







目录
干货分享,感谢您的阅读!
先分享一个真实的案例:某大型电商平台在一次促销活动中遭遇了数据库性能瓶颈,通过优化 InnoDB 的行格式,他们将查询性能提升了30%,存储成本降低了20%。这不仅帮助他们顺利度过了高峰期,还大大提升了用户体验。
- 查询性能提升:通过选择适当的行格式(如 Compact 或 Dynamic),可以减少存储开销和提升数据访问速度,从而加快查询响应时间。
- 存储成本降低:压缩行格式(如 Compressed)可以显著减少磁盘空间的使用,特别是在处理大量冗长字符串或重复数据时。
想象一下,你正在设计一个需要处理海量数据的应用,从用户信息到交易记录,每一行数据的存储方式都会直接影响到你的系统响应速度和存储成本。那么,如何选择最合适的行格式来最大化性能和效率呢?
本次我们聚焦 InnoDB 行格式,理解它们是如何在幕后悄悄发挥作用的。行格式的设计反映了数据库设计者在权衡性能、存储和兼容性时的决策。到现在为止一共设计了4种不同类型的行格式 ,分别是 Compact 、 Redundant 、Dynamic 和 Compressed 行格式,随着时间的推移,他们可能会设计出更多的行格式,但是不管怎么变,在原理上大体都是相同的。
我们本次主要针对Compact InnoDB 行格式进行分析理解。
一、InnoDB 行格式数据准备
在 MySQL 中,数据是以记录为单位插入到表中的,而这些记录在磁盘上的存放方式,就是我们所说的“行格式”或者“记录格式”。
首先,我们来看一下如何在创建或修改表时指定行格式。我们可以使用 CREATE TABLE 或 ALTER TABLE 语句来指定行格式。其语法如下:
CREATE TABLE 表名 (列的信息) ROW_FORMAT=行格式名称;
ALTER TABLE 表名 ROW_FORMAT=行格式名称;
假设我们在名为 xiaohaizi 的数据库中创建一个名为 record_format_demo 的表,并指定它的行格式为 Compact,同时设置字符集为 ASCII(ASCII 字符集只包括空格、标点符号、数字、大小写字母和一些不可见字符,所以我们的汉字是不能存到这个表里的)。如下所示:
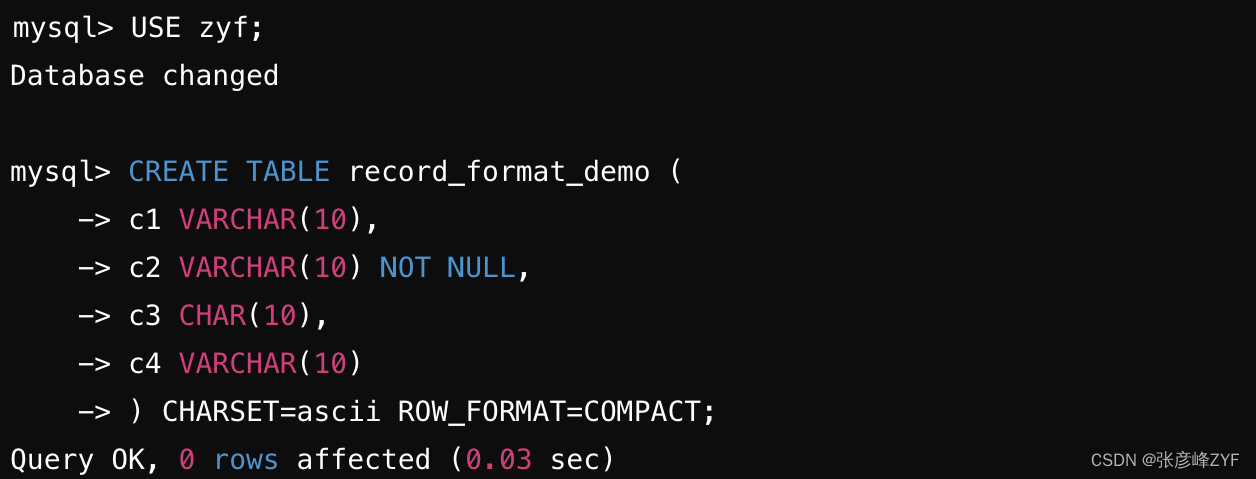
向这个表中插入两条记录,并查看插入结果:
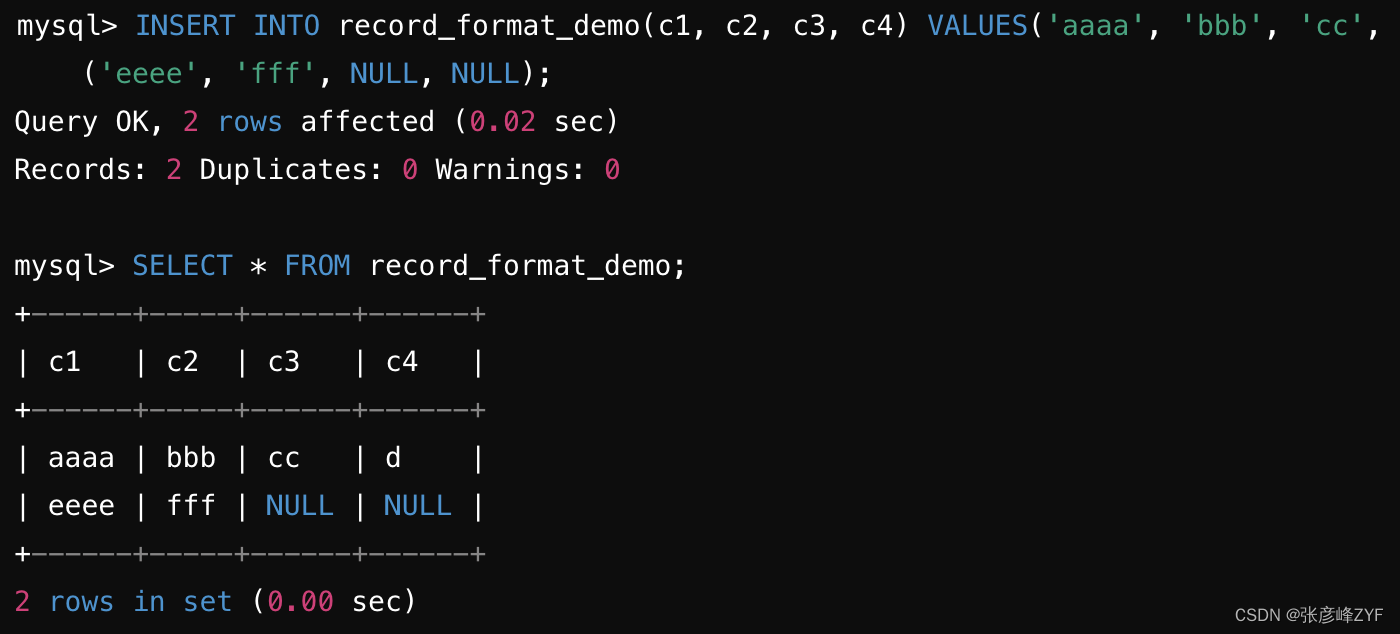
在实际应用中,选择合适的行格式可以显著提升数据库的性能和存储效率。例如,对于读多写少的场景,Compressed 行格式可能是一个不错的选择,而对于写操作频繁的场景,Compact 行格式可能会更合适。因各原理上大体都是相同,所以我们下面针对Compact进行理解。
