







目录
2.字符递归分割(Recursively split by character)
四、文本嵌入模型(Text embedding models)
2.自查询检索器(Self Query Retriever)
前言
在人工智能的领域中,大模型的应用已经成为一种趋势。然而,大型语言模型(LLM)的应用程序往往需要特定于用户的数据,这些数据并不属于模型的训练集。为了实现这一目标,我们通常采用检索增强生成(Retrieval-augmented Generation,RAG)的方法。在此过程中,我们将从外部检索数据,然后在执行生成步骤时将其传递给 LLM。LangChain框架提供了一套完整的工具,以支持RAG应用程序的开发。它包括了文档加载器、文档转换器、文本嵌入模型、向量存储和检索器等组件,实现了数据的加载、转换、存储和查询。
一、概述
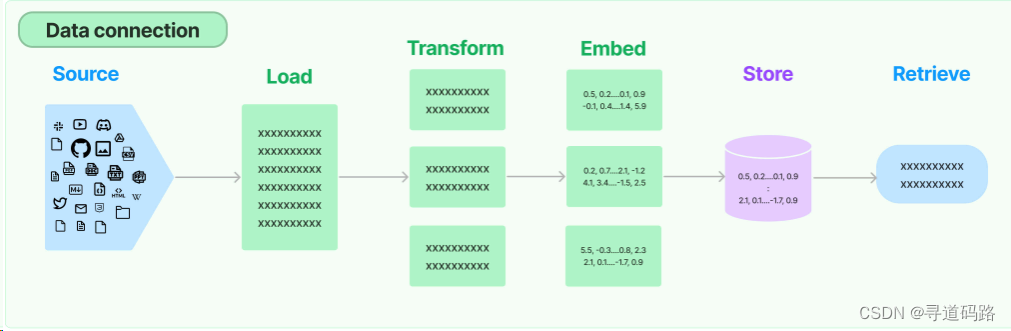
Retrieval模块的工作流程:
1、source:首先外部资源的准备
2、load:加载解析外部资源信息(包括CSV、Text、PDF、MarkDown等多种文档解析器)。
3、Transform:采用不同的分割策略、对数据进行分割转换处理。
4、Embed:将转换后的数据进行向量化。
5、Store:将向量化的数据进行存储,放入向量数据库。
6、Retrieve:Retrieval的核心模块,提供了多种类型的检索器,通过不同方式从向量数据库中检索到数据返回给用户。
二、 文档加载器(Document loaders)
文档加载器加载来自许多不同来源的文档。 LangChain 提供多种不同的文档加载器,支持多种类型位置(私有 S3 存储桶、公共网站)加载所有类型文档(HTML、PDF、代码)的集成。
1.CSVLoader
CSV文件加载器
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="data/data1.csv", encoding="utf-8")
data = loader.load()
print(data)2.TextLoader
Text文档加载器
from langchain.document_loaders import TextLoader
docs = TextLoader('消失的她.txt', encoding="utf-8").load()
docs
with open('消失的她.txt', encoding="utf-8") as f:
document = f.read()#%%print(document)3.MarkdownLoader
MarkDown文档加载器
from langchain_community.document_loaders import UnstructuredMarkdownLoader
markdown_path = "data/README.md"
loader = UnstructuredMarkdownLoader(markdown_path)
data = loader.load()三、文档分割转换器(Text Splitting)
检索的关键部分是仅获取文档的相关部分。这涉及几个转换步骤来准备文档以供检索。这个模块主要任务是将大文档分割(或分块)为更小的块。
1.基于字符分割(Split by character)
基于字符(默认为“”)进行拆分,并按字符数测量块长度
with open("data/test.txt") as f:
state_of_the_union = f.read()
#%%
from langchain_text_splitters import CharacterTextSplitter
text_splitter = CharacterTextSplitter(
separator="\n\n",#指定了用于分割文本的分隔符为两个连续的换行符
chunk_size=20,#指定了每个分割后的文本块的大小为20个字符
chunk_overlap=10,#指定了相邻文本块之间的重叠大小为10个字符,避免信息丢失
length_function=len,#指定了计算字符串长度的函数为内置的len函数
is_separator_regex=False,#指定了分隔符不是一个正则表达式
)
#%%
texts = text_splitter.create_documents([state_of_the_union])
print(texts[0])
print(texts[1])
#输出
page_content='Madam Speaker, Madam Vice President,our First Lady and Second Gentleman.'
