







开这个专题的想法是最近想要学习系统设计,想把自己每次学到的东西整理下来,同时也能帮助大家更好的理解我学的东西。
其实系统设计这个东西个人感觉国内的面试中不经常考,但是个人感觉用处还是很大的,相比于八股文,其更有实际价值,因此在北美的面试中经常会考到(即使是new grad),anyway,本着不是特别功利的思想,自己想要学这门课程,长远看来应该很有益。
Learning how to design scalable systems will help you become a better engineer.
其实系统设计的精髓应该就是寻找trade off的过程
随便举个例子,以CAP原理为例:
Consistency - Every read receives the most recent write or an error
Availability - Every request receives a response, without guarantee that it contains the most recent version of the information
Partition Tolerance - The system continues to operate despite arbitrary partitioning due to network failures
网络不可能同时满足这三个条件,因此你需要在consistency 和 availability中找到一个trade off
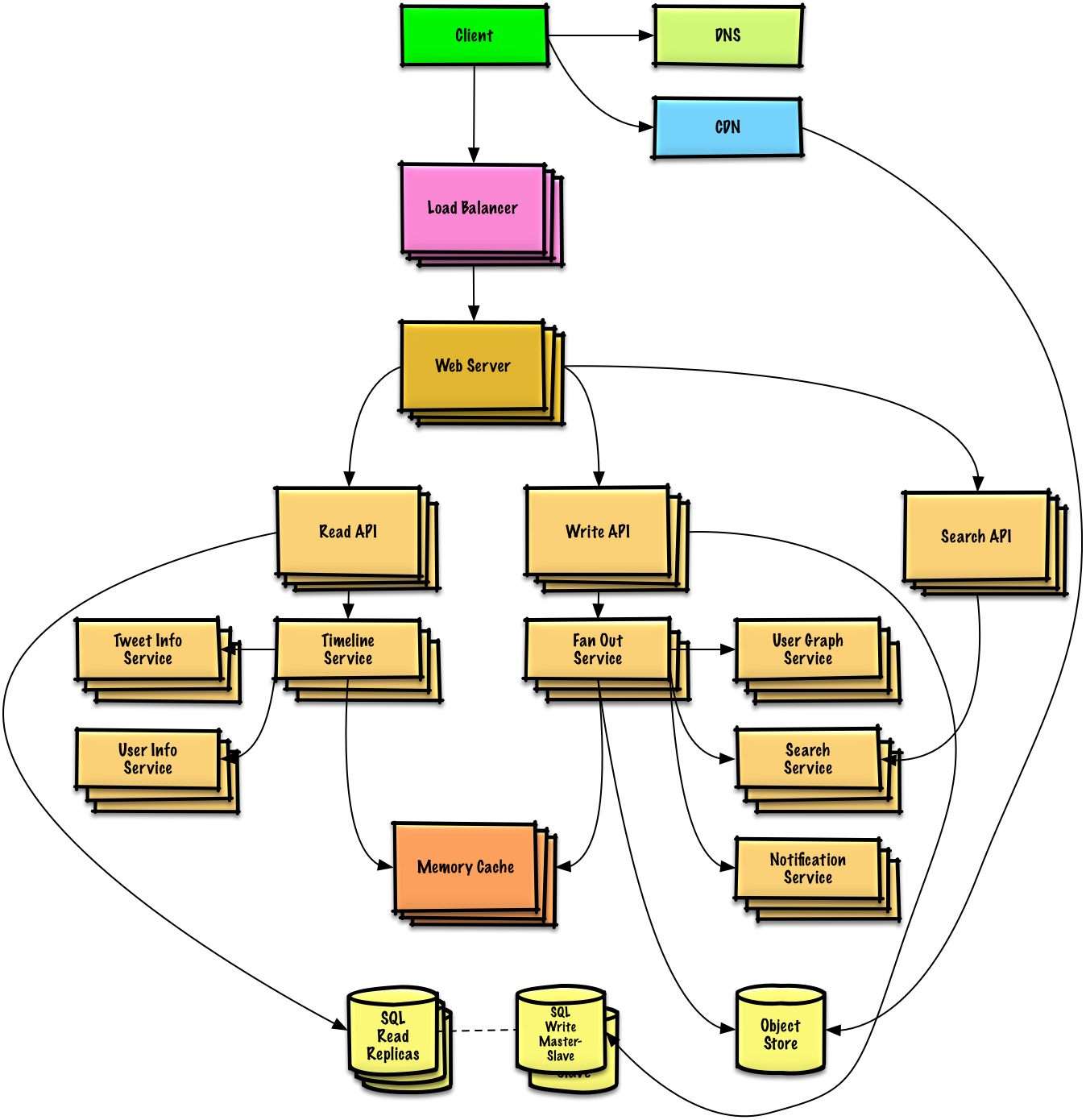
下面一个链接能帮助你
scalability
Design Pastebin.com (or Bit.ly)
先看一下题目要求
We’ll scope the problem to handle only the following use cases:
User enters a block of text and gets a randomly generated link Expiration
Default setting does not expire
Can optionally set a timed expiration
User enters a paste’s url and views the contents
User is anonymous
Service tracks analytics of pages Monthly visit stats
Service deletes expired pastes Service has high availability
Out of scope User:
registers for an account
User verifies email
User logs into a registered account
User edits the document
User can set visibility
User can set the shortlink
Constraints and assumptions:
State assumptions
Traffic is not evenly distributed
Following a short link should be fast
Pastes are text only
Page view analytics do not need to be realtime 10 million
users 10 million paste writes per month 100
million paste reads per month 10:1 read to write ratio