二、COMPACT行格式整体说明
Compact 行格式适用于大多数通用场景,尤其是需要高效存储和读取的小型至中型表。它提供了良好的性能和平衡的存储效率,是 InnoDB 存储引擎中的默认选择。
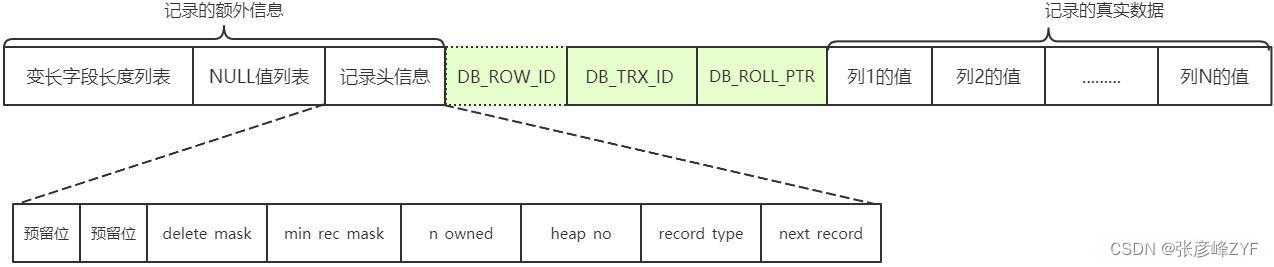
Compact 行格式在物理存储上采用以下结构:
- 行头信息:用于存储事务信息和回滚指针,占用 5 个字节。
- NULL 值位图:用于标识哪些列是 NULL 值,每个列对应 1 个 bit。
- 变长字段长度列表:紧跟在 NULL 值位图之后,记录变长字段的长度信息。
- 隐藏列:每行有 6 个字节用于两个隐藏的系统列,包括事务 ID 和回滚指针。
- 实际数据:存储实际的数据值,紧凑排列。
三、记录的额外信息
(一)变长字段长度列表
在 InnoDB 存储引擎的 Compact 行格式中,变长字段长度列表用于存储变长字段的长度信息,比如VARCHAR(M) 、 VARBINARY(M) 、各种 TEXT 类型,各种 BLOB 类 型。通过这种方式,Compact 行格式能够高效地管理和存储变长字段的数据。
由于变长字段的长度是不固定的,InnoDB 需要一种方式来记录和读取这些字段的实际长度,以便正确地存取数据。
数据结构
每个变长字段占用 1 到 2 个字节:长度小于 255 字节的字段使用 1 个字节来存储长度信息,而长度等于或大于 255 字节的字段使用 2 个字节来存储长度信息。
具体来说:
如果字段的长度小于 255 字节,则使用 1 个字节表示其长度。
如果字段的长度大于或等于 255 字节,则使用 2 个字节表示其长度。
存储过程
- 计算每个变长字段的实际长度:对于每个变长字段,计算其实际长度。
- 根据长度决定字节数:如果长度小于 255,则使用 1 个字节存储长度;否则,使用 2 个字节存储长度。
- 存储长度信息:将长度信息按顺序存储在变长字段长度列表中。
- 存储实际数据:紧跟在变长字段长度列表之后存储实际的数据值。
读取过程
- 读取变长字段长度列表:首先读取变长字段长度列表,获取每个变长字段的长度信息。
- 根据长度信息读取数据:根据变长字段长度列表中的长度信息,准确定位和读取每个变长字段的实际数据值。
变长字段长度列表存储示例
针对之前创建的 compact_format_demo 表和插入的数据进行分析:
- 针对第一条插入的数据 'aaaa', 'bbb', 'cc', 'd':