page_content='Members of Congress and the Cabinet.'2.字符递归分割(Recursively split by character)
将文本字符串分割成更小片段的方法,这个过程是递归的,它会不断地重复执行,直到满足某个终止条件。这种拆分方式可能用于多种场景,比如分词、句子边界检测或者创建文档的索引
- 基于字符的分割:这种分割方法会逐个查看文本中的字符,根据字符的特性来决定如何进行分割。
- 递归过程:在分割过程中,算法会不断地将文本分割成更小的块,直到这些块的大小满足预设的条件为止。这个过程是递归的,意味着分割操作会反复进行,每次都在更小的文本块上继续执行,直到无法再分割为止。
- 滑窗技术:在实际操作中,可能会使用所谓的“重叠滑窗”技术,即在分割时各个文本块之间会有一定程度的重叠。这有助于确保文本中的信息不会因为分割而丢失。
with open("data/test.txt") as f:
testTXT = f.read()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 20, # 块大小(每个分割文本的字符数量)
chunk_overlap = 10, # 块重叠(两个相邻块之间重叠的字符数量)
length_function = len, # 长度函数(用于计算文本长度的函数)
add_start_index = True, # 添加起始索引(是否在结果中包含分割文本的起始索引)
)
texts = text_splitter.create_documents([testTXT])
print(texts[0])
print(texts[1])
page_content='Madam Speaker, Madam' metadata={'start_index': 0}
page_content='Madam Vice' metadata={'start_index': 15}
print(texts)
[Document(page_content='Madam Speaker, Madam', metadata={'start_index': 0}), Document(page_content='Madam Vice', metadata={'start_index': 15}), Document(page_content='Vice President,our', metadata={'start_index': 21}), Document(page_content='First Lady and', metadata={'start_index': 40}), Document(page_content='Lady and Second', metadata={'start_index': 46}), Document(page_content='Second Gentleman.', metadata={'start_index': 55}), Document(page_content='Members of Congress', metadata={'start_index': 74}), Document(page_content='Congress and the', metadata={'start_index': 85}), Document(page_content='and the Cabinet.', metadata={'start_index': 94}), Document(page_content='Justices of the', metadata={'start_index': 112}), Document(page_content='of the Supreme', metadata={'start_index': 121}), Document(page_content='Supreme Court. My', metadata={'start_index': 128}), Document(page_content='Court. My fellow', metadata={'start_index': 136}), Document(page_content='fellow Americans.', metadata={'start_index': 146}), Document(page_content='Last year COVID-19', metadata={'start_index': 165}), Document(page_content='COVID-19 kept us', metadata={'start_index': 175}), Document(page_content='kept us apart. This', metadata={'start_index': 184}), Document(page_content='This year we are', metadata={'start_index': 199}), Document(page_content='we are finally', metadata={'start_index': 209}), Document(page_content='finally together', metadata={'start_index': 216}), Document(page_content='together again.', metadata={'start_index': 224})]3.代码分割(Split code)
CodeTextSplitter 允许使用支持的多种语言拆分代码。下面使用PythonTextSplitter拆分python代码;另外还支持JS text splitter、TS text splitter、Markdown text splitter等
from langchain.text_splitter import Language
# 支持编程语言的完整列表
[e.value for e in Language]
python_text = """
def print_multiplication_table():
for i in range(1, 10):
for j in range(1, i+1):
print(f'{j} * {i} = {i*j}\t', end='')
print()
print_multiplication_table()
"""
#%%
python_splitter = RecursiveCharacterTextSplitter.from_language(
language=Language.PYTHON, chunk_size=60, chunk_overlap=0
)
python_docs = python_splitter.create_documents([python_text])
python_docs
#输出
[Document(page_content='def print_multiplication_table():'),
Document(page_content='for i in range(1, 10):\n for j in range(1, i+1):'),
Document(page_content="print(f'{j} * {i} = {i*j}\t', end='')"),
Document(page_content='print()'),
Document(page_content='print_multiplication_table()')]四、文本嵌入模型(Text embedding models)
检索的另一个关键部分是为文档创建嵌入。嵌入捕获文本的语义,使您能够快速有效地找到文本的其他相似部分。 LangChain 提供了大量的不同嵌入方法的集成。
from langchain_openai import OpenAIEmbeddings
embeddings_model = OpenAIEmbeddings()
# 将一组文本转换为嵌入向量,并将结果存储在embeddings变量中
embeddings = embeddings_model.embed_documents(
[
"Hi there!",
"Oh, hello!",
"What's your name?",
"My friends call me World",
"Hello World!"
