






前言
提示:本博客是依托B站【刘二大人】的讲解视频并结合个人实践学习总结而成,仅用作记录本人学习巩固,请勿做商用。
本讲会用到面向对象编程的基础知识:可以参考我之前的博客:
类、实例、方法函数相关内容
继承的相关内容
一、SGD
我们采用Mini-Batch实现随机梯度下降算法(其实并没有随机,因为数据集太小了),主要为以下四个步骤:
- 数据集建立
- 设计模型
- 计算损失、构造优化器
- 训练
1.1数据集建立
因为要使用Mini-Batch,我们要建立3*1的列向量,利用矩阵来一次性计算三个预测值,这和之前是不一样的:
x_data = torch.tensor([[1.0],[2.0],[3.0]]) #第一步:数据集建立
y_data = torch.tensor([[2.0], [4.0], [6.0]]) # 3*1的列向量其中每个数据又是一个一维的矩阵
1.2设计模型
class LinearModel(torch.nn.Module): #第二步:模型设计,继承自nn.Module
def __init__(self):
super(LinearModel,self).__init__( )
self.linear=torch.nn.Linear(1,1)#输入维度和输出维度都是1(要求相同),偏置默认True
#继承自nn.Module,包括一个线性单元(权重和偏置)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model=LinearModel( )
其中涉及面向对象编程的知识:
nn.Module是父类,LinearModel是子类,继承了父类的所有属性和方法函数。
nn.Linear也是nn.Module的子类,它包含了一个线性单元,其具体参数设置如图:

- 输入输出维度一致
- 偏置的布尔值默认为True
1.3计算损失、构造优化器
#第三步:计算损失 构造优化器
criterion = torch.nn.MSELoss(size_average=False)#继承自nn.Module
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)#model.parameters()自动完成参数的初始化操作,设置学习率
#torch.optim.SGD与torch.nn.Module无关,不参与构建计算图
需要注意的是:
- nn.MSELoss继承自nn.Module,其中参数设置如下:
(1)reduce=False,size_average参数失效,直接返回向量形式的loss。
(2)reduce=True,那么loss返回的是标量。
(3)size_average=True,返回的是loss.mean()
(4)size_average=False,返回的是loss.sum()
注意:默认情况下, reduce = True,size_average = True
- torch.optim.SGD与torch.nn.Module无关,不参与构建计算图。
- model.parameters()自动完成参数的初始化操作。
1.4 训练
for epoch in range(1000):
y_pred = model(x_data) # 前馈过程
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # 为避免累加,梯度置零
loss.backward() # 反向传,播自动计算梯度
optimizer.step() #更新权重和偏置
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data.item( ))
1.5 完整代码及运行结果
我又加了可视化,更加直观:
import torch
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0],[2.0],[3.0]]) #第一步:数据集建立
y_data = torch.tensor([[2.0], [4.0], [6.0]]) # 3*1的列向量其中每个数据又是一个一维的矩阵
class LinearModel(torch.nn.Module): #第二步:模型设计,继承自nn.Module
def __init__(self):
super(LinearModel,self).__init__( )
self.linear=torch.nn.Linear(1,1)#输入维度和输出维度都是1(要求相同),偏置默认True
#继承自nn.Module,包括一个线性单元(权重和偏置)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model=LinearModel( )
#第三步:计算损失 构造优化器
criterion = torch.nn.MSELoss(size_average=False)#继承自nn.Module,不求均值
optimizer = torch.optim.SGD(model.parameters(),lr=0.01)#model.parameters()自动完成参数的初始化操作,设置学习率
#torch.optim.SGD与torch.nn.Module无关,不参与构建计算图
#第四步:训练
epoch_list=[]
loss_list=[]
for epoch in range(1000):
y_pred = model(x_data) # 前馈过程
loss = criterion(y_pred, y_data)
print(epoch, loss.item())
optimizer.zero_grad() # 为避免累加,梯度置零
loss.backward() # 反向传,播自动计算梯度
optimizer.step() #更新权重和偏置
epoch_list.append(epoch)
loss_list.append(loss.item())
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data.item( ))
plt.plot(epoch_list,loss_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
运行结果:
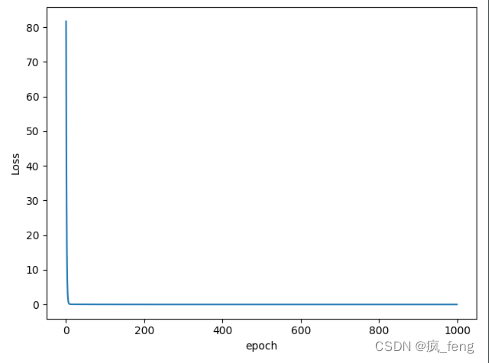
...
