






 本文详细介绍了如何处理elf文件中的UPX壳,并探讨了针对虚拟机保护的逆向技术,涉及修改UPX壳、RC4加密算法的魔改以及加密/解密过程。作者通过实例展示了如何分析和翻译特定的机器码指令,最终揭示了加密逻辑和解密方法。
本文详细介绍了如何处理elf文件中的UPX壳,并探讨了针对虚拟机保护的逆向技术,涉及修改UPX壳、RC4加密算法的魔改以及加密/解密过程。作者通过实例展示了如何分析和翻译特定的机器码指令,最终揭示了加密逻辑和解密方法。
知识点:elf魔改upx;vm逆向;魔改RC4
想了解vm逆向的可以学习一下这篇文章
【ELF去壳】
这里简单了解了一下elf加upx壳的时候修改几个要点,可以看一下下面这个文章。
[原创] UPX源码学习和简单修改-加壳脱壳-看雪-安全社区|安全招聘|kanxue.com
做题遇到的魔改情况
1.修改UPX 为其他字符 如 RPX这样
2.(出现在elf文件中)修改最后的 overlay_offset占据4字节大小(p_info字段的文件偏移)
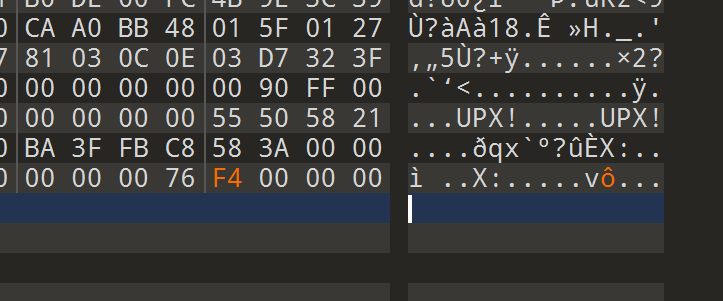
这里抹除了最后四个字节的数据
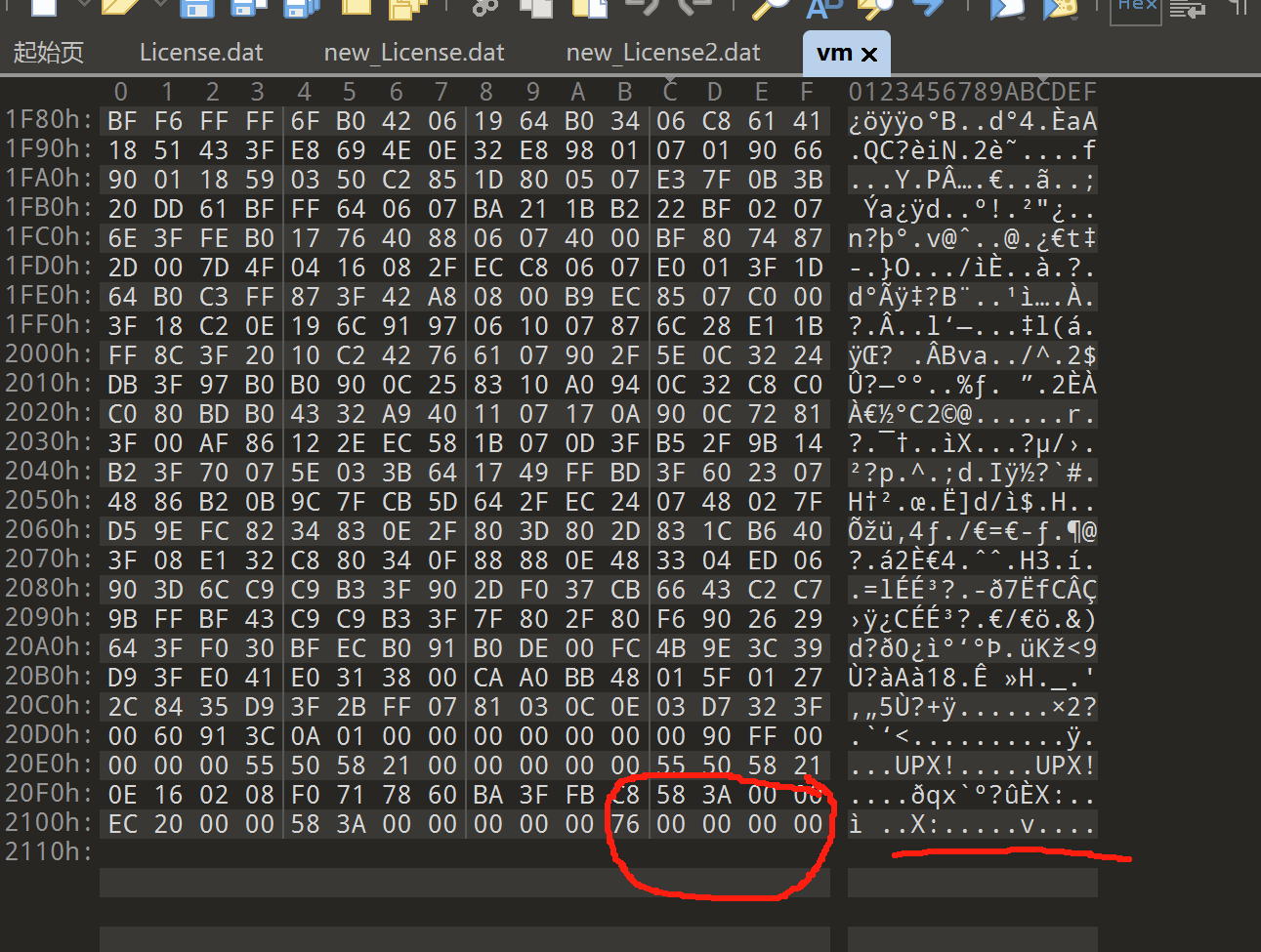
我们修改成 F4 00 00 00就可正常./upx -d 脱壳了
【vm初探】
进入主函数,改一下函数的名称,真正开始起作用的就是涉及到v3的两个函数了。
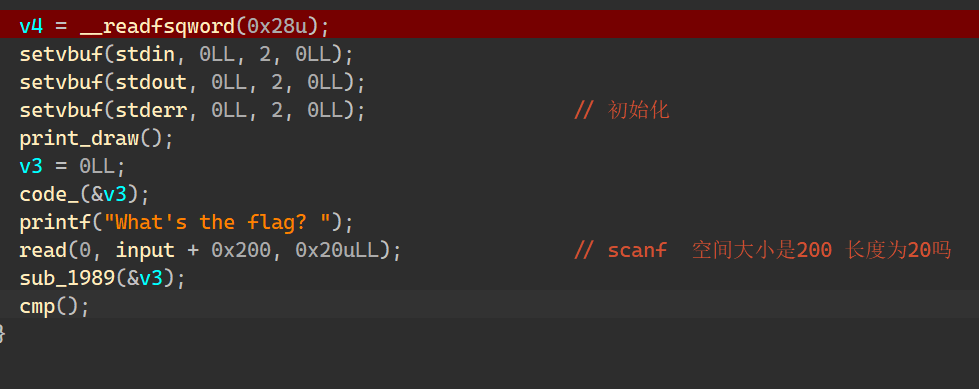
现在还没有看到vm的影子,我们分析一下这俩函数
第一个code函数,引用了指针v3对其进行填充
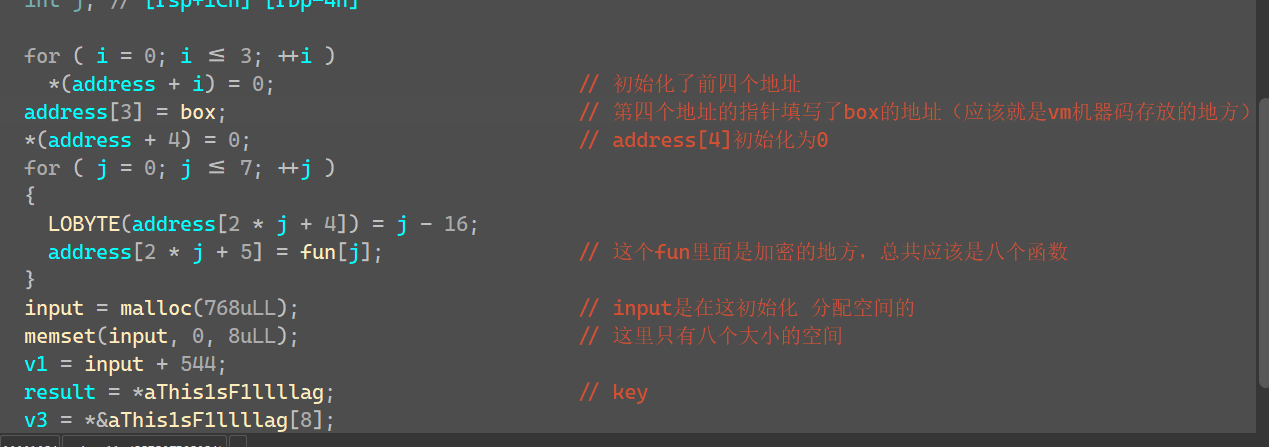
点开看box的数据,发现最后一个数据是唯一的0xF8
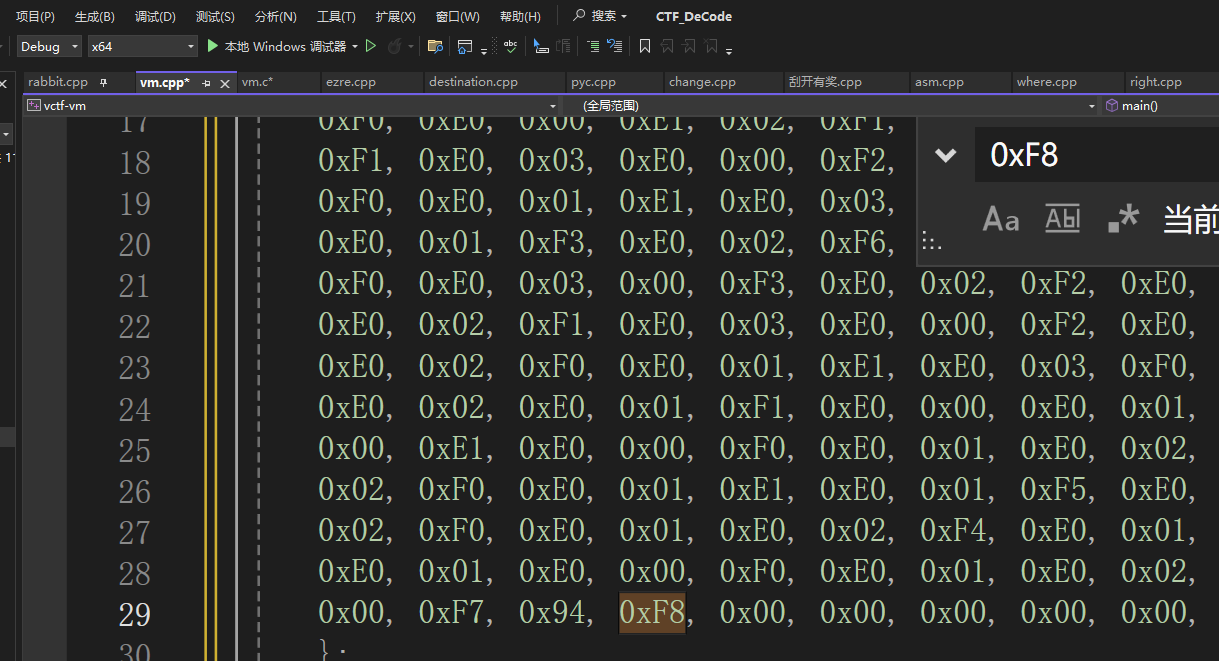
结合第二个函数里面,当走到这个数的时候就退出while进入cmp函数,我们分析出来机器码就是在box中储存的,让并且在fun中形成汇编语言进行加密。
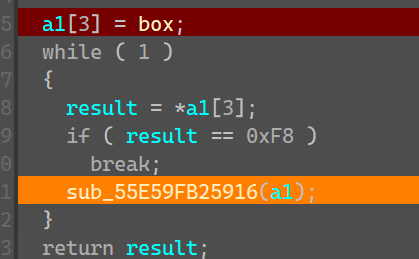
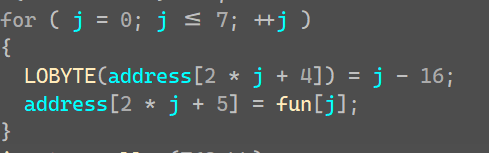
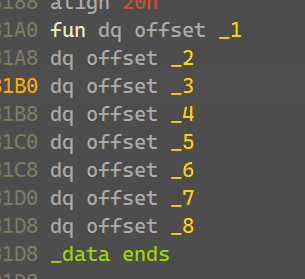
1-8就是我们的加密函数了,他的作用就是组合box中的机器码,不同的码对应不同的翻译,我们再看看哪里可以找到这个对应关系的表
分析这两条代码
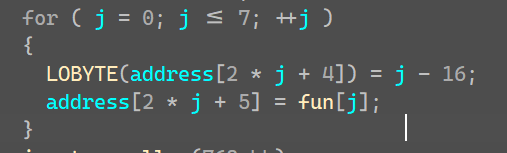
上者在v3的地址4,6,8········18这八个位置存储了 -16,-15············,-9这几个值(对应的16进制考虑正负的转换,就是0xF0,0xF1········)
