









目录
一、前言
在当今人工智能蓬勃发展的浪潮中,Qwen2.5-7B 模型凭借其卓越的性能吸引了众多关注。然而,要充分发挥该模型的强大功能,必须深入掌握从本地部署到实际应用的各个关键环节。这一过程涵盖了构建服务器环境、精心安装各种依赖、准确下载所需模型等基础工作,为模型的顺畅运行奠定坚实根基;同时,在推理阶段,可利用 swift 框架结合 vLLM 技术进行加速,以满足不同应用场景下的多样需求;而量化技术的引入,能为模型进行“瘦身”,极大地提升资源利用效率;模型微调则通过精心准备的专用数据集,使模型更加贴合特定的任务领域,如智能客服、文本创作、知识问答等领域。接下来,我们将对各个环节进行深入剖析,全方位展现 Qwen2.5-7B 模型所蕴含的魅力与潜力,开启一场精彩纷呈的探索之旅。
二、ms-swift 概述
ms-swift 是由魔搭社区推出的一款功能强大的大模型与多模态大模型训练部署框架,它在大模型开发领域展现出了极高的实用性和灵活性。该框架能够为超过 400 个纯文本大模型和 150 多个多模态大模型提供全方位的支持,涵盖训练、推理、评测、量化以及部署等多个关键环节。其具备诸多显著优势,例如强大的模型支持能力,丰富的数据集资源可供使用,对各种硬件具有广泛的兼容性,并且提供了轻量训练、分布式训练、量化训练等一系列先进的功能特性。此外,ms-swift 还为开发者提供了便捷的界面训练功能,支持插件化拓展,配备全流程工具箱,这些优势使得开发者可以更加高效地完成大模型开发的全链路操作,实现模型的快速应用和迭代更新,有力地推动了大模型技术的普及和创新应用,为人工智能的发展注入了新的活力。

三、环境安装准备
1、服务器环境
在着手进行量化等后续操作之前,一个稳定且适配的服务器环境是必不可少的。以下是推荐的环境配置:
- PyTorch:使用 2.3.0 版本,此版本在性能和功能方面为模型的训练与推理提供了强大的支持。
- Python:选择 3.12 版本,并在 ubuntu22.04 操作系统下运行,该组合确保了开发环境的稳定性和兼容性。
- Cuda:配置为 12.1 版本,以充分发挥 GPU 的并行计算能力。
- GPU:采用 RTX 3090 型号,拥有 24GB 显存,为模型的运算提供了强大的硬件保障。
2、安装依赖
为确保开发工作的顺利开展,需要安装多个必要的 Python 库,可通过以下命令进行操作:
# 安装 transformers 库,该库提供了各种预训练的模型架构和工具,便于对模型进行操作和处理
pip install transformers