c1字段值为 'aaaa',长度为 4(占用 1 个字节表示长度)。c2字段值为 'bbb',长度为 3(占用 1 个字节表示长度)。c3字段值为 'cc',长度为 2(占用 1 个字节表示长度)。c4字段值为 'd',长度为 1(占用 1 个字节表示长度)。
- 针对第二条插入的数据 'eeee', 'fff', NULL, NULL':
c1字段值为 'eeee',长度为 4(占用 1 个字节表示长度)。c2字段值为 'fff',长度为 3(占用 1 个字节表示长度)。c3字段为 NULL,不需要额外的长度信息。c4字段为 NULL,不需要额外的长度信息。
变长字段长度列表是按照字段顺序紧跟在 NULL 值位图之后存储的。
- 对于第一条记录,长度列表为 [4][3][2][1],占用了 4 个字节。
- 对于第二条记录,长度列表为 [4][3],占用了 2 个字节。
总的长度列表占用了 6 个字节。
(二)NULL 值位图
在 InnoDB 存储引擎的 Compact 行格式中,NULL 值位图用于标识每个字段是否为 NULL 值。在 InnoDB 存储引擎中,NULL 值不占用实际的存储空间,因此需要一种方式来标识哪些字段是 NULL,以便在读取数据时正确处理这些字段。
数据结构
- 每个字段占用 1 个 bit:位图中的每个 bit 对应一列,用于标识该列是否为 NULL 值。
- 位图中的 bit 排列顺序:按照字段在表中的顺序依次排列,从左到右。
存储过程
- 遍历每个字段:对于每个字段,检查其是否为 NULL 值。
- 设置对应位图中的 bit:如果字段为 NULL 值,则将对应位图中的 bit 设置为 1;否则,将其设置为 0。
- 位图的实际存储:位图中的 bit 按照字段的顺序依次存储,每个 bit 占用 1 位。
读取过程
- 读取 NULL 值位图:首先读取 NULL 值位图,获取每个字段是否为 NULL 值的信息。
- 根据位图读取数据:根据位图中的信息,准确读取每个字段的数据值。如果对应位图中的 bit 为 1,则表示该字段为 NULL 值;否则,读取实际的数据值。
NULL 值位图示例说明
还是针对之前创建的 compact_format_demo 表和插入的数据进行分析:
-
对于第一条插入的数据 ('aaaa', 'bbb', 'cc', 'd'):
c1字段的值为 'aaaa',不是 NULL 值。c2字段的值为 'bbb',不是 NULL 值。c3字段的值为 'cc',不是 NULL 值。c4字段的值为 'd',不是 NULL 值。- NULL 值位图为 [0][0][0][0],表示所有字段均不为 NULL。
-
对于第二条插入的数据 ('eeee', 'fff', NULL, NULL):