得到题目后通过计算可以得出:
1 KB content per paste
shortlink - 7 bytes
expiration_length_in_minutes - 4 bytes
created_at - 5 bytes
paste_path - 255 bytes
total = ~1.27 KB
也就是说每一条数据大概要消耗1.27KB的资源
so
每个月大概要消耗12.7GB
还能计算得出每秒大概要执行四次写操作,四十次读操作
得到了这些基本信息之后我们就可以用于系统设计啦!
画出需要的outline
接下来就要开始正式的设计了:
先看第一个case:User enters a block of text and gets a randomly generated link Expiration
因此应该有一个关系型数据库作为哈希表的用途去进行存储url到文件的一个映射,但是除此之外NoSQL也可以充当哈希表,关于是用关系型还是非关系型数据库,我觉得还是要找到一个trade off,下面的讨论都是基于关系型数据库:
client发送创建请求到web server,运行反向代理
web server请求write api server
write api server做了下列操作:
1.生成一个url(检查url是否存在在hash表里,如果存在,重新生成一个,否则,存储,如果支持用户创建url的话,也可以不生成url转而使用用户的url,当然也需要验重)
2.保存SQL数据库
3.保存到Object Store
4.返回这个url
首先要定义数据库的表结构
shortlink char(7) NOT NULL//url
expiration_length_in_minutes int NOT NULL//过期时间
created_at datetime NOT NULL//创建时间
paste_path varchar(255) NOT NULL//路径,也就是哈希表 的value
PRIMARY KEY(shortlink)
将主键设置为shortlink回创建一个索引,数据库使用这个索引来强制唯一性,除此之外还可以在create_at字段上创建一个附加索引来加快查找速度,并且将这些数据保存在内存中来加快查找速度
为了生成url,可以使用ip+时间戳在进行哈希,再用Base 62进行编码,取前7位作为输出,62^7大概能够映射36亿的关系
url = base_encode(md5(ip_address+timestamp))[:URL_LENGTH]
使用一个公共的REST API
$ curl -X POST --data '{ "expiration_length_in_minutes": "60", \
"paste_contents": "Hello World!" }' https://pastebin.com/api/v1/paste
返回体
{
"shortlink": "foobar"
}
Use case: User enters a paste’s url and views the contents
client发送请求到web server
web server调用read api
read api做下列操作:
检查sql的url,如果url在关系型数据库里,则找到value,否则,返回报错
Use case: Service tracks analytics of pages
因为并不需要实时分析,因此我们可以简单的使用MapReduce来进行统计
class HitCounts(MRJob):
def extract_url(self, line):
"""Extract the generated url from the log line."""