...
...
993 2.9823695513186976e-08
994 2.936377541118418e-08
995 2.8926763206982287e-08
996 2.85718328996154e-08
997 2.812157617881894e-08
998 2.7771648092311807e-08
999 2.734691406658385e-08
w = 1.9998899698257446
b = 0.0002502253046259284
y_pred = 7.999810218811035
当训练轮数设置为1000轮时,收敛效果不错,但是在实际的运用中,我们不能只考虑损失函数的收敛程度,还要根据测试集的测试效果,修改模型、设置合理的训练轮数。
二、练习
其他的模型(有的尚未接触过,先浅看一下):传送门
- optim.Adagrad:自适应学习率梯度下降法
- optim.RMSprop: Adagrad的改进
- optim.Adam:RMSprop结合Momentum
- optim.Adamax:Adam增加学习率上限
- optim.ASGD:随机平均梯度下降
- optim.Rprop:弹性反向传播
- optim.LBFGS:BFGS的改进
各个算法结果对比:
- AdaGrad算法
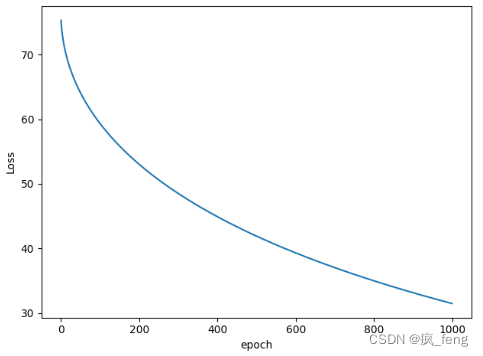
- Adam算法
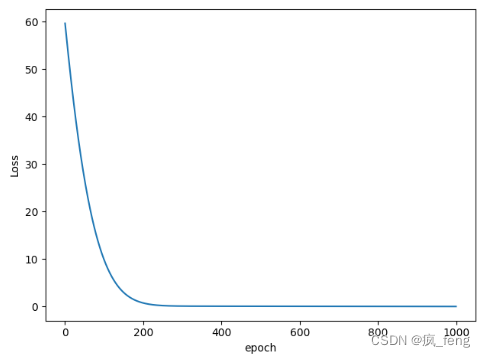
- Adamax算法
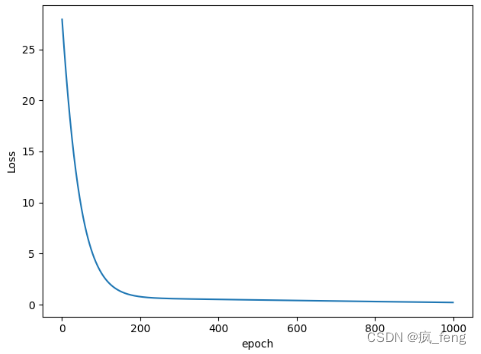
- ASGD算法
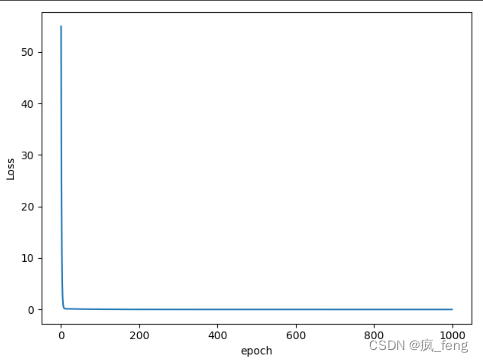
- LBFGS 算法和以上其他的优化器有一些不同,LBFGS需要重复多次计算函数,因此你需要传入一个闭包去允许它们重新计算你的模型,这个闭包应当清空梯度,计算损失,然后返回,即optimizer.step(closure);其他的优化器支持简化的版本即optimizer.step()。
如果直接修改优化器类型的话就会这样报错:
Traceback (most recent call last):
File "D:/py/pytorch/刘二大人/linear_model_by_pytorch.py", line 35, in <module>
optimizer.step() #更新权重和偏置
File "D:\anconda\envs\pytorch-cpu\lib\site-packages\torch\optim\optimizer.py", line 88, in wrapper
return func(*args, **kwargs)
File "D:\anconda\envs\pytorch-cpu\lib\site-packages\torch\autograd\grad_mode.py", line 27, in decorate_context
return func(*args, **kwargs)
TypeError: step() missing 1 required positional argument: 'closure'
所以我们加一个闭包optimizer.step(closure):
import torch
import matplotlib.pyplot as plt