]
)
len(embeddings), len(embeddings[0])
#输出:
(5, 1536)使用embed_query方法将查询文本转换为嵌入向量
# 使用embed_query方法将查询文本转换为嵌入向量,并将结果存储在embedded_query变量中
embedded_query = embeddings_model.embed_query("What was the name mentioned in the conversation?")
embedded_query[:5]
#输出:
[0.005384807424727807,
-0.0005522561790177147,
0.03896066510130955,
-0.002939867294003909,
-0.008987877434176603]五、向量存储(Vector stores)
针对文本数据嵌入化后,需要数据库来支持这些嵌入的高效存储和搜索, LangChain 提供多种不同矢量存储的集成。
from langchain.document_loaders import TextLoader
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma
# 加载长文本
raw_documents = TextLoader('消失的她.txt', encoding="utf-8").load()
# 实例化文本分割器
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
#%%
# 分割文本
documents = text_splitter.split_documents(raw_documents)
#%%
# 将分割后的文本,使用 OpenAI 嵌入模型获取嵌入向量,并存储在 Chroma 中
db = Chroma.from_documents(documents, OpenAIEmbeddings())
#%%
query = "消失的她这部电影的角色有哪些?"
docs = db.similarity_search(query)
print(docs[0].page_content)
#输出结果
《消失的她》是一部充满悬疑和心理刺激的电影,讲述了丈夫何非的妻子李木子在结婚周年旅行中神秘失踪的故事。随后,出现了一个陌生女人冒充李木子,引发了一系列扑朔迷离的事件。以下是对该电影的详细解读:六、常用检索器(Retrievers)
在数据进行向量化存储后,LangChain支持多种不同的检索算法,方便用户从向量数据库中检索出来。
1.多查询检索器MultiQueryRetriever
通过使用 LLM 从不同角度将用户给定的输入查询生成多个查询。对于每个查询,它都会检索一组相关文档,并采用所有查询之间的唯一并集来获取更大的一组潜在相关文档。

代码样例如下:
# Build a sample vectorDB
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
# Load blog post
loader = WebBaseLoader("https://lilianweng.github.io/posts/2023-06-23-agent/")
data = loader.load()
# Split
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
splits = text_splitter.split_documents(data)
# VectorDB
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(documents=splits, embedding=embedding)
from langchain.retrievers.multi_query import MultiQueryRetriever
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(temperature=0)
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm=llm
)
question = "What are the approaches to Task Decomposition?"
unique_docs = retriever_from_llm.get_relevant_documents(query=question)
unique_docs
#打印详情,可查看LLM处理后的多个查询条件,以及返回结果
INFO:langchain.retrievers.multi_query:Generated queries: ['1. How can Task Decomposition be achieved through different methods?', '2. What strategies are commonly used for breaking down tasks into smaller components?', '3. What are the various techniques employed for Task Decomposition in practice?']