...
def extract_year_month(self, line):
"""Return the year and month portions of the timestamp."""
...
def mapper(self, _, line):
"""Parse each log line, extract and transform relevant lines.
Emit key value pairs of the form:
(2016-01, url0), 1
(2016-01, url0), 1
(2016-01, url1), 1
"""
url = self.extract_url(line)
period = self.extract_year_month(line)
yield (period, url), 1
def reducer(self, key, values):
"""Sum values for each key.
(2016-01, url0), 2
(2016-01, url1), 1
"""
yield key, sum(values)
Use case: Service deletes expired pastes
如果想要删除过期数据的话,需要定期扫描整个数据库,查找过期的时间戳,然后删除(后者标注为过期)
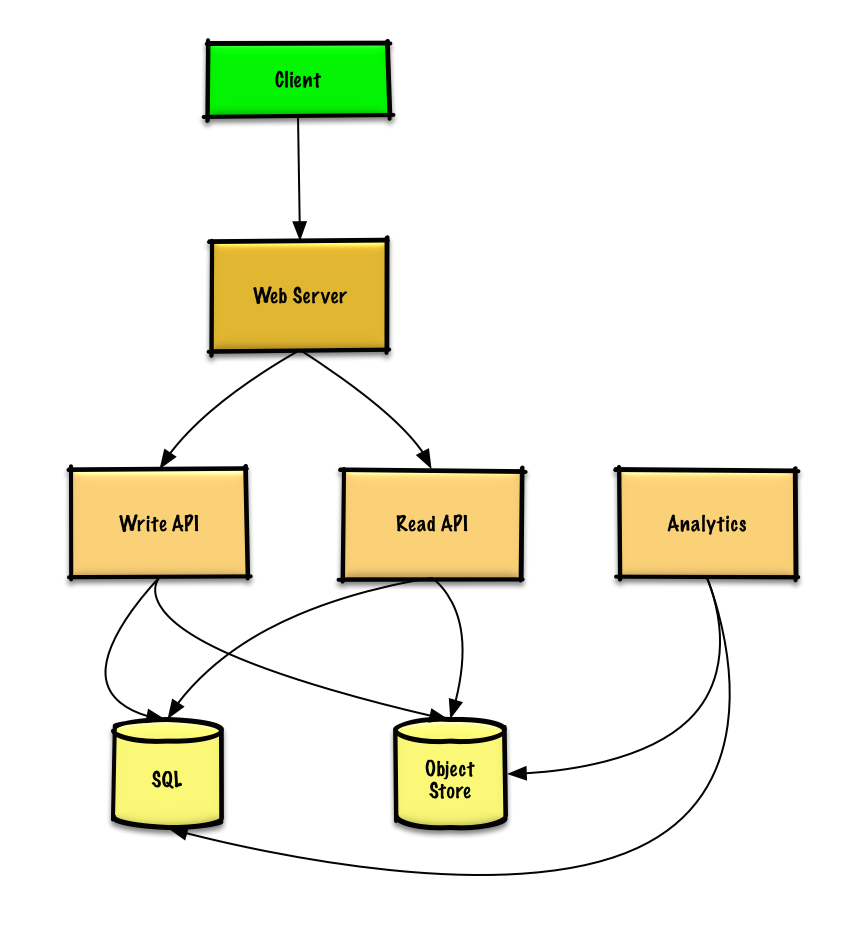
上面是该系统的基本实现
然后就要考虑可扩展性了
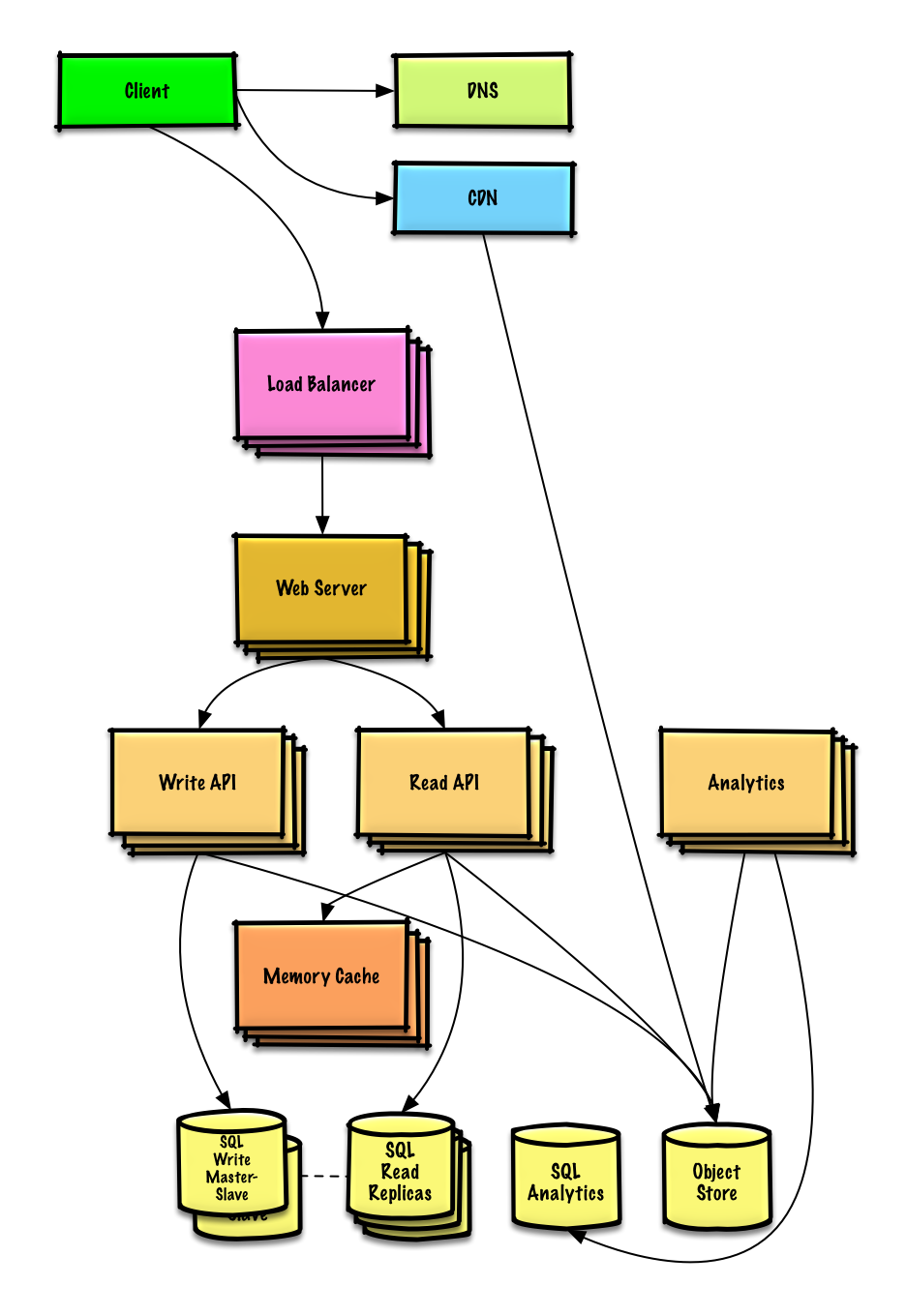
关于可扩展性的问题,我觉得每个人应该都有他自己的看法,但是非常重要的一点是应该不停的重复测试,查找瓶颈,找到解决瓶颈的方法这三个步骤
讨论瓶颈问题是非常重要的,比如添加多个服务器的负载均衡可以解决哪些问题?CDN?主从副本?怎么在这些之间找到trade off呢?这些东西都没有标准答案

















 382
382











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











