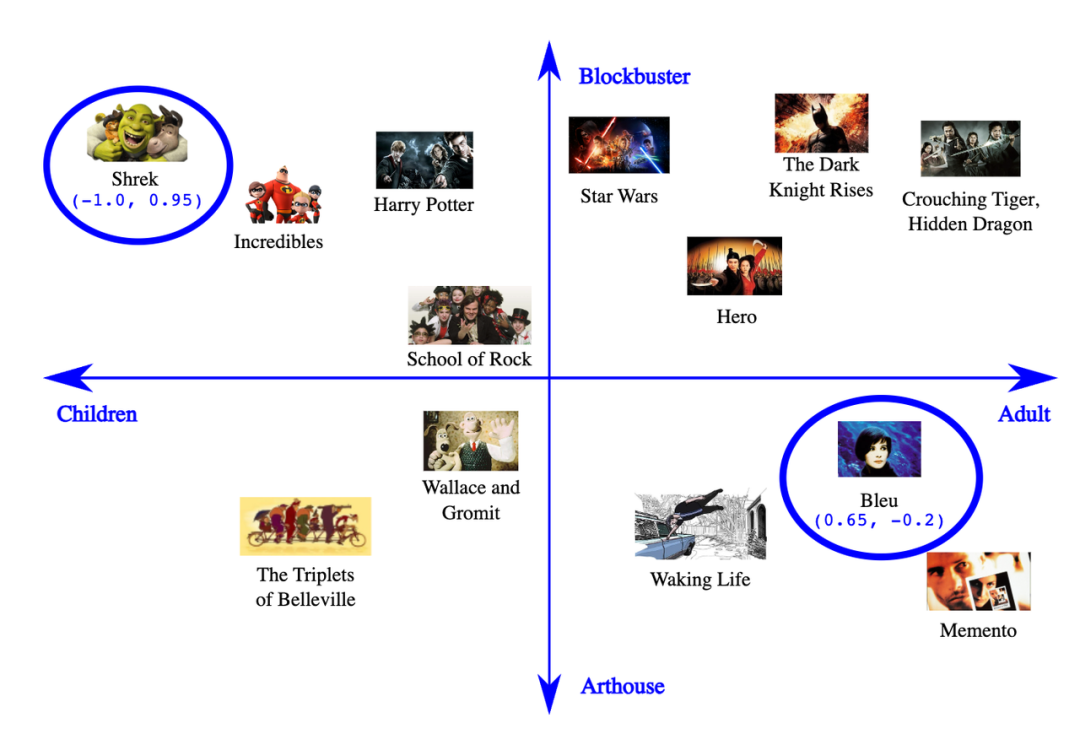
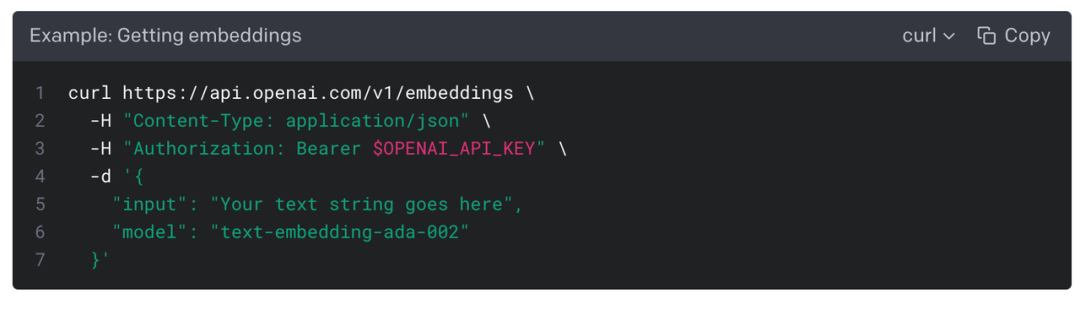
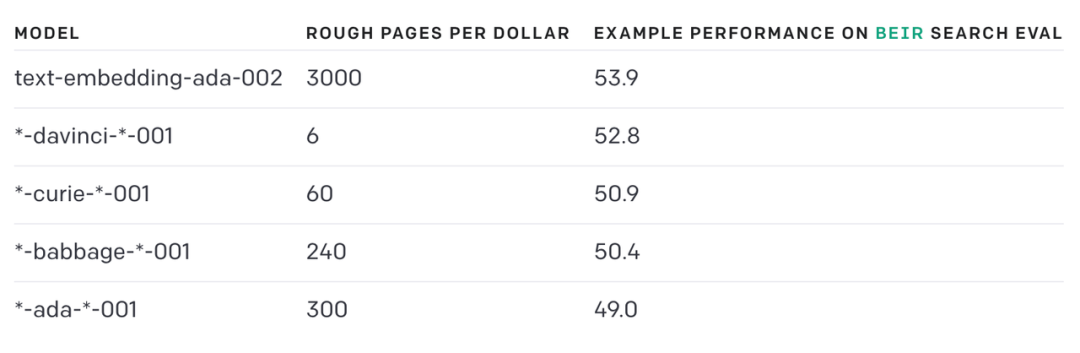
如何才能将文本自动化的方式来提取这些特征?这就要通过 Vector Embedding 向量化实现,目前社区通过 OpenAI 提供的 text-embedding-ada-002 模型生成,这会引起两个问题:
-
数据安全问题:需要调用 OpenAI 的 API 才能做向量化
-
收费:大概 3000 页/美元
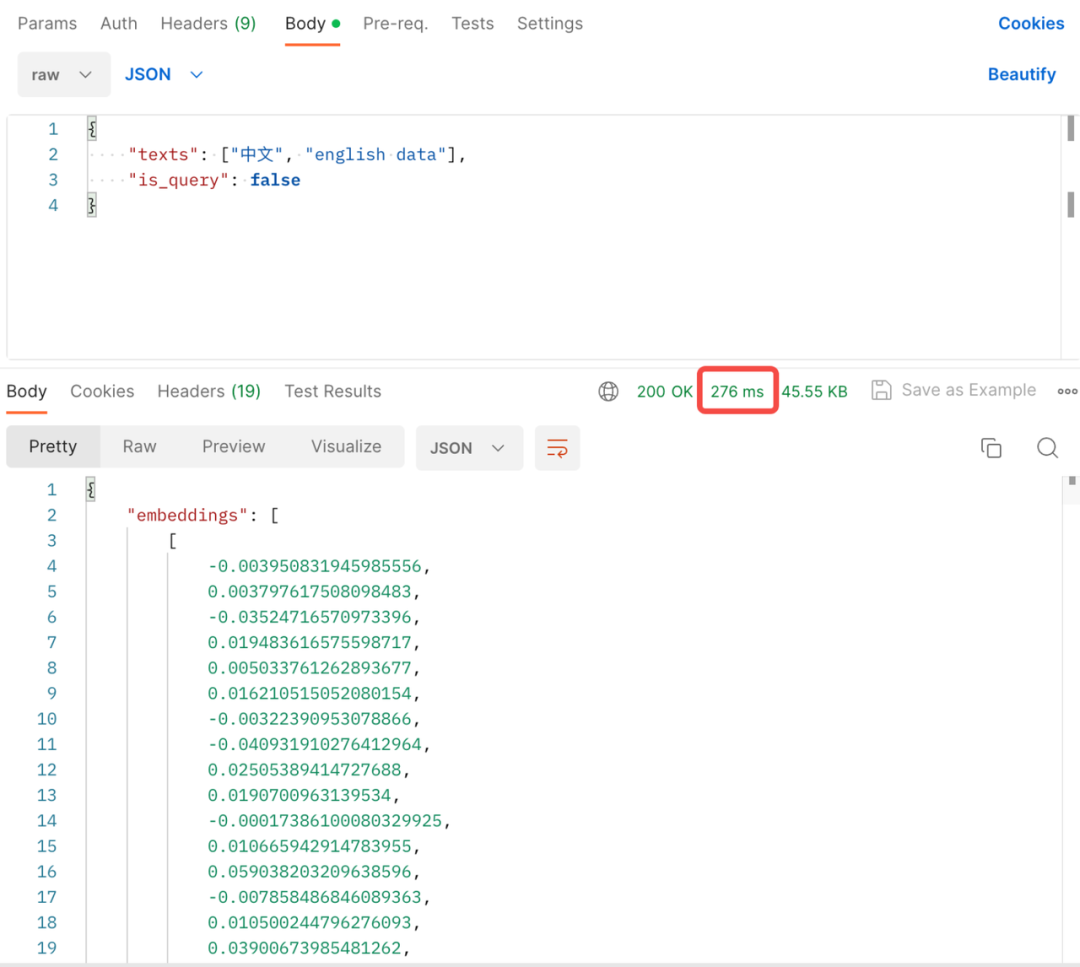
我们使用了国产文本相似度计算模型 bge-large-zh[10],并私有化部署公司内网,一次 embedding 向量化耗时基本在毫秒级。
Vector Stores(向量存储)
提前将官方文档进行 Vector Embeddings,然后存储在向量数据库里,我们这里选择的向量数据库是 Qdrant,主要考虑到是用 Rust 写的,存储和查询也许会快一些!这里引用一个向量数据库选型的几个维度选择:
| 向量数据库 | URL | GitHub Star | Language | Cloud |
|---|---|---|---|---|
| chroma | https://github.com/chroma-core/chroma | 8.5K | Python | ❌ |
| milvus | https://github.com/milvus-io/milvus | 22.8K | Go/Python/C++ | ✅ |
| pinecone | https://www.pinecone.io/ | ❌ | ❌ | ✅ |
| qdrant | https://github.com/qdrant/qdrant | 12.7K | Rust | ✅ |
| typesense | https://github.com/typesense/typesense | 14.4K | C++ | ❌ |
| weaviate | https://github.com/weaviate/weaviate | 7.4K | Go | ✅ |
数据截止到 2023 年 9 月 10 号
Similarity Search(相似性搜索)
原理是通过比较向量之间的距离来判断它们的相似度
那么有了『query 问题的向量』和『数据库里录入的知识库向量』后,这可以直接使用向量数据库提供的 Similarity Search 方式匹配相关内容。