下面的在v3地址5,7,9········19这八个位置存储了上面的八个函数
这16个位置在哪用到了呢,在第二个函数里面的函数用到了,条件就是如果这个result的值为*a1[3](这个值就是box[0]是0xF0)的话返回v3奇数(函数)参数为a1,如果是其他值就返回v3偶数位

翻译第一次怎么走的,找到规律。开始分析:
几个关键的点:
a1[0],a1[1],a1[2]这三个位置都为0,a1[3]存储了box[0]的地址,a1[4]一直到a1[19]就是上面提到的函数和数值。
进入第二个函数之后,先给result(下面简称res)赋值a1偶数位的值,进行判断,第一次是4,对应-16也就是0xF0,此时a1[3]也就是box[0]的位置就是0xF0,条件成立,返回了第a1[5]也就是函数_1,参数是a1这个指针。
【函数翻译】
跟进函数_1并翻译
// 传进来的是a1的首地址
__int64 *__fastcall 1(__int64 *a1)
{
__int64 *result; // rax
int v2; // eax
int v3; // ecx
int i; // [rsp+14h] [rbp-4h]
for ( i = 1; ; ++i )
{
result = *(a1[3] + i);
if ( result > 0xEFu ) // 这里就是在 0xF0,0XF1这几个值往上,就是对应的1,2,3····这几个函数
break;
} //根据box去找值之后,遇到0xF0时,i=4
if ( i == 6 )
{
v2 = *(a1[3] + 1);
if ( v2 == 224 )
{
if ( *(a1[3] + 4) == 224 )
v3 = input[*(a1 + *(a1[3] + 5))];
else
v3 = input[((*(a1[3] + 5) << 8) + *(a1[3] + 4))];
*(a1 + *(a1[3] + 2)) = v3;
}
else if ( v2 == 225 )
{
input[*(a1 + *(a1[3] + 3))] = *(a1 + *(a1[3] + 5));
}
result = a1;
a1[3] += 6LL;
}
else if ( i <= 6 )
{
if ( i == 4 ) // 第一次进入的地方
{ //我们就一步一步带入进去box取值,看看是什么操作
*(a1 + *(a1[3] + 2)) = *(a1[3] + 3); // mov操作,寄存器值的存储
result = a1; // result清空,变成a1[0]
a1[3] += 4LL; // 跳转到下一个0xF0
}
else if ( i == 5 )
{
*(a1 + *(a1[3] + 2)) = *(a1 + *(a1[3] + 4));