[Document(page_content='Task decomposition can be done (1) by LLM with simple prompting like "Steps for XYZ.\\n1.", "What are the subgoals for achieving XYZ?", (2) by using task-specific instructions; e.g. "Write a story outline." for writing a novel, or (3) with human inputs.', metadata={'description': 'Building agents with LLM (large language model) as its core controller is a cool concept. Several proof-of-concepts demos, such as AutoGPT, GPT-Engineer and BabyAGI, serve as inspiring examples. The potentiality of LLM extends beyond generating well-written copies, stories, essays and programs; it can be framed as a powerful general problem solver.\nAgent System Overview In a LLM-powered autonomous agent system, LLM functions as the agent’s brain, complemented by several key components:', 'language': 'en', 'source': 'https://lilianweng.github.io/posts/2023-06-23-agent/', 'title': "LLM Powered Autonomous Agents | Lil'Log"}),2.自查询检索器(Self Query Retriever)
Self Query Retriever采用自我提问的方式,不断的细化搜索的问题;它会根据初次检索的结果来优化后续的查询,这样不断迭代,直到找到最相关的信息。这种方法适用于那些需要连续查询和反馈的场景。
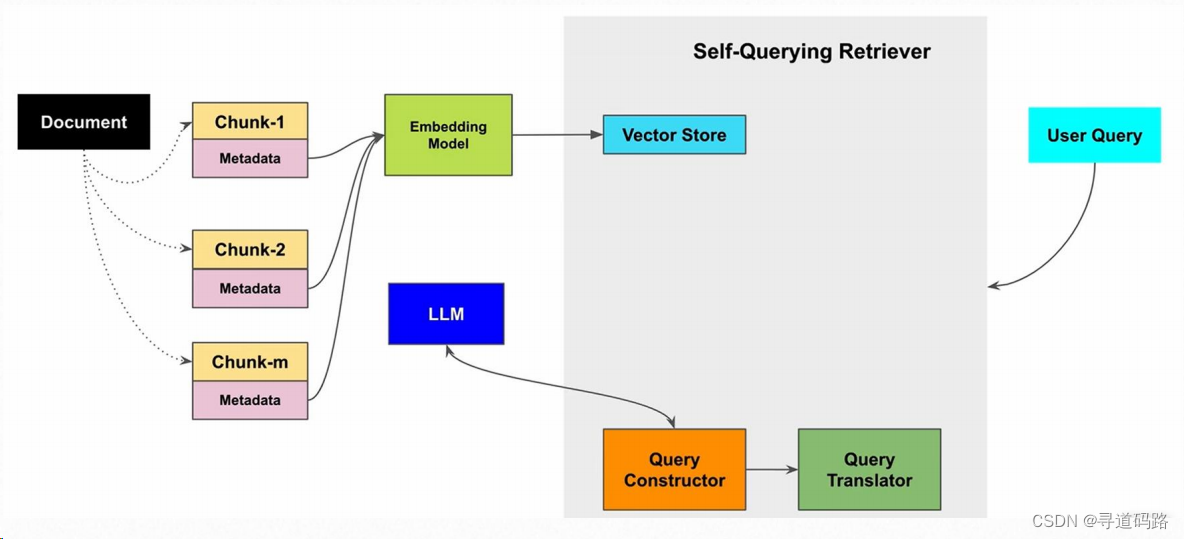
将一个大文档,拆分成多个块和元数据信息,向量化存储;用户查询时,先通过LLM转换成结构化查询,再将结构化查询转为向量化查询,从向量数据库查询到结果。
代码样例如下:
# 安装依赖 pip install --upgrade lark chromadb
from langchain_community.vectorstores import Chroma
from langchain_core.documents import Document
from langchain_openai import OpenAIEmbeddings
docs = [
Document(
page_content="A bunch of scientists bring back dinosaurs and mayhem breaks loose",
metadata={"year": 1993, "rating": 7.7, "genre": "science fiction"},
),
Document(
page_content="Leo DiCaprio gets lost in a dream within a dream within a dream within a ...",
metadata={"year": 2010, "director": "Christopher Nolan", "rating": 8.2},
),
Document(
page_content="A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea",
metadata={"year": 2006, "director": "Satoshi Kon", "rating": 8.6},
),
Document(
page_content="A bunch of normal-sized women are supremely wholesome and some men pine after them",
metadata={"year": 2019, "director": "Greta Gerwig", "rating": 8.3},
),
Document(
page_content="Toys come alive and have a blast doing so",
metadata={"year": 1995, "genre": "animated"},
),
Document(
page_content="Three men walk into the Zone, three men walk out of the Zone",
metadata={
"year": 1979,"director": "Andrei Tarkovsky","genre": "thriller","rating": 9.9},
),
]
vectorstore = Chroma.from_documents(docs, OpenAIEmbeddings())
from langchain.chains.query_constructor.base import AttributeInfo
from langchain.retrievers.self_query.base import SelfQueryRetriever
from langchain_openai import ChatOpenAI
metadata_field_info = [
AttributeInfo(
name="genre",
description="The genre of the movie. One of ['science fiction', 'comedy', 'drama', 'thriller', 'romance', 'action', 'animated']",
type="string",
),
AttributeInfo(
name="year",
description="The year the movie was released",
type="integer",