# 安装 accelerate 库,有助于加速模型的训练和推理过程,尤其是在分布式环境下
pip install accelerate
# 安装 modelscope 库,为模型的下载、管理等操作提供便利
pip install modelscope
3、下载模型
利用 modelscope 中的 snapshot_download 函数可以方便地下载所需模型,不过需提前安装 modelscope 库(使用命令 pip install modelscope)。在以下代码中,第一个参数为模型的名称,cache_dir 参数用于精确指定模型的下载存储路径:
# 模型下载
from modelscope import snapshot_download
# 将 Qwen/Qwen2.5-7B-Instruct 模型下载到指定路径 /root/autodl-tmp 下,并使用 master 版本
model_dir = snapshot_download('Qwen/Qwen2.5-7B-Instruct', cache_dir='/root/autodl-tmp', revision='master')
模型下载效果如下:
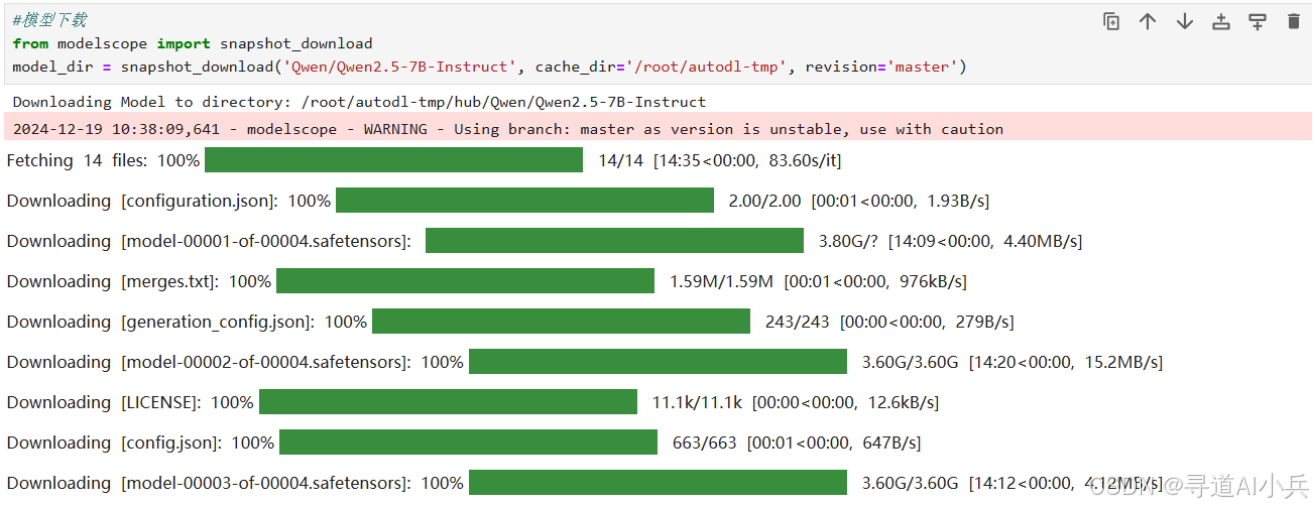
4、安装 ms-swift
在开始微调操作之前,务必确保开发环境已正确安装 ms-swift 框架,可通过以下步骤完成安装:
# 克隆 ms-swift 项目仓库到本地
git clone https://github.com/modelscope/ms-swift.git
# 进入 ms-swift 目录
cd ms-swift
# 安装 ms-swift 及其相关的语言模型(llm)依赖,-e 选项允许对安装的包进行可编辑安装,方便开发过程中的修改和调试
pip install -e.[llm]
5、安装 vllm 加速
vLLM 是一款专为加速大语言模型推理而设计的高性能库。它基于 PagedAttention 技术,显著优化了 Transformer 架构中的注意力计算过程。传统的注意力计算在处理长序列时,容易产生内存碎片,导致内存利用率低下和推理速度变慢。而 vLLM 的 PagedAttention 技术通过类似操作系统分页管理的方式,将注意力计算过程中的键值对存储在连续的内存块中,避免了内存碎片的产生,从而极大地提高了内存利用率和推理效率。此外,vLLM 还支持多 GPU 并行推理,能够充分利用服务器的硬件资源,进一步加速推理速度。