result = a1;
a1[3] += 5LL;
}
} // 返回了a1[0]的地址
return result; // 第一次结束之后,发生了改变的值就是a1[3]原本是box[0]的位置,现在成了box[4],
}经过了如上的分析,我们得到了结论,box中的一条完整的指令是在 大于0xF0的机器码之间实现的。
不同的0xF*就对应了不同的汇编指令,在此之间的就是指令后面形如寄存器,数据的东西。
这里的0xF0就是 MOV指令,
第一次操作翻译过来就是
MOV a1[2] , a1[0]我们也就清楚了a1的前三位类似于寄存器。
最后a1[3]存储了box的下一条函数指令(又是0xF0 MOV 的位置)于是开始了下一条指令。
我们来到了这,这时res的值又是0xF0,是MOV指令,进行的操作和上面差不多,我们来分析2-8的函数都是啥意思。
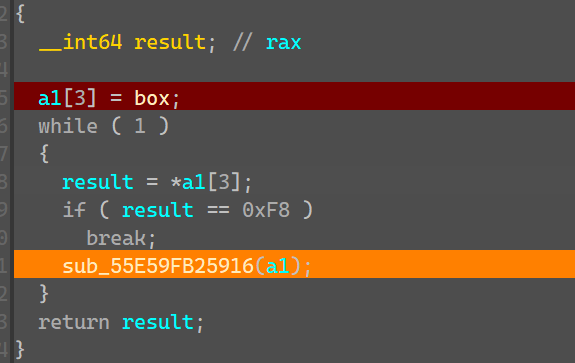
可以用代码生成类似汇编的形式,然后进行翻译。
每个函数的原式就不贴了,逐个跟进,结合下面的汇编进行分析就能翻译出来每个函数的意思了。
0xF0, 0xE0, 0x02, 0x00,
0xF0, 0xE0, 0x00, 0xE0, 0x02,
0xF0, 0xE1, 0xE0, 0x02, 0xE0, 0x02,
0xF0, 0xE0, 0x01, 0x10,
0xF2, 0xE0, 0x00, 0xE0, 0x01, //F2 :执行了 v1 = a1[0] % a1[1]
0xF1, 0xE0, 0x00, 0x20, 0x02, //普通的F1 :执行了((*(a1[3] + 4) << 8) + *(a1[3] + 3)) + *(a1 + v3);
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x00, //长度为6的F0 :两次E0判断,然后v3 = input[0]
0xF0, 0xE0, 0x01, 0xE0, 0x02, //长度为5的F0 :a1[1] = a1[2]
0xF1, 0xE0, 0x01, 0x00, 0x01, //F1翻译 : a1[1] = 2 * a1[1]
0xF0, 0xE1, 0xE0, 0x01, 0xE0, 0x00,
0xF3, 0xE0, 0x02, //F3 :给寄存器a1[2]加1
0xF6, 0xE0, 0x02, 0x00, 0x01, //F6 :前者寄存器的值小于 256,那么就把a1[4]的值变成1
0xF7, 0x04, //循环跳转,如果没有大于256,那么就跳转到上面的第二行代码
0xF0, 0xE0, 0x02, 0x00,
0xF0, 0xE0, 0x03, 0x00,