c1字段的值为 'eeee',不是 NULL 值。c2字段的值为 'fff',不是 NULL 值。c3字段的值为 NULL,是 NULL 值。c4字段的值为 NULL,是 NULL 值。- NULL 值位图为 [0][0][1][1],表示
c3和c4字段为 NULL,而c1和c2字段不为 NULL。
(三)行头信息
在 InnoDB 存储引擎中,每个记录都有一个记录头信息,它由固定的 5 个字节(40 个二进制位)组成。这 5 个字节中的每一位都有特定的含义,描述了记录的一些重要信息。

基本定义分析
每个记录的开头有一个记录头信息,这些信息包含了对记录的描述和控制。以下是每个二进制位代表的详细信息:
-
预留位1(1 bit):该位暂时未被使用。
-
预留位2(1 bit):该位暂时未被使用。
-
delete_mask(1 bit):标记该记录是否被删除。如果被删除,则该位为 1;否则为 0。
-
min_rec_mask(1 bit):B+树的每层非叶子节点中的最小记录都会添加该标记。如果是最小记录,则该位为 1;否则为 0。
-
n_owned(4 bits):表示当前记录拥有的记录数。使用 4 个 bits 来表示,可以表示的最大值为 15。
-
heap_no(13 bits):表示当前记录在记录堆中的位置信息。使用 13 个 bits 来表示,可以表示的最大值为 8191。
-
record_type(3 bits):表示当前记录的类型。0:普通记录。1:B+树非叶子节点记录。2:最小记录。3:最大记录。
-
next_record(16 bits):表示下一条记录相对于当前记录的位置。使用 16 个 bits 来表示,可以表示的最大值为 65535。
这些记录头信息的二进制位提供了有关记录的详细描述,包括了是否被删除、记录的拥有数量、位置信息等。理解这些信息有助于更好地理解 InnoDB 存储引擎中记录的存储和组织方式,以及对数据库的性能和功能的影响。
案例分析
我们来分析一下 compact_format_demo 表中插入的第二条记录 ('eeee', 'fff', NULL, NULL)的记录头信息分析:
先整理理论依据:
- delete_mask:用于标记记录是否被删除。
- min_rec_mask:用于标记是否是 B+ 树非叶子节点中的最小记录。
- n_owned:表示当前记录拥有的记录数。
- heap_no:表示当前记录在记录堆中的位置信息。
- record_type:表示当前记录的类型,包括普通记录、B+ 树非叶子节点记录、最小记录和最大记录。
- next_record:表示下一条记录相对于当前记录的位置。
现在可以进行如下推断:
- 对于
