







=======
lvs简介
what[1]:
先解决是什么的问题。什么是LVS呢?LVS就是Linux Virtual Server,本质上就是一个调度器/转发器/负载均衡器,看名字就知道是一个virtual server,并不作为server处理真正的业务。
why:
为什么会有这个玩意儿出现呢?很简单,当我们server的某个业务量(如web业务)剧增时一台server搞不定了(cpu,内存等有限),如何处理?解决方案无非两个,一个是换一台性能更好的服务器,这种扩展我们称之为scale up,但是这种方案的性价比不高,高性能(高价格)服务器获得相同单位性能的成本要高很多。就像小学生考试,80分提高到100分和60分提高到80分相比,付出的时间成本要高很多。况且,如果服务器已经顶配了还是没解决问题怎么办?单台server总是会有瓶颈,这时候我们应该想到既然单台搞不定,就多上几台一起处理,没错,这种水平扩展我们称之为scale out,扩展后的一群服务器我们就称之为集群(cluster)。那集群中这么多服务器如何分担业务处理呢?这时候就需要在集群前面实现业务请求分发的功能,把请求按照设计的算法把请求分发给后端的服务器。其实实现这种业务分发有很多中方法,LVS只是其中一种实现方案而已。
how:LVS
只是分发业务请求的一种实现方案而已,我们先进一步解释下业务请求的分发。所谓也去请求分发,就是当我访问一个业务,如
www.baidu.com
时,我的
web
请求被分发到哪台
server
。
DNS
是其中的一种近似实现方案(注意“近似”二字),
DNS
按照指定分配机制(可能基于后端
server
的处理能力设置权重)给不同的客户端分配
server IP
,这样用户请求就被分发到不同的
server
上,实现了负载均衡。这种方案有其弊端,即后端
server
宕机后,需要手动修改
DNS
上面的数据,剔除该
server
对应的
IP(LVS
自己也侦测不到后端的
server
宕机,需要其他工具辅助
)
。
DNS
这种方案我认为算不上是真正的业务分发,因为这个过程中并没有出现业务请求报文分发的过程,只是
DNS
给客户端分配了不同的
server IP
。而真正的业务分发在我看来应该是调度器收到业务请求报文后,根据请求的业务(三层:
server IP
四层:
server port
七层:请求的资源)来把报文分发给后端的
server
。我们这里要说的
LVS
就是
3
、
4
层的调度器,
也就是根据请求报文的3,4层信息做调度转发。
典型的
7
层调度器有
Nginx
。
what[2]:
既然
LVS
是
3
、
4
层调度器,必然就工作在协议栈,也就是内核中。与
iptables
类似,我们可以使用工具往内核写“调度规则”控制内核完成调度功能,而这个工具就是
ipvsadm
,稍后我们会看到如何使用这个工具实现
LVS
功能。
============
lvs的几个术语
两个角色:
director:我们把作为
LVS调度器的
server称之为
director
rs:也就是
real server,即真正处理业务的
server,
director把请求分发给他们处理。
四个IP:
CIP:
client ip,也就是
client的
IP
VIP:
virtual ip,即
director呈现给
client的
ip,
client访问的就是
VIP
DIP:
directory ip,即
director与
real server通信的
ip
RIP:
real server ip,即
real server与
director通信的
ip
===========
lvs的4种类型
既然
LVS
存在的价值就是完成业务请求的分发,那如何分发业务请求呢?从大的方面来讲
LVS
的使用可以分为
4
类场景,也就是
LVS
的类型。每一种场景都有多种算法以实现挑选后端集群中的主机。
1. lvs-nat
2. lvs-fullnat
3. lvs-dr
4. lvs-tun
下面我们详细介绍这4种LVS的工作机制和用法
1. lvs-nat
lvs-nat完成的功能类似于
iptables的
DNAT,其实
iptables的
DNAT确实也可以完成业务请求的分发,如下:
iptables -t nat -A PREROUTING -d IP0 -p tcp --dport PORT0 -j DNAT --to-destination IP1[:PORT1] --to-destination IP2[:PORT2] ...