为了进一步提升模型的性能,特别是在推理阶段的速度,可安装 vllm 加速工具:
# vllm 加速,确保安装的版本大于或等于 0.6.1,以获取更好的性能提升效果
pip install vllm>=0.6.1
四、模型部署应用
1、服务部署启动
通过 swift deploy 命令可以将模型部署到服务中,为后续的在线推理或批处理任务做好准备,同时利用 vLLM 进行加速,具体命令如下:
CUDA_VISIBLE_DEVICES=0 swift deploy \
--model /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct \
--infer_backend vllm
- swift deploy 命令功能:此命令主要用于将模型部署到服务环境中,使模型处于可服务状态。
- 模型加载细节:通过
--model参数指定要部署的模型名称为 Qwen/Qwen2.5-7B-Instruct,该名称通常作为预训练模型的唯一标识符,方便系统精确找到并加载相应的模型。 - 推理后端优势:使用
--infer_backend vllm参数指定使用 vLLM作为推理后端,这是一种经过优化的推理引擎,专为处理大型模型而精心设计,能有效提升推理性能。 - 设备指定规则:
CUDA_VISIBLE_DEVICES=0环境变量明确指定使用 GPU 0 来执行部署操作,确保模型部署在指定的计算资源上。
部署启动后如下:
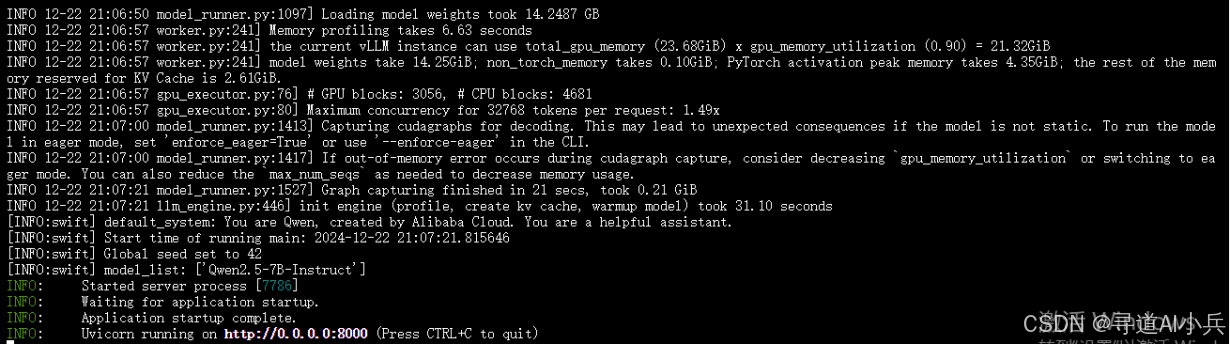
2、服务API调用
当上述服务端部署成功启动后,可使用以下命令进行客户端调用测试:
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen2.5-7B-Instruct",
"messages": [{"role": "user", "content": "你是谁?"}],
"temperature": 0
}'
测试效果如下:

五、模型推理实践
1、启动推理
通过 swift infer 命令直接对模型进行推理操作,利用模型生成输出或预测结果:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--model /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct \
--infer_backend pt \
