







Abatract
我们提出一种新的实时对象检测方法,利用深层神经网络的精度和级联分类器的效率。深层网络已被证明在分类任务方面表现优异,而且无需设计特殊的特征,他们在原始像素输入上的操作能力是非常有吸引力。然而,在inference时间,深层网络的声誉是非常低的。
在本文中,我们提出了一种将深度网络和快速特征级联的方法,既快速又准确。我们将其应用于具有挑战性的行人检测任务。我们的算法以每秒15帧的速度实时运行。所得到的方法在Caltech行人检测基准上达到26.2%的平均失误率,这与最佳报告结果具有竞争力。这是我们所知的第一个工作,在实时运行时实现了非常高的精度。
1 Introduction
鉴于它与机器人技术中的许多应用相关,包括驾驶辅助系统[8],道路场景理解[16]或监控系统,行人检测已经是数十年来的重要问题。实现这种系统的两个主要实际要求是非常高的精确度和实时速度:我们需要足够准确的行人检测器,并且足够快速的运行在有限计算能力的系统上。本文通过在非常有效的级联分类器框架中组合非常精确的基于深度学习的分类器来满足这两个要求[38]。行人检测方法采用了各种技术和特征[4,5,11,12,33,38,39,42]。有些则关注于提高检测速度[4,5,68],而其他则关注于精度[25,31,42]。最近,基于深层神经网络,出现了一系列新颖的方法,显示出令人印象深刻的精度增益[24]。
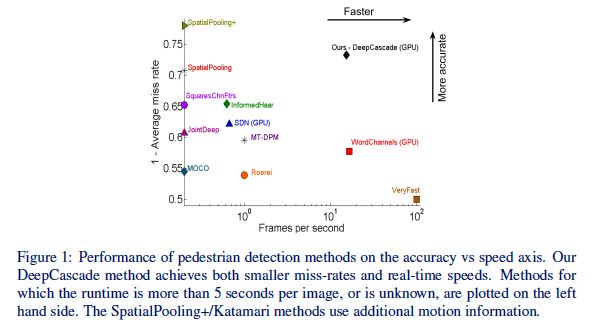
然而,深层神经网络(DNN)模型是非常慢的[19,21,23],特别是用作滑动窗口分类器时。我们提出一种非常有竞争力的DNN方法,用于行人检测,非常准确,并且可以实时运行。为了实现这一点,我们将快速级联[4]与级联的DNN相结合[24]。与现有的方法相比,我们的方法非常准确,速度非常快,在GPU上每个图像67毫秒,每秒15帧(FPS)。据我们所知,不存在实现非常高精度和实时性能的竞争方法。图1可视化现有的方法,在精确度 - 计算时间轴上绘制,在具有挑战性的Caltech行人检测基准上评估[12]。从图中可以看出,我们的方法是驻留在高精度,高速度空间区域中的唯一方法,使其对实际应用特别有吸引力。
我们不是第一个考虑在级联中使用DNN的方法。欧阳等和罗等 [25,29]都将深层网络与快速特征级联相结合。这些方法在概念上类似于我们的方法,但是不能捕获级联的全部加速效益,处理时间对于实时性能来说太慢,例如GPU上的每个图像为1-1.5秒[25]。相反,我们在这里利用了非常快的消除特征,VeryFast [4]以及小型和大型深层网络[3,24]。我们提出的方法是独一无二的,因为它是第一个以实时速度(15 FPS)生成行人检测器,同时也非常准确。 与以前的DNN研究一致,我们的方法表明,将DNN应用于原始图像像素值提供了很好的结果。对于实现实时性能也是有利的。这与通用的基于DNN的方法[25,29]相反,他们应用DNN只能处理,像边缘的特征而不是原始的像素输入,这在速度方面是一个缺点。此外,我们显示,级联的DNN非常适用于泛化和迁移学习,不使用Caltech数据训练的系统在Caltech行人数据集中具有强劲的性能。
获取行人检测的实时解决方案一直很困难。最近提出的WordChannel特征[9]在GPU(16 FPS)上提供实时解决方案,但average miss rate显着下降(42%)。精准的VeryFast方法[4]运行在100 FPS,但是miss rate还有进一步的损失。在通用对象检测的相关领域中,利用与我们相似容量的DNN,并且每个图像仅评估较少的候选区域,最准确的方法是Girshick等人[19],每帧在CPU上需要53秒,在GPU上每帧13秒,降低195倍。
我们进一步注意到,我们的方法很容易实现,因为它基于开源代码。更具体地说,我们使用Benenson和VeryFast算法[4]的协作者[2]提供的'Doppia'开源实现。我们的深层神经网络在开源cuda-convnet2代码中实现[1,24]。
本文的主要贡献是一个准确度高于以前的工作的行人检测系统,并实时运行。因此,它可以实际部署在现实生活中的行人检测系统中。没有其他先前的工作已经证明了这种能力。我们期望通过提供一个简单的实施,准确和有效的实时解决方案我们的工作能够影响未来的方法。因此,未来的方法可以继续进一步推动行人检测准确性的上限,同时保持方法快速实用。
2.Previous work
Viola and Jones提出了一种级联分类器方法[38],已被广泛应用于实时应用。该方法已经通过采用不同类型的特征和技术进行了扩展[13,26,27],但是从根本上讲,级联的概念,早期拒绝大多数测试样本,已被广泛用于实现实时性能。也许用于行人检测(和其他基于图像的检测任务)最受欢迎的特征是Dalal和Triggs开发的HOG特征[10]。
虽然不是实时的,约1 FPS,但这项工作对于开发更快更准确的行人检测特征发挥了重要作用,这些特征用于与SVM或decision forests相结合的最佳性能方法[5,12,26] 。可变形部件模型[17]已经在行人检测任务上取得了成功[33,40]。基于深度学习的技术也被应用于行人检测,并导致精度的提高[3,25,29,30,37]。这些方法仍然很慢,每个图像超过一秒[25]到几分钟[37]。更快的方法不以原始像素作为深度网络的输入,所以它们的精度降低。
3.Deep Network Cascades
基线深层神经网络的架构基于Krizhevsky等人的原始深层网络[24],被许多研究人员广泛采用和使用。但是,以滑动窗口方式运行时,速度非常慢。这里的一个关键区别在于,我们减少了一些卷积层的深度和感受野的大小,这是为了获得速度优势而做出的。我们的基准架构如图2所示。