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x02, //循环跳转处
0xF1, 0xE0, 0x03, 0xE0, 0x00, //遇到了0xE0的F1 :执行了*(a1 + *(a1[3] + 4)) + *(a1 + v3);
0xF0, 0xE0, 0x00, 0xE1, 0x02,
0xF1, 0xE0, 0x00, 0x00, 0x01,
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x00,
0xF1, 0xE0, 0x03, 0xE0, 0x00,
0xF2, 0xE0, 0x03, 0x00, 0x01,
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x02,
0xF0, 0xE0, 0x01, 0xE1, 0xE0, 0x03,
0xF0, 0xE1, 0xE0, 0x03, 0xE0, 0x00,
0xF0, 0xE1, 0xE0, 0x02, 0xE0, 0x01,
0xF3, 0xE0, 0x02,
0xF6, 0xE0, 0x02, 0x00, 0x01, 小于256
0xF7, 0x45, //结束之后跳转到到17行
0xF0, 0xE0, 0x02, 0x00,
0xF0, 0xE0, 0x03, 0x00, //循环跳转处
0xF3, 0xE0, 0x02,
0xF2, 0xE0, 0x02, 0x00, 0x01,
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x02,
0xF1, 0xE0, 0x03, 0xE0, 0x00,
0xF2, 0xE0, 0x03, 0x00, 0x01,
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x02,
0xF0, 0xE0, 0x01, 0xE1, 0xE0, 0x03,
0xF0, 0xE1, 0xE0, 0x03, 0xE0, 0x00,
0xF0, 0xE1, 0xE0, 0x02, 0xE0, 0x01,
0xF1, 0xE0, 0x00, 0xE0, 0x01,
0xF2, 0xE0, 0x00, 0x00, 0x01,
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x00,
0xF0, 0xE0, 0x01, 0xE0, 0x02,
0xF4, 0xE0, 0x01, //F4 :让寄存器a1[1]减1
0xF1, 0xE0, 0x01, 0x00, 0x02,
0xF0, 0xE0, 0x01, 0xE1, 0xE0, 0x01,