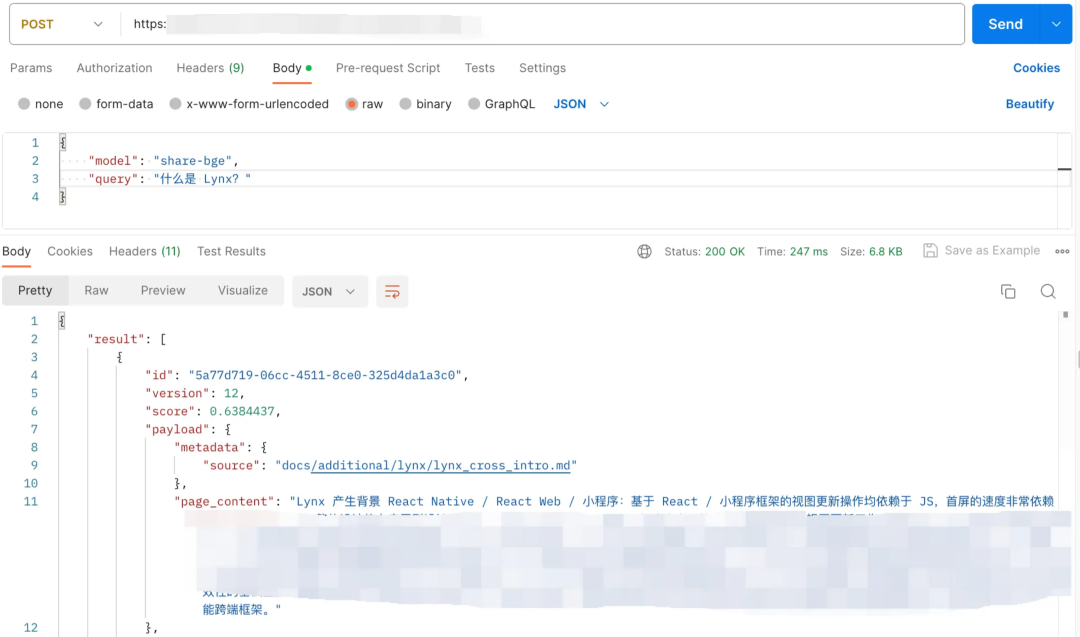
加载知识库
CR Copilot 知识库分为『内置官方文档知识库』、『自定义知识库』,query 输入是先用完整代码截取前半段 + LLM 生成 summary 总结,然后和知识库做相似上下文,匹配流程如下:
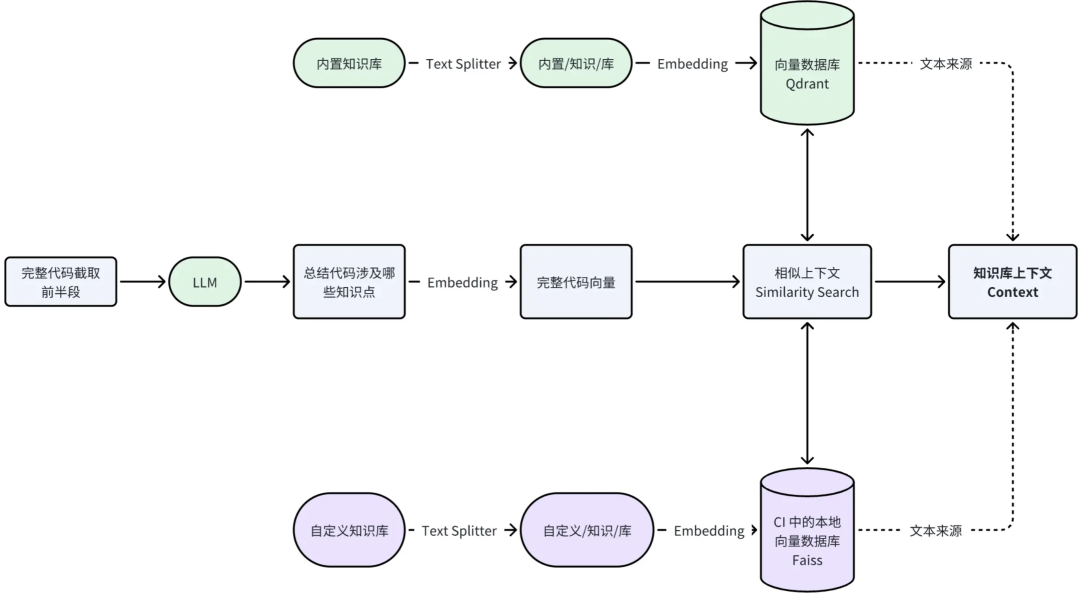
截取完整代码前半段作为 query 输入,是因为大部分语言前半段都声明了 modules、packages,通过这种方式提高知识库相似匹配度。
官方文档-知识库(内置)
避免大家将官方文档重复录入、embedding,CR Copilot 内置了官方文档,目录包含:
| 内容 | 数据源 |
|---|---|
| React 官方文档 | https://react.dev/learn |
| TypeScript 官方文档 | https://www.typescriptlang.org/docs/ |
| Rspack 官方文档 | https://www.rspack.dev/zh/guide/introduction.html |
| Garfish | https://github.com/web-infra-dev/garfish |
| 公司内 Go / Python / Rust 等编程规范 | … |
并通过一个简单的 CURD 来管理内置知识库
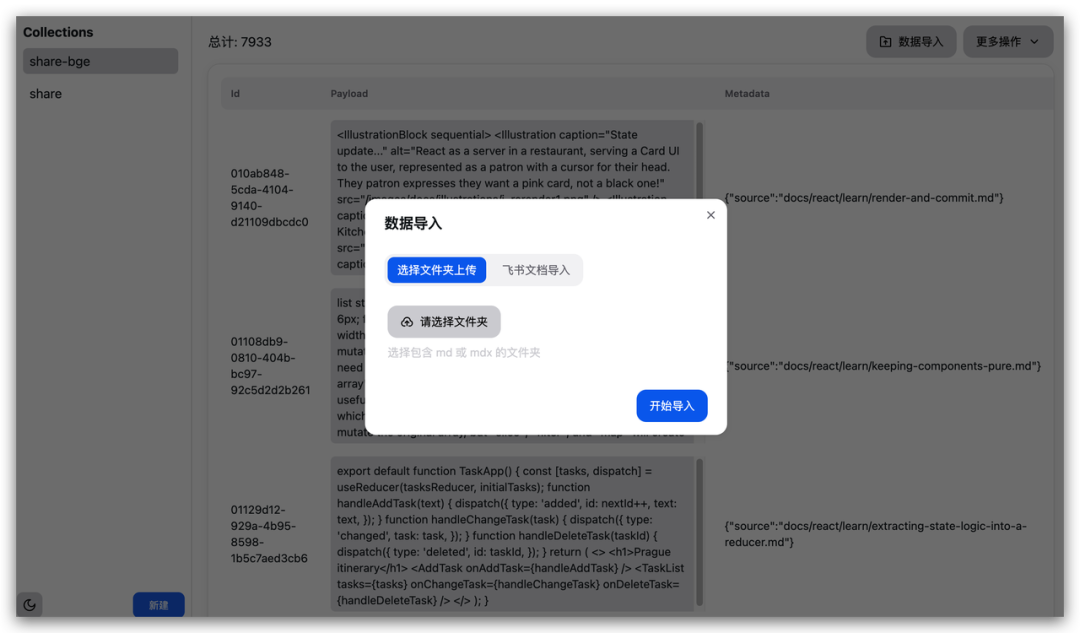
自定义知识库-飞书文档(自定义)
飞书文档没有格式要求,能看懂正确代码是怎样就行
这里直接使用 LangChain 提供的 LarkSuite[11] 文档加载类,对有权限的飞书文档进行获取,使用 CharacterTextSplitter / RecursiveCharacterTextSplitter 将文本分割成固定长度的块(chunks),方法有两个主要参数:
-
chunk_size: 控制每个块的长度。例如设置为 1024,则每个块包含 1024 个字符。 -
chunk_overlap: 控制相邻两个块之间的重叠长度。例如设置为 128,则每个块会与相邻块重叠 128 个字符。

Prompt 指令设计
因为大模型有足够多的数据,我们想让大模型按要求执行就需要用到『Prompt 提示词』。
 (图源 Stephen Wolfram)
(图源 Stephen Wolfram)
代码 summary 总结指令