x_data = torch.tensor([[1.0],[2.0],[3.0]]) #第一步:数据集建立
y_data = torch.tensor([[2.0], [4.0], [6.0]]) # 3*1的列向量其中每个数据又是一个一维的矩阵
class LinearModel(torch.nn.Module): #第二步:模型设计,继承自nn.Module
def __init__(self):
super(LinearModel,self).__init__( )
self.linear=torch.nn.Linear(1,1)#输入维度和输出维度都是1(要求相同),偏置默认True
#继承自nn.Module,包括一个线性单元(权重和偏置)
def forward(self,x):
y_pred = self.linear(x)
return y_pred
model=LinearModel( )
#第三步:计算损失 构造优化器
criterion = torch.nn.MSELoss(size_average=False)#继承自nn.Module,不求均值
optimizer = torch.optim.LBFGS(model.parameters(),lr=0.01)#model.parameters()自动完成参数的初始化操作,设置学习率
#torch.optim.SGD与torch.nn.Module无关,不参与构建计算图
#第四步:训练
epoch_list=[]
loss_list=[]
for epoch in range(1000):
def closure():
optimizer.zero_grad()
y_pred = model(x_data)
loss = criterion(y_pred, y_data)
print(epoch, loss)
epoch_list.append(epoch)
loss_list.append(loss.item())
loss.backward()
return loss
optimizer.step(closure)
print('w = ', model.linear.weight.item())
print('b = ', model.linear.bias.item())
x_test = torch.tensor([[4.0]])
y_test = model(x_test)
print('y_pred = ', y_test.data.item( ))
plt.plot(epoch_list,loss_list)
plt.ylabel('Loss')
plt.xlabel('epoch')
plt.show()
看出区别了吧,运行结果:
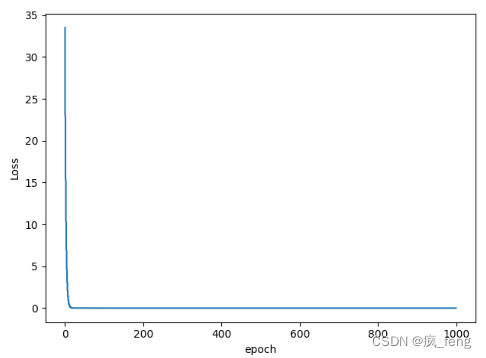
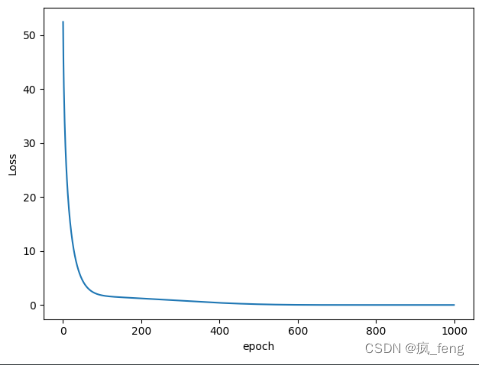
-
RMSprop算法
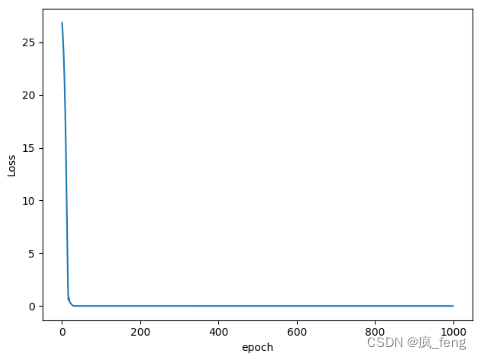
-
Rprop
总结
这个系列已经学了一礼拜了,真的很新手向对吧!
放一个官网链接:查看更多的实例教程















 433
433











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