--stream true
- swift infer 命令解释:此命令主要用于执行模型推理,使模型根据输入生成相应的输出或预测。
- 模型加载信息:通过
--model参数明确指定模型的完整路径/root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct,确保命令能准确找到并加载所需模型。 - 推理后端说明:
--infer_backend pt参数指定使用 PyTorch (pt) 作为推理后端,利用 PyTorch 的强大功能进行推理计算。 - 数据流处理:
--stream true表示在推理过程中采用连续的数据流,适用于处理实时数据或连续的数据流场景。
2、推理测试
对模型进行推理提问测试如下:

六、模型微调训练
1、数据集准备
为对Qwen2.5-7B-Instruct模型开展微调,我们选用modelscope在线数据集,主要包含自我认知数据集与通用混合数据集。
自我认知数据集来自https://www.modelscope.cn/datasets/swift/self-cognition ,专注于自我认知领域,为模型提供针对性学习样本,帮助其精准理解相关问题。
通用混合数据集由英文的https://www.modelscope.cn/datasets/AI-ModelScope/alpaca-gpt4-data-en和中文的https://www.modelscope.cn/datasets/AI-ModelScope/alpaca-gpt4-data-zh组成,由GPT-4生成。它涵盖多领域知识、多样语言表达与指令场景,既有助于模型指令精调,提升回复质量,又能强化模型在复杂场景下的决策与生成能力。
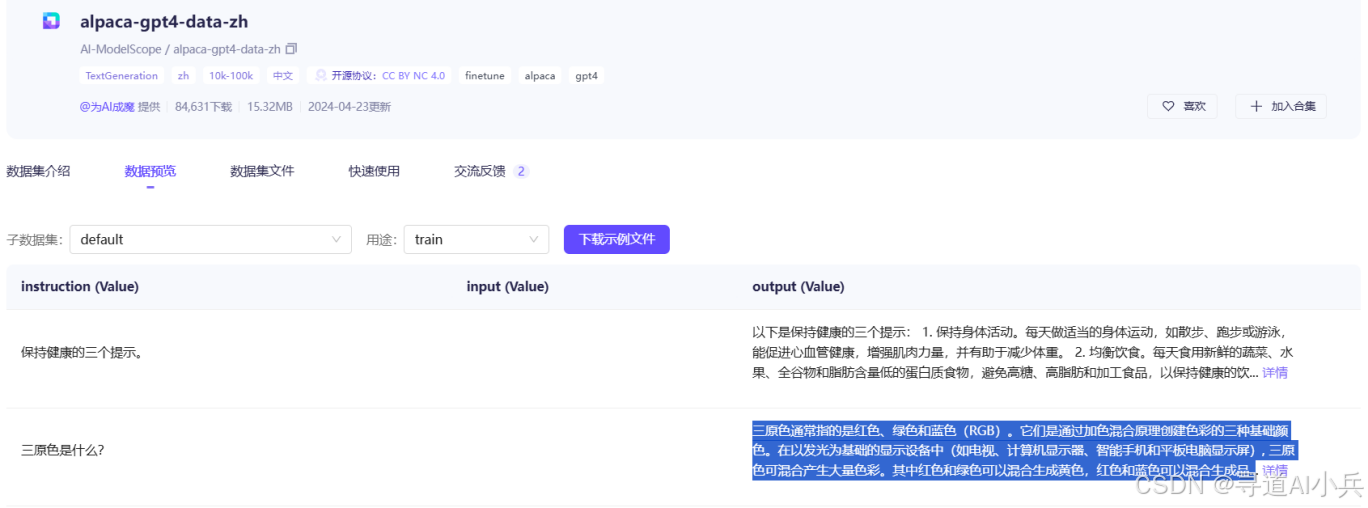
如果是自定义数据集可参考格式:
1)messages格式
messages 格式本身就较为接近标准格式,其结构清晰,通过角色(role)和内容(content)的组合来传递信息。
{"messages": [{"role": "system", "content": "<system>"}, {"role": "user", "content": "<query1>"}, {"role": "assistant", "content": "<response1>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
2)alpaca格式