让 LLM 通过文件代码分析当前代码涉及的知识点,用于后续知识库相似度匹配:
prefix = "user: " if model == "chatglm2" else "<s>Human: " suffix = "assistant(用中文): let's think step by step." if model == "chatglm2" else "\n</s><s>Assistant(用中文): let's think step by step." return f"""{prefix}根据这段 {language} 代码,列出关于这段 {language} 代码用到的工具库、模块包。 {language} 代码: ```{language} {source_code} ```请注意: - 知识列表中的每一项都不要有类似或者重复的内容 - 列出的内容要和代码密切相关 - 最少列出 3 个, 最多不要超过 6 个 - 知识列表中的每一项要具体 - 列出列表,不要对工具库、模块做解释 - 输出中文 {suffix}"""
其中:
-
language:当前文件的代码语言(TypeScript、Python、Rust、Golang 等) -
source_code:是当前变更文件的完整代码
CR 指令
如果使用的模型(如 LLaMA 2)对中文 Prompt 支持较差,需要在设计 Prompt 时采用『输入英文』『输出中文』的方式,即:
# llama2 f"""Human: please briefly review the {language}code changes by learning the provided context to do a brief code review feedback and suggestions. if any bug risk and improvement suggestion are welcome(no more than six) <context> {context} </context> <code_changes> {diff_code} </code_changes>\n</s><s>Assistant: """ # chatglm2 f"""user: 【指令】请根据所提供的上下文信息来简要审查{language} 变更代码,进行简短的代码审查和建议,变更代码有任何 bug 缺陷和改进建议请指出(不超过 6 条)。 【已知信息】:{context} 【变更代码】:{diff_code} assistant: """
其中:
-