该语句就可以实现将到
IP0 的请求分发给
IP1 或
IP2 ... ,不过仅版本早于
2.6.10 的内核支持多个
--to-destination(man iptables自行查看并验证
),同时
DNAT 仅仅能对
--set-destination后的
server IP 做简单的
round-robin,集群内的调度算法太单一。这也是为什么内核在
2.6.10 后停止了对
DNAT的多
--to-destination 选项的支持。而
lvs-nat 其实可以认为是一个功能更完善的
DNAT,支持多种调度算法,如
rr(round-robin),
wrr(weight round-robin)等,下面会详细介绍。和
DNAT 一样,这里的
director也需要将
ip_forward 这个内核参数设置为
1。
2. lvs-fullnat
lvs-fullnat就是功能强大一点的
SNAT+DNAT,不过这种类型的
lvs 暂时没有被收录进内核,如果要使用的话,需要手动将该功能编译进内核。
-----
上面提到的
2种
LVS实现,其上下行数据都需要经过
director,
director会记录一张
nat表,当下行数据到来时查表后才能把数据送达到正确的
client。不过既然
LVS的核心功能就是业务请求的分发,那其实只要上行数据经过
director就行了,下行数据能否不通过
director而直接由
real server回复给
client呢?毕竟下行数据多经过一个节点就多一点延迟嘛!可以。下面的两种
LVS类型就可以实现之。
3. lvs-dr
介绍
lvs-dr
之前先思考一下,
lvs-nat
这种类型的
LVS
是如何把业务请求报文转发给后端的
real server
的。其实就是按照我们配置的分发算法,挑选出一台
real server
并用该
real server
的
IP
替换报文中的“目标
IP”
,然后查路由表并把这个构造好的报文转发给那台选中的
real server
。
lvs-nat
是在三层实现报文分发的,而
lvs-dr
是在二层实现的,接下来我们看下实现细节。
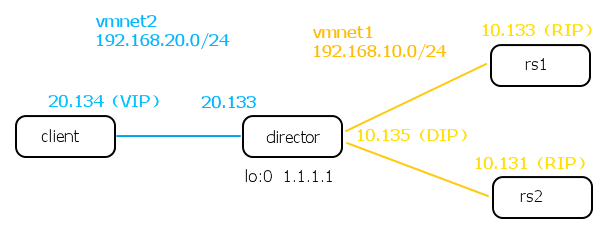
CIP:192.168.20.134/24
VIP:1.1.1.1/24
DIP:192.168.10.135/24
RIP:192.168.10.133/24 & 192.168.10.131/24
图中当
director
收到请求报文后,检查是否访问的是集群服务
(
在
LVS
中
VIP:PORT
定义一个集群服务
)
,如果是则在通过指定的挑选算法(调度算法)挑选出一台
real server
,并通过
ARP
广播获得其
MAC
,然后封装
2
层头,以
real server
的
MAC
为目标
MAC
在
2
层直接将报文发送给
real server(此时director就像一个普通的路由器,忽略了自己也有1.1.1.1这件事)
。因为报文中
3
层信息没有改动,
real server
要处理该报文,自身也需要配置
VIP
才可。当real server收到director转发来的报文后,进行正常处理并响应报文给client,所以这里要求real server的VIP对client的CIP路由可达。
(这里要求director和real server之间不能有3层设备,因为director要通过ARP广播得到RIP的MAC地址,而3层及3层以上的设备隔断了ARP广播。)
4. lvs-tun
等作出实验来再补充
-----
相比于
lvs-nat
,
lvs-dr
和
lvs-tun
由于下行数据不经过
director
,所以在一定程度上提高了响应速度。不过有一利必有一弊,高效率和多功能总是矛盾的一对儿,由于
director
不再有
nat
表,同时下行数据不再经过
director
,所以lvs-dr和lvs-tun不能完成端口映射功能,也就是
client
请求的是哪个端口,
LVS
就要老老实实地转给
real server
处理。
===================
ipvsadm的用法和实例
ipvsadm只是一个写 ipvs 规则的工具,之后将要讲到 keepalived 也可以用来生成 ipvs 规则,要对这个工具有个正确的认识。
yum -y install ipvsadm 安装之,用法简介如下,两步法完成配置,so easy!
