







首先根据网页源码灵活的获取到爬取图片的地址以及参数和分析数据结构(可通过F12获取)。
import time
import requests
import urllib
import os
img_wanted = str(input('请输入要爬取的图像名称:'))
img_file_path = r'C:\Users\ThinkStation\Desktop\爬图片\爬取_' + img_wanted
if os.path.exists(img_file_path) == False:
os.makedirs(img_file_path)
page = input("请输入要爬取多少页:")
page = int(page) + 1 # 确保其至少是一页,因为 输入值可以是 0
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'}
n = 0 # 图片的前缀 如 0.png
pn = 1 # pn是从第几张图片获取 百度图片下滑时默认一次性显示30张
for m in range(1, page):
url = 'https://image.baidu.com/search/acjson?'
param = {
'tn': 'resultjson_com',
'logid': '8846269338939606587',
'ipn': 'rj',
'ct': '201326592',
'is': '',
'fp': 'result',
'queryWord': img_wanted,
'cl': '2',
'lm': '-1',
'ie': 'utf-8',
'oe': 'utf-8',
'adpicid': '',
'st': '-1',
'z': '',
'ic': '',
'hd': '',
'latest': '',
'copyright': '',
'word': img_wanted,
's': '',
'se': '',
'tab': '',
'width': '',
'height': '',
'face': '0',
'istype': '2',
'qc': '',
'nc': '1',
'fr': '',
'expermode': '',
'force': '',
'cg': 'girl',
'pn': pn,
'rn': '30',
'gsm': '1e',
}
page_info = requests.get(url=url, headers=header, params=param)
page_info.encoding = 'utf-8' # 确保解析的格式是utf-8的
page_info = page_info.json() # 转化为json格式在后面可以遍历字典获取其值
info_list = page_info['data'] # 观察发现data中存在 需要用到的url地址
del info_list[-1] # 每一页的图片30张,下标是从 0 开始 29结束 ,那么请求的数据要删除第30个即 29为下标结束点
img_path_list = []
for i in info_list:
img_path_list.append(i['thumbURL'])
for index in range(len(img_path_list)):
print(img_path_list[index]) # 所有的图片的访问地址
time.sleep(1)
try:
urllib.request.urlretrieve(img_path_list[index], img_file_path + '/' + str(n) + '.jpg')
except Exception as e:
print('e')
n = n + 1
pn += 29
运行代码,输入要爬取的图像名称和保存多少页码的图像(1页30张):
请输入要爬取的图像名称:猫咪
请输入要爬取多少页:1
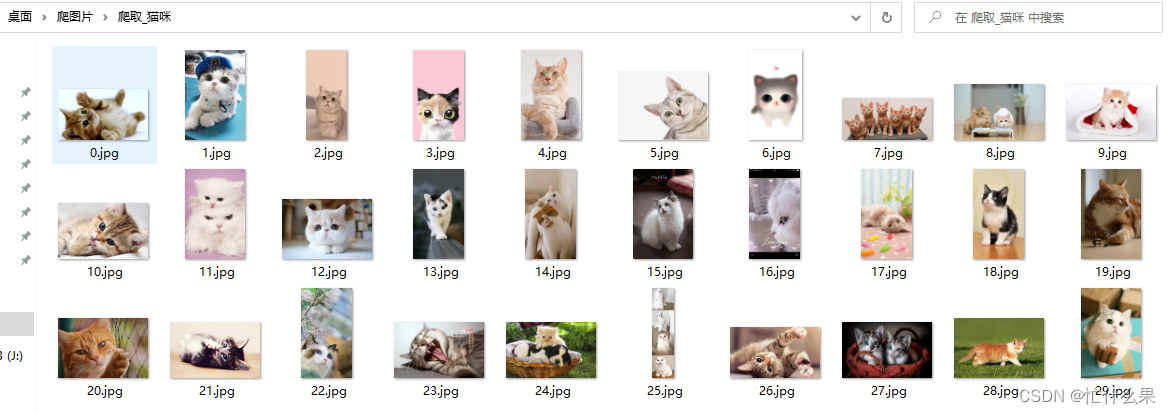
爬取60张机器人图片
请输入要爬取的图像名称:机器人
请输入要爬取多少页:2

















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











