







PS:欢迎转载,但请注明出处,谢谢配合。
ik分词器安装和验证(基于elasticsearch-7.10.1)
一、安装
1、下载
登录GitHub,搜索ik,可以找到ik分词器项目,
具体地址为: https://github.com/medcl/elasticsearch-analysis-ik
根据简介,找到releases,下载对应zip包,如:elasticsearch-analysis-ik-7.10.1.zip(注意,版本号跟ElasticSearch保持一致)
2、新建插件子目录
进入elasticsearch的 plugins 目录,(如:…\elasticsearch-7.10.1\plugins)
在plugins中新建子目录 ,子目录名字自定义,主要为了归类用,只要不含中文和非法字符,这里命名为ik
3、解压ik插件包
将ik的压缩包内容,解压到 …\elasticsearch-7.10.1\plugins\ik 中
4、重启elasticsearch
启动日志中,会有如下日志信息,说明ik插件加载成功:
[2021-01-30T13:59:14,727][INFO ][o.e.p.PluginsService ] [DESKTOP-C1UJUTI] loaded plugin [analysis-ik]
补充说明:
ik 目前提供了两种分词器 ik_max_word 和 ik_smart
ik_max_word : 细粒度分词,会穷尽一个语句中所有分词可能
ik_smart : 粗粒度分词,优先匹配最长词
按照一般情况来讲,索引分词应该按照最细粒度来分词,搜索分词可按最粗粒度来分词
二、验证(查看分词效果)
1、standard 分词器效果
POST http://localhost:9200/person/_analyze
{
"analyzer": "standard",
"text": "我是中国人"
}
分词效果:
我 / 是 / 中 / 国 / 人
2、ik_smart 分词器效果
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
分词效果:
我 / 是 / 中国人

3、ik_max_word 分词器效果
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
分词效果:
我 / 是 / 中国人 / 中国 / 国人

三、实际使用效果对比
索引中的测试数据,内容如下:
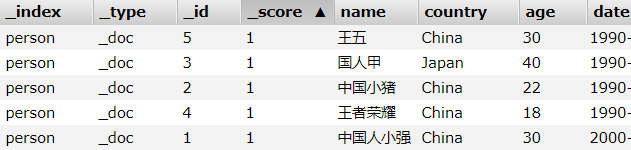
1、创建索引时,文档中的列使用默认分词器
"mappings": {
"properties": {
"name": {
"type": "text"
},
......
}
}
搜索“王者”, 能匹配到“王者荣耀” 和 “王五”,
因为“王者荣耀”和“王五”经过分词,分别得到“王”、“者”、“荣”、“耀” 和 “王”、“五”,
搜索词经过分词,得到"王"和“者”,与“王者荣耀”和“王五”的分词结果都能匹配到。

2、创建索引时,文档中的列指定ik_max_word分词器
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer" : "ik_max_word"
},
......
}
}
搜索“王者”,只匹配到“王者荣耀”,
因为“王者荣耀”经过分词,得到“王者”、“荣耀”;“王五”经过分词,得到“王”、“五”,
搜索词经过分词,得到“王者”,与“王者荣耀”的分词结果匹配。
















 528
528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