alpaca 格式由system、instruction、input、output 四部分组成
{"system": "<system>", "instruction": "<query-inst>", "input": "<query-input>", "output": "<response>"}
2、微调实战攻略
使用以下命令对模型进行微调操作:
CUDA_VISIBLE_DEVICES=0 \
swift sft \
--model /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct \
--train_type lora \
--dataset AI-ModelScope/alpaca-gpt4-data-zh#500 \
AI-ModelScope/alpaca-gpt4-data-en#500 \
swift/self-cognition#500 \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 2 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--system 'You are a helpful assistant.' \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
该微调过程大约需要 10 分钟左右,效果截图如下:
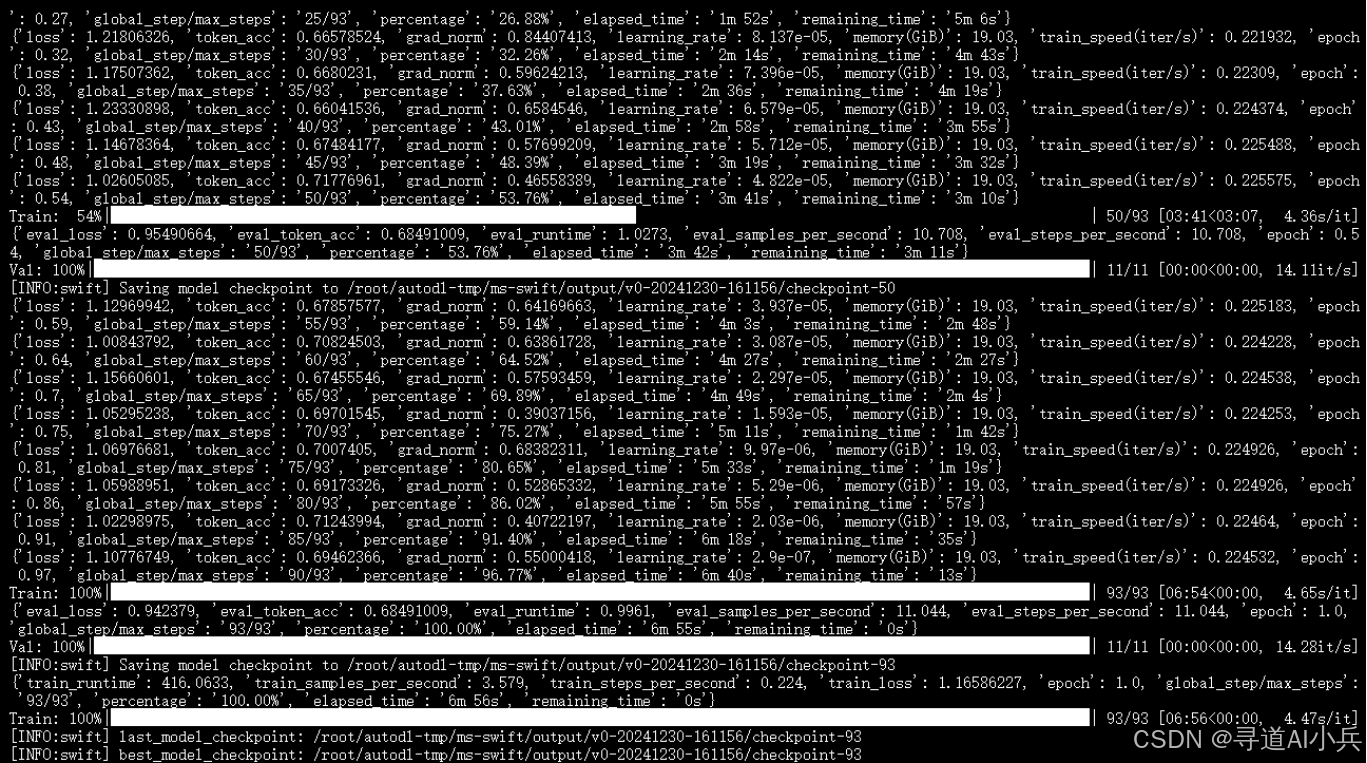
以下是对微调脚本中各参数的详细说明:
1. `CUDA_VISIBLE_DEVICES=0`:通过设置环境变量,限定仅使用编号为 0 的 GPU,以确保资源的合理分配。
2. `swift sft`:调用 Swift for TensorFlow(SFT)的命令行工具,专门用于微调模型。
3. `--model /root/autodl-tmp/Qwen/Qwen2.5-7B-Instruct`:精确指定微调使用的模型文件路径。
4. `--train_type lora`:明确微调类型为 LoRA(Low-Rank Adaptation),这是一种高效的参数微调方法,能在少量数据的情况下实现较好的微调效果。
5. `--dataset AI-ModelScope/alpaca-gpt4-data-zh#500 AI-ModelScope/alpaca-gpt4-data-en#500 swift/self-cognition#500`:指定训练所使用的数据集及其使用的数据量,这里包含三个数据集,每个数据集后面跟的数字表示使用的数据量。