0xF5, 0xE0, 0x00, 0xE0, 0x01, //F5 :异或操作 a1[0] ^= a1[1]
0xF1, 0xE0, 0x00, 0xE0, 0x02, //这里是RC4魔改的地方,一般的RC4在最后的异或之后就会进行
0xF0, 0xE0, 0x01, 0xE0, 0x02, 下一次循环,这里还有别的操作。
0xF4, 0xE0, 0x01,
0xF1, 0xE0, 0x01, 0x00, 0x02,
0xF0, 0xE1, 0xE0, 0x01, 0xE0, 0x00,
0xF0, 0xE0, 0x01, 0xE0, 0x02,
0xF4, 0xE0, 0x01,
0xF6, 0xE0, 0x01, 0x20, 0x00, //特殊的F6 :这里是a1[1] < 0x20 (36)就是我们的input长度
0xF7, 0x94,
0xF8, //结束指令综上得出结论:
F0 MOV
F1 ADD
F2 MOD取余(一种是取余寄存器值,另一种是256)
F3 INC递加1
F4 DEC递减1
F5 XOR
F6 CMP
F7 JMP
理解了大致的意思,再翻译成汇编
结束初始化进入加解密部分(这里把 a1[] 简写为 a[] )
0xF0, 0xE0, 0x02, 0x00, mov a[2] 0
0xF0, 0xE0, 0x03, 0x00, //循环跳转处 mov a[3] 0 新的寄存器
0xF3, 0xE0, 0x02, a[2] ++ //推断出a2就是循环加的i
0xF2, 0xE0, 0x02, 0x00, 0x01, a[2] %= (256 + 0) a3可能就是循环的j
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x02, a[0] = input[a[2]]
0xF1, 0xE0, 0x03, 0xE0, 0x00, a[3] += a[0]
0xF2, 0xE0, 0x03, 0x00, 0x01, a[3] %= (256 + 0)
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x02, a[0] = input[a[2]] 交
0xF0, 0xE0, 0x01, 0xE1, 0xE0, 0x03, a[1] = input[a[3]] 换
0xF0, 0xE1, 0xE0, 0x03, 0xE0, 0x00, input[a[3]] = a[0] 函 input其实就是box的角色
0xF0, 0xE1, 0xE0, 0x02, 0xE0, 0x01, input[a[2]] = a[1] 数
0xF1, 0xE0, 0x00, 0xE0, 0x01, a[0] += a[1]
0xF2, 0xE0, 0x00, 0x00, 0x01, a[0] %= (256 + 0)