),
AttributeInfo(
name="director",
description="The name of the movie director",
type="string",
),
AttributeInfo(
name="rating", description="A 1-10 rating for the movie", type="float"
),
]
document_content_description = "Brief summary of a movie"
llm = ChatOpenAI(temperature=0)
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
)
调用检索器,查看8.5分以上的电影
retriever.invoke("I want to watch a movie rated higher than 8.5")
#输出
[Document(page_content='Three men walk into the Zone, three men walk out of the Zone', metadata={'director': 'Andrei Tarkovsky', 'genre': 'thriller', 'rating': 9.9, 'year': 1979}),
Document(page_content='A psychologist / detective gets lost in a series of dreams within dreams within dreams and Inception reused the idea', metadata={'director': 'Satoshi Kon', 'rating': 8.6, 'year': 2006})]
调用检索器查看Greta Gerwig导演的女性电影
retriever.invoke("Has Greta Gerwig directed any movies about women")
#输出
[Document(page_content='A bunch of normal-sized women are supremely wholesome and some men pine after them', metadata={'director': 'Greta Gerwig', 'rating': 8.3, 'year': 2019})]使用自查询检索器来指定 k:要获取的文档数
retriever = SelfQueryRetriever.from_llm(
llm,
vectorstore,
document_content_description,
metadata_field_info,
enable_limit=True,
)
# This example only specifies a relevant query
retriever.invoke("What are two movies about dinosaurs")
# 输出
[Document(page_content='A bunch of scientists bring back dinosaurs and mayhem breaks loose', metadata={'genre': 'science fiction', 'rating': 7.7, 'year': 1993}),
Document(page_content='Toys come alive and have a blast doing so', metadata={'genre': 'animated', 'year': 1995})]3.集成检索器(Ensemble Retriever)
Ensemble Retriever结合了多种检索方法,比如BM25Retriever和FAISS,来提高检索的准确性。它通过综合不同检索器的结果来提供一个更加全面和准确的答案。这种“集思广益”的方法可以弥补单一检索方法可能存在的不足。

代码样例如下:
from langchain.retrievers import BM25Retriever, EnsembleRetriever
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
#%%
doc_list = [
"I like apples",
"I like oranges",
"Apples and oranges are fruits",
]
# initialize the bm25 retriever and faiss retriever
## 稀松检索器
bm25_retriever = BM25Retriever.from_texts(doc_list)
bm25_retriever.k = 2
## 密集检索器
embedding = OpenAIEmbeddings()
faiss_vectorstore = FAISS.from_texts(doc_list, embedding)
faiss_retriever = faiss_vectorstore.as_retriever(search_kwargs={"k": 2})
# initialize the ensemble retriever
ensemble_retriever = EnsembleRetriever(
retrievers=[bm25_retriever, faiss_retriever], weights=[0.5, 0.5]
)
#%%
## 获取数据
docs = ensemble_retriever.get_relevant_documents("apples")
docs
#输出:
[Document(page_content='I like apples'),
Document(page_content='Apples and oranges are fruits')]总结
LangChain框架的Retrieval模块为AI大模型探索之路提供了高效的信息提取与管理。通过一系列的组件,如文档加载器、文档转换器、文本嵌入模型、向量存储和检索器,实现了数据的加载、转换、存储和查询,大大提高了信息处理的效率和准确性。同时利用这种检索技术让AI大模型的能力得到了进一步的扩展和提高。
探索未知,分享所知;点击关注,码路同行,寻道人生!














 1679
1679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