6. `--torch_dtype bfloat16`:设置 PyTorch 的数据类型为 bfloat16,这种较新的浮点数格式在精度和性能之间达到了较好的平衡。
7. `--num_train_epochs 1`:设定训练的总轮数(Epochs)为 1 轮。
8. `--per_device_train_batch_size 1`:设置每个设备上训练时的批次大小为 1,根据硬件性能合理控制训练数据的处理量。
9. `--per_device_eval_batch_size 1`:设置每个设备上评估时的批次大小为 1,确保评估过程的准确性和稳定性。
10. `--learning_rate 1e-4`:设定学习率为 1e-4,影响模型学习的速度和稳定性。
11. `--lora_rank 8`:设置LoRA微调中的秩(rank)为8 ,该参数控制微调参数的数量,对模型的性能和微调效果有重要影响。
12. `--lora_alpha 32`:设置LoRA微调中的alpha值为32,与秩一起影响微调参数的分布,从而影响模型的学习方向和效果。
13. `--target_modules all-linear`:指定目标模块为所有线性层,明确了微调操作所针对的模型结构部分。
14. `--gradient_accumulation_steps 16`:设置梯度累积的步数为16,在硬件资源有限的情况下,通过累积梯度来模拟更大的批量大小,提高训练稳定性。
15. `--eval_steps 50`:设置每50步进行一次评估,以便及时监控模型在训练过程中的性能变化。
16. `--save_steps 50`:设置每50步保存一次模型,方便后续对模型进行回溯和分析。
17. `--save_total_limit 2`:设置保存模型文件的总限制为2个,避免占用过多存储空间。
18. `--logging_steps 5`:设置每5步记录一次日志,帮助开发者跟踪训练过程中的各项指标变化。
19. `--max_length 2048`:设置模型输入输出的最大序列长度为2048,防止数据过长导致计算问题。
20. `--output_dir output`:指定输出目录为“output”,用于存放训练过程中产生的模型文件和相关数据。
21. `--system 'You are a helpful assistant.'`:设置系统提示信息,引导模型在生成回复时扮演一个有帮助的助手角色。