0xF0, 0xE0, 0x00, 0xE1, 0xE0, 0x00, a[0] = input[a[0]]
0xF0, 0xE0, 0x01, 0xE0, 0x02, a[1] = a[2]
0xF4, 0xE0, 0x01, a[1] --
0xF1, 0xE0, 0x01, 0x00, 0x02, a[1] += 0x200 (512)
0xF0, 0xE0, 0x01, 0xE1, 0xE0, 0x01, a[1] = input[a[1]]RC4异或部分
0xF5, 0xE0, 0x00, 0xE0, 0x01, a1[0] ^= a1[1] a0貌似才是我们输入的数据
0xF1, 0xE0, 0x00, 0xE0, 0x02, a1[0] += a1[2] 关键就是这里,他在这多了一步加密
0xF0, 0xE0, 0x01, 0xE0, 0x02, mov a1 a2 a1[1] = a1[2]
0xF4, 0xE0, 0x01, sub a1[1]--
0xF1, 0xE0, 0x01, 0x00, 0x02, a1[1] += 0x200 (512)
0xF0, 0xE1, 0xE0, 0x01, 0xE0, 0x00, input[a1[1]] = a1[0] 属于i=6的mov
0xF0, 0xE0, 0x01, 0xE0, 0x02, a1[1] = a1[2]
0xF4, 0xE0, 0x01, sub a1[1]--
0xF6, 0xE0, 0x01, 0x20, 0x00, a1[1] < 36
0xF7, 0x94,总体看下来就是这样,跟RC4的区别感觉就在 a1[0] += a1[2] 这一步的代码,a1[2]在纸上一步一步分析知道了是
理解了大致的意思就开始修改一下之前的脚本
魔改RC4脚本
因为加密的最后一步异或相当于a1[0] = (a1[0] ^ a1[1]) + a1[2]
换成相应的值就是 data = (data ^ s盒 )+i;
逆向过来解码就要先data减去i,然后在进行最后的异或操作
#include<stdio.h>
#include<string.h>
/*
RC4初始化函数
*/
void rc4_init(unsigned char* s, unsigned char* key, unsigned long Len_k)
{
int i = 0, j = 0;
char k[256] = { 0 };
unsigned char tmp = 0;
for (i = 0; i < 256; i++) {
s[i] = i;
k[i] = key[i % Len_k];
}
for (i = 0; i < 256; i++) {
j = (j + s[i] + k[i]) % 256;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