language:当前文件的代码语言(TypeScript、Python、Rust、Golang 等) -
context:根据知识库返回的上下文信息 -
diff_code:是变更的代码(不使用完整代码主要是考虑 LLM max_tokens 最大限制)
评论到变更代码行
为了能计算出变更代码行,写了一个函数,通过解析 diff 来输出变更的行数:
import re def parse_diff(input): if not input: return [] if not isinstance(input, str) or re.match(r"^\s+$", input): return [] lines = input.split("\n") if not lines: return [] result = [] current_file = None current_chunk = None deleted_line_counter = 0 added_line_counter = 0 current_file_changes = None def normal(line): nonlocal deleted_line_counter, added_line_counter current_chunk["changes"].append({ "type": "normal", "normal": True, "ln1": deleted_line_counter, "ln2": added_line_counter, "content": line }) deleted_line_counter += 1 added_line_counter += 1 current_file_changes["old_lines"] -= 1 current_file_changes["new_lines"] -= 1 def start(line): nonlocal current_file, result current_file = { "chunks": [], "deletions": 0, "additions": 0 } result.append(current_file) def to_num_of_lines(number): return int(number) if number else 1 def chunk(line, match): nonlocal current_file, current_chunk, deleted_line_counter, added_line_counter, current_file_changes