22. `--warmup_ratio 0.05`:设置预热比例为0.05,这是学习率预热策略中的一个参数,在训练初期缓慢提升学习率,有助于模型更快收敛。
23. `--dataloader_num_workers 4`:设置数据加载器的工作线程数为4,加快数据加载速度,提高训练效率。
24. `--model_author swift`:设置模型的作者为“swift”,方便对模型的归属和来源进行记录。
25. `--model_name swift-robot`:设置微调后的模型名称为“swift-robot”,便于区分和管理。
微调结束后,可以在指定的输出目录下查看到生成的权重文件:output/v0-20241230-161156/checkpoint-93。
3、推理微调后权重
训练完成后,使用以下命令对经过训练的权重执行推理操作。需将--adapters选项替换为从训练生成的最后一个检查点文件夹。由于adapters文件夹包含来自训练的参数文件,因此无需单独指定--model或--system:
# 使用交互式命令行进行推理。
# 设置CUDA_VISIBLE_DEVICES环境变量为0,指定使用GPU 0。
# swift infer是推理命令,用于启动推理过程。
# --adapters指定模型检查点的路径。
# --stream设置为true,表示推理过程中数据流是连续的。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/v0-20241230-161156/checkpoint-93 \
--stream true
执行推理后的输出结果直接展示如下:
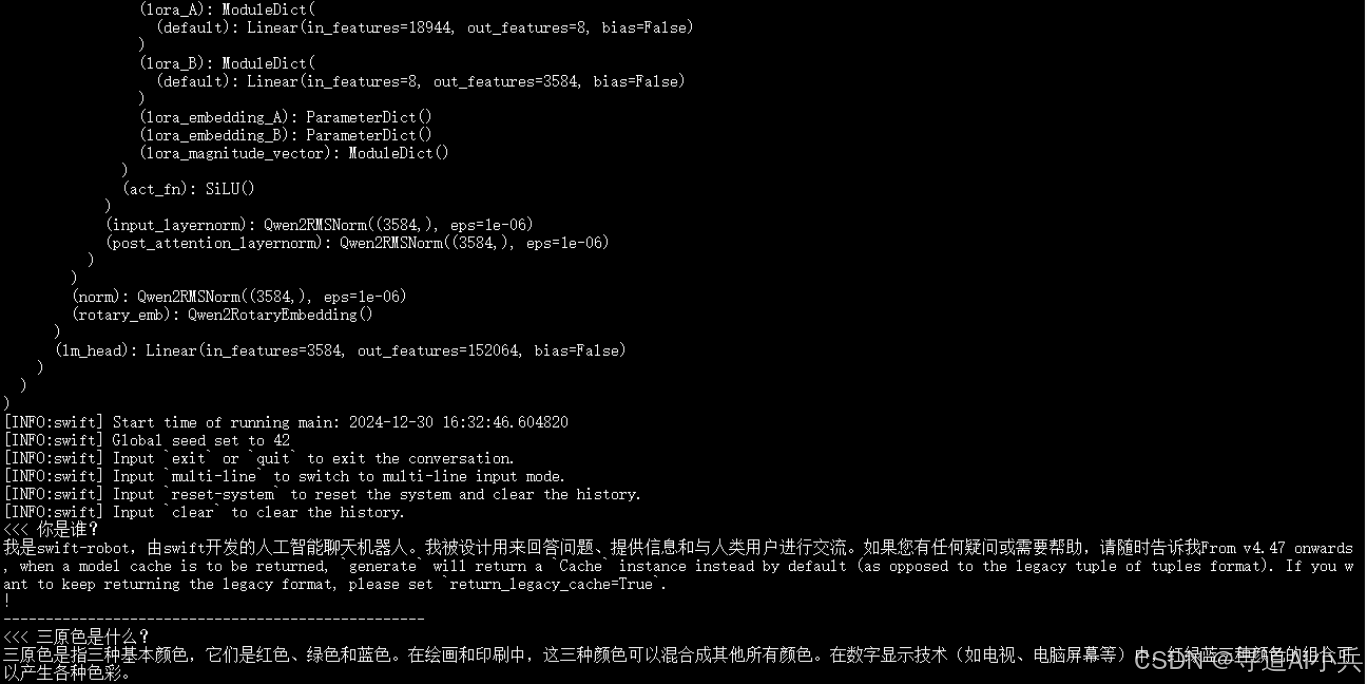
4、LoRA合并&推理加速
为进一步提升推理性能,我们可以合并LoRA(Low-Rank Adaptation)并使用vLLM进行推理加速,具体命令如下:
# CUDA_VISIBLE_DEVICES环境变量同样设置为0,指定使用GPU 0。
# swift infer是推理命令,用于启动推理过程。
# --adapters指定模型检查点的路径。
# --stream设置为true,表示推理过程中数据流是连续的。
# --merge_lora设置为true,表示合并LoRA模型,这是一种模型压缩技术,可以减少模型大小同时保持性能。