}
}
/*
RC4加解密函数
unsigned char* Data 加解密的数据
unsigned long Len_D 加解密数据的长度
unsigned char* key 密钥
unsigned long Len_k 密钥长度
*/
void rc4_crypt(unsigned char* Data, unsigned long Len_D, unsigned char* key, unsigned long Len_k) //加解密
{
unsigned char s[256];
rc4_init(s, key, Len_k);
int i = 0, j = 0, t = 0;
unsigned long k = 0;
unsigned char tmp;
int cc;
for (k = 0; k < Len_D; k++) {
i = (i + 1) % 256;
cc = (Data[k] - i);
j = (j + s[i]) % 256;
tmp = s[i];
s[i] = s[j];
s[j] = tmp;
t = (s[i] + s[j]) % 256;
Data[k] = cc ^ s[t];//魔改在这
}
}
void main()
{
//字符串密钥
unsigned char key[] = "This_1s_f1lLllag";
unsigned long key_len = sizeof(key)-1 ;//密钥长度出错了啊啊啊啊
unsigned char data[] = { 0x56, 0x54, 0xD9, 0xB5, 0xF3, 0xB1, 0xFD, 0x67, 0x15, 0xEE, 0xB0, 0x68, 0xB7, 0x2B, 0x4A, 0x64,
0x10, 0x27, 0x52, 0xDE, 0x43, 0x26, 0x0F, 0x2A, 0x41, 0x30, 0x75, 0x30, 0x98, 0x9E, 0x79, 0x5E };
rc4_crypt(data, sizeof(data), key, key_len);
for (int i = 0; i < 32; i++)
{
printf("%c", data[i]);
}
return;
}
最后解密的时候结果总是出错,才发现又是细节问题,这个密钥长度由于是sizeof的用法,算上了字符串最后结束标识符,导致长度多了一位,一定要记得减1(有机会复习一下基础知识做笔记)
flag{711df52879efbcb8964b6056d926ea35}


















 3676
3676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