if not current_file: start(line) old_start, old_num_lines, new_start, new_num_lines = match.group(1), match.group(2), match.group( 3), match.group(4) deleted_line_counter = int(old_start) added_line_counter = int(new_start) current_chunk = { "content": line, "changes": [], "old_start": int(old_start), "old_lines": to_num_of_lines(old_num_lines), "new_start": int(new_start), "new_lines": to_num_of_lines(new_num_lines), } current_file_changes = { "old_lines": to_num_of_lines(old_num_lines), "new_lines": to_num_of_lines(new_num_lines), } current_file["chunks"].append(current_chunk) def delete(line): nonlocal deleted_line_counter if not current_chunk: return current_chunk["changes"].append({ "type": "del", "del": True, "ln": deleted_line_counter, "content": line }) deleted_line_counter += 1 current_file["deletions"] += 1 current_file_changes["old_lines"] -= 1 def add(line): nonlocal added_line_counter if not current_chunk: return current_chunk["changes"].append({ "type": "add", "add": True, "ln": added_line_counter, "content": line }) added_line_counter += 1 current_file["additions"] += 1 current_file_changes["new_lines"] -= 1 def eof(line): if not current_chunk: return most_recent_change = current_chunk["changes"][-1] current_chunk["changes"].append({ "type": most_recent_change["type"], most_recent_change["type"]: True, "ln1": most_recent_change["ln1"], "ln2": most_recent_change["ln2"], "ln": most_recent_change["ln"], "content": line }) header_patterns = [ (re.compile(r"^@@\s+-(\d+),?(\d+)?\s++(\d+),?(\d+)?\s@@"), chunk) ] content_patterns = [ (re.compile(r"^\ No newline at end of file$"), eof), (re.compile(r"^-"), delete), (re.compile(r"^+"), add), (re.compile(r"^\s+"), normal) ] def parse_content_line(line): nonlocal current_file_changes for pattern, handler in content_patterns: match = re.search(pattern, line) if match: handler(line) break if current_file_changes["old_lines"] == 0 and current_file_changes["new_lines"] == 0: current_file_changes = None def parse_header_line(line): for pattern, handler in header_patterns: match = re.search(pattern, line) if match: handler(line, match) break def parse_line(line): if current_file_changes: parse_content_line(line) else: parse_header_line(line) for line in lines: parse_line(line) return result