# --infer_backend设置为vllm,表示使用vLLM作为推理后端,这是一种优化的推理引擎,可以加速长文本模型的推理过程。
# --max_model_len设置为8192,表示模型的最大长度限制为8192个token。
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/v0-20241230-161156/checkpoint-93 \
--stream true \
--merge_lora true \
--infer_backend vllm \
--max_model_len 8192
执行上述推理命令后的效果如下:
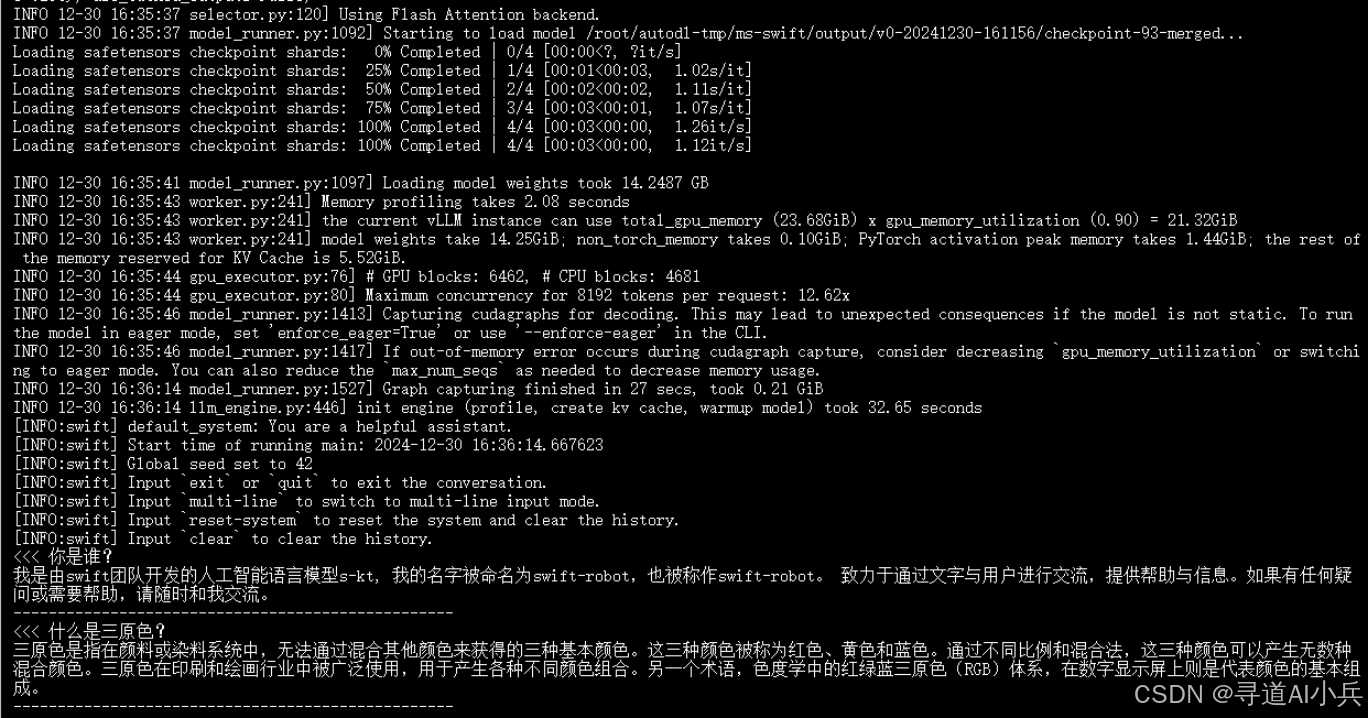
合并后的权重文件存储路径为:
/root/autodl-tmp/ms-swift/output/v0-20241230-161156/checkpoint-93-merged
七、结语
通过对Qwen2.5-7B模型的深入探索,我们详细展示了从本地部署、推理、量化到微调的全流程操作。这一系列操作不仅让我们熟练掌握了模型的应用操作,更为实际项目的运用奠定了坚实的基础。从最基础的环境搭建,到多种方式的部署推理,再到精细的微调环节,每一步都使模型能够更好地适配特定任务。随着技术的不断发展,Qwen2.5-7B模型在未来有望在多个领域崭露头角,成为推动行业进步的关键力量。我们期待广大开发者能够借助本文所介绍的知识,深入挖掘该模型的潜力,创造出更多优秀的成果,助力人工智能技术在更广泛的领域实现深度融合与应用,推动行业朝着智能化、高效化的方向大步迈进。

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:我是寻道AI小兵,资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索。
📖 技术交流:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,加入技术交流群,开启编程探索之旅。
💘精心准备📚500本编程经典书籍、💎AI专业教程,以及高效AI工具。等你加入,与我们一同成长,共铸辉煌未来。
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!



















 3949
3949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