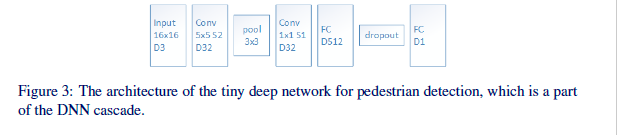
即使提出了加速,这个网络仍然很慢,不适合实时应用。为了加快速度,我们利用了我们以前工作中的一个小型卷积网络的想法[3]。微型DNN分类器只有三个隐藏层:5x5卷积,1x1卷积,以及512单元的非常浅的完全连接层;它是为了速度而如此设计的。当以级联运行时,它将首先处理所有图像块,并仅通过具有高置信度值的图像块。微型网络的架构如图3所示。
3.1 Fast Deep Network Cascade
我们注意到,我们的网络使用由Krizhevsky提供[1]的公开的“cuda-convnet2”代码进行训练,快速级联遵循由Benenson等人提供的GPU实现[2,4],使我们的方法容易获得重新实施和使用。
3.2 Runtime
3.3 Implementation details
Pretraining:我们利用预训练,即权重由已在Imagenet训练的网络的权重初始化。这是深层网络的标准做法,因为参数的数量远大于可用的训练数据。实验中我们将比较未经预训练的网络,并观察到对准确性的积极影响。其他工作也注意到了类似的效果,而且由于预训练易于整合,因此在我们的工作和其他工作中是首选。Data Generation :使用数据生成的标准程序,其中围绕行人样例裁剪一个方框。在数据生成时,裁剪的正方形图像大小调整为72x72。在训练DNN期间,每次迭代中随机裁剪64x64的图像块,以匹配网络的输入大小。这是一种用于训练卷积网络的标准数据增强技术,并允许训练样例的更多样的“视角”。这个微小的网络遵循相同的过程,调整输入的大小。我们进一步收集hard negative,这是重要的,因为初始生成的数据集从可用示例中均匀采样,并且包含大量简单的示例。此外,我们删除了宽度小于10像素的行人示例,因为这些示例在被视为单独的图像块时是不可区分的,并且对于不应用运动的方法(如我们的)不是有用的。















 2574
2574

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