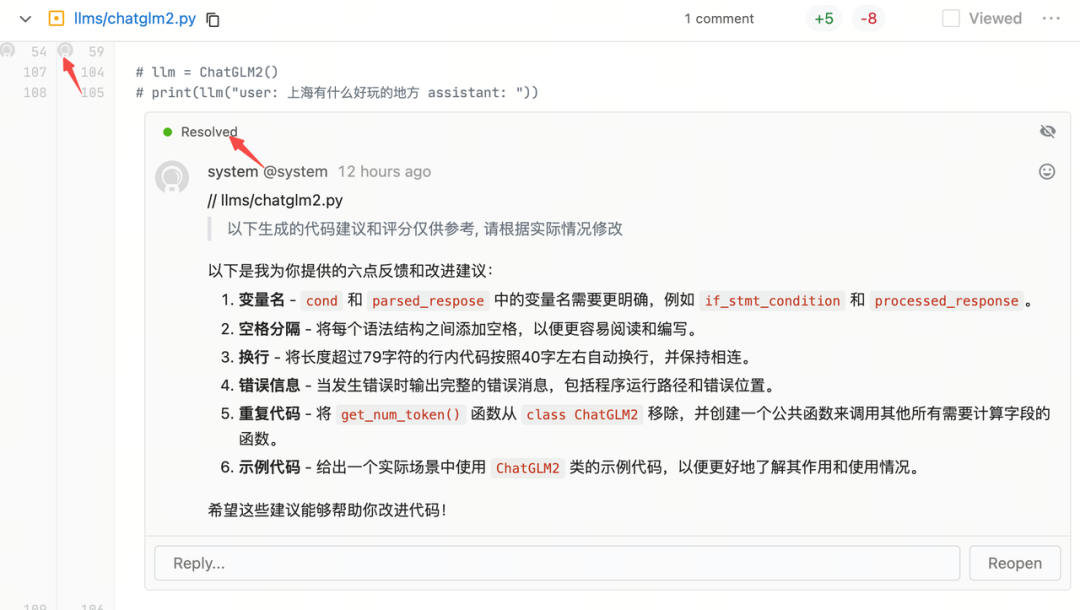
这里机器人账号调用 Gitlab API 进行的评论,会默认被 Resolved,这样可以避免 CR Copilot 评论过多造成每个评论要手动点下 Resolved
一点感想
-
一切皆概率:基于 LLM 的应用最大特点在于『输出不确定性』,在候选词中选概率最高的进行输出,即使像 1+1=? 这样看起来有确定性输出的,LLM 也是基于概率给出的!
-
开源 LLMs + 领域知识库 + 私有化部署是企业级应用的一种实践方式: :
-
这里 LLMs 指多个大模型组合使用;大模型再强大也必须结合内部的知识库才能发挥作用;
-
私有化部署好处是打消各行各业对数据安全的担忧!
-
大模型在 Chat 聊天的产品形态更多是秀肌肉 💪,让各行各业能被触达到;最终的产品形态需要具体场景具体分析!
-
AI+ 刚刚开始:CR Copilot 只是达人 LLMs + 研发工程化其中一个应用场景,还有一些应用/工具等达人团队打磨好后再和大家一起分享!
读者福利:如果大家对大模型感兴趣,这套大模型学习资料一定对你有用
对于0基础小白入门:
如果你是零基础小白,想快速入门大模型是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以根据这些资料规划好学习计划和方向。
包括:大模型学习线路汇总、学习阶段,大模型实战案例,大模型学习视频,人工智能、机器学习、大模型书籍PDF。带你从零基础系统性的学好大模型!
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

👉AI大模型学习路线汇总👈
大模型学习路线图,整体分为7个大的阶段:(全套教程文末领取哈)

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
👉大模型实战案例👈
光学理论是没用的,要学会跟着一起做,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

👉大模型视频和PDF合集👈
观看零基础学习书籍和视频,看书籍和视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。


👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