delete_mask和min_rec_mask,根据描述,如果满足描述条件则为 1,否则为 0。 - 对于
n_owned,在这个例子中没有其他相关的记录,所以这个值应该是 0。 - 对于
heap_no,插入的第二条记录应该在记录堆的第二个位置,因此其二进制表示应该是 00000000000010。 - 对于
record_type,根据描述,这是一个普通记录,所以这个值应该是 0。 - 对于
next_record,因为这是最后一条记录,所以下一条记录的相对位置应该是 0。
综上所述,我们可以得出插入的第二条记录的记录头信息应该是:
delete_mask: 0
min_rec_mask: 0
n_owned: 0
heap_no: 2
record_type: 0
next_record: 0
四、隐藏列
(一)基本说明
了解记录的真实数据以外,还有一些隐藏列由MySQL自动添加到每个记录中,这些列包括:
-
row_id:行ID,用于唯一标识一条记录。在InnoDB表中,如果用户没有定义主键,也没有定义Unique键,则InnoDB会为表默认添加一个名为row_id的隐藏列作为主键。这个列的存在意味着即使没有显式定义主键,每条记录仍然有一个唯一的标识符。
-
transaction_id:事务ID,用于标识执行此次数据操作的事务。每个事务都有一个唯一的事务ID,这有助于数据库跟踪和管理事务的执行顺序,以及处理并发事务之间的冲突。
-
roll_pointer:回滚指针,用于实现多版本并发控制(MVCC)机制。回滚指针记录了事务开始时行的旧版本的位置,以便在需要时回滚事务或查询历史数据。
(二)主键的选择顺序说明
提及row_id涉及到主键的生成策略时,InnoDB表遵循一定的规则来确定主键的选择顺序。具体如下:
-
用户自定义主键:首先,InnoDB会优先选择用户自定义的主键作为表的主键。如果用户已经显式地定义了一个列作为主键,那么这个列将被用作表的主键。
-
Unique键作为主键:如果用户没有定义主键,但定义了一个Unique键(唯一索引),那么InnoDB会将这个Unique键作为表的主键。这样做是为了确保每条记录都有一个唯一的标识符。
-
默认主键(row_id):如果表中既没有用户自定义的主键,也没有定义Unique键,那么InnoDB会为表默认添加一个名为row_id的隐藏列作为主键。这个列是InnoDB内部生成的,用于确保每条记录都有一个唯一的标识符。
(三)案例分析
对于第二条插入的数据 ('eeee', 'fff', NULL, NULL):
-
事务ID:每个事务都有一个唯一的事务ID,表示执行此次数据操作的事务。对于第二条插入的记录,我们假设事务ID为 T2。
-
回滚指针:回滚指针用于实现多版本并发控制(MVCC)机制,记录了事务开始时行的旧版本的位置。对于第二条插入的记录,我们假设回滚指针为 RP2。
因此,插入的第二条记录的隐藏列值可能如下所示:
- 事务ID:T2(占用 6 个字节)
- 回滚指针:RP2(占用 6 个字节)
这些隐藏列的值是由InnoDB存储引擎自动生成的,对于用户来说是不可见的,支持事务管理和并发控制。
五、记录真实数据
记录的真实数据是指用户自定义的列数据,即在表中定义的可见列的值。
在 compact_format_demo 表中,可见列包括 c1、c2、c3 和 c4。对于第二条插入的记录 ('eeee', 'fff', NULL, NULL),其真实数据如下:
c1:'eeee'c2:'fff'c3:NULLc4:NULL
这些值是用户插入的数据,它们对于数据库来说是可见的,可以通过查询操作检索到。与隐藏列不同,这些数据由用户直接提供,并且在数据库中占据着特定的列位置。
因为表 record_format_demo 并没有定义主键,所以 MySQL 服务器会为每条记录增加上述的3个列。现在看一下加上 记录的真实数据 的两个记录长什么样吧:
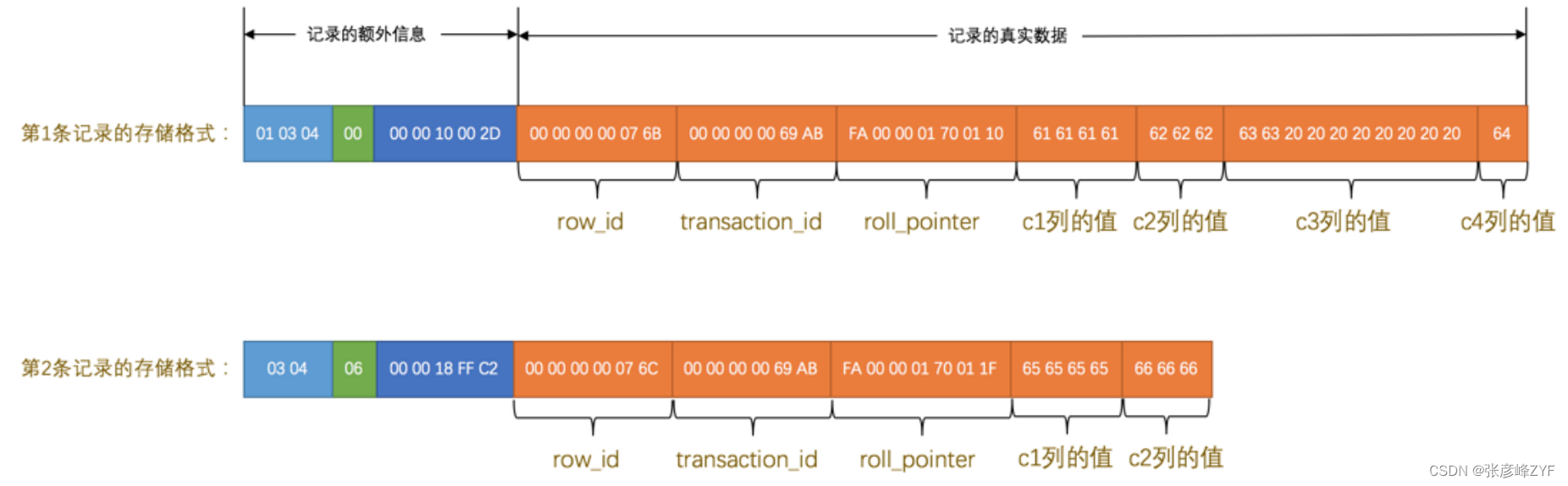
看这个图的时候我们需要注意几点:
- 表 record_format_demo 使用的是 ascii 字符集,所以 0x61616161 就表示字符串 'aaaa' , 0x626262 就表 示字符串 'bbb' ,以此类推。
- 注意第1条记录中 c3 列的值,它是 CHAR(10) 类型的,它实际存储的字符串是: 'cc' ,而 ascii 字符集中 的字节表示是 '0x6363' ,虽然表示这个字符串只占用了2个字节,但整个 c3 列仍然占用了10个字节的空 间,除真实数据以外的8个字节的统统都用空格字符填充,空格字符在 ascii 字符集的表示就是 0x20 。
- 注意第2条记录中 c3 和 c4 列的值都为 NULL ,它们被存储在了前边的 NULL值列表 处,在记录的真实数据处 就不再冗余存储,从而节省存储空间。
主要参考和学习来源
https://dev.mysql.com/doc/refman/5.7/en/
https://dev.mysql.com/doc/internals/en/
http://www.orczhou.com/
https://blog.jcole.us/innodb/

















 494
494

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