配置步骤
1.管理集群服务
ipvsadm -A -t|u|f service-address [-s scheduler] [-p [timeout]] [-M netmask]
ipvsadm -E -t|u|f service-address [-s scheduler] [-p [timeout]] [-M netmask]
ipvsadm -D -t|u|f service-address
ipvsadm -C -t|u|f service-address
ipvsadm -L -n // -n 即numeric,指明不解析服务,如 80 就显示 80,不会解析为 http
所谓集群服务就是一个需要被调度的业务,ipvsadm支持3中分别为,tcp类型业务,udp类型业务 和 做了防火墙标签的业务,分别用 -t IP:Port,-u IP:port,-f some_value 来指明。tcp和udp类型的集群服务通过 IP:Port 来确定,防火墙标签类似于一个业务组标记,我们在director上通过iptables 在 mongle 链上做标记(用一个数字标识之,仅本机使用,因为该标记并不插入到报文中),然后把有这个标记的所有报文当成是对某一个集群服务的访问。
增改删查一个的集群服务的选项是:
-A(新增一个集群服务)
-E(修改一个集群服务)
-D(删除一个集群服务)
-C(清空所有的集群服务)
-L(查看所有的集群服务)
集群内的调度算法通过 -s(scheduler) 来指明,常见的调度算法有:
静态调度算法:
仅根据算法本身进行调度,适用于短连接业务多的场景
RR:round robin
WRR:Weighted RR
SH:source hash,实现session保持(损害了负载均衡),将来自同一个IP的请求始终分发给同一个RS
DH:destination hash,对同一个资源目标的请求始终发往同一个RS,一般用在Director后有缓存的场景
动态调度算法:根据算法及RS的当前负载状态(overhead)进行调度,director做的调度,自然知道当前连接情况。调度的时候有个称之为overhead的值,director就是根据这个值完成所谓的动态调度。
LC:Least Connection
overhead=Active*256+Inactive
WLC:Weighted LC
overhead={Active*256+Inactive}/Weight
SED:Shortest Expection Delay
overhead=
NQ:Never Queue
SED算法的改进
LBLC:Locality-Based LC
动态的DH算法
LBLCR:Locality-Based Least-Connection with Replication
2. 管理集群服务中的RS
ipvsadm -a -t|u|f service-address -r server-address [-g|i|m] [-w weight] [-x upper] [-y lower]
ipvsadm -e -t|u|f service-address -r server-address [-g|i|m] [-w weight] [-x upper] [-y lower]
ipvsadm -d -t|u|f service-address -r server-address
一个 cluster service 上至少定义一个 real server,要不 director 把服务调度给谁啊,其实如果仅仅一台 real server也没有必要设置 director,除非是考虑到了后期的扩容。
通过 -a,-e,-d 对一个由 -t|-u|-f 指定的集群服务添加 real server(-r 选项),并可以指明权重和 LVS 类型:lvs-nat(-m),lvs-dr(-g,默认选项),lvs-tun(-i)
配置实例
(1) lvs-nat,拓扑见上文第一张图,vmware上“仅主机模式”创建两个虚拟网络vmnet2(192.168.20.0/24)和vmnet1(192.168.10.0/24)
各 interface ip 通过DHCP获得,如下
CIP:192.168.20.134/24
DIP:192.168.10.135/24
RIP:192.168.10.133/24 & 192.168.10.131/24
配置如下
(rs上的httpd服务已经开启 )
:
client:
ip route add 1.1.1.1/32 via 192.168.20.133 //指明到 VIP 的路由,client要访问的是VIP
director:
ip add add 1.1.1.1/32 dev lo:0 //添加 VIP 到 loopback
echo 1 > /proc/sys/net/ipv4/ip_forward //开启ip转发
ipvsadm -A -t 1.1.1.1:80 -s rr //定义集群服务(1.1.1.1:80),且调度算法为 round-robin。调度器不用开80端口
ipvsamd -a -t 1.1.1.1:80 -r 192.168.10.133 -m //指明rs ip和LVS类型为 lvs-nat
ipvsadm -a -t 1.1.1.1:80 -r 192.168.10.131 -m
如上文所述,这里也可以先对服务打防火墙标记,然后针对打了标记的一组服务做调度,配置如下:
iptables -t mangle -A PREROUTING -d 1.1.1.1 -p tcp --dport 80 -j MARK --set-mark 5
ipvsadm -A -f 5 -s rr
ipvsadm -a -f 5 -r 192.168.10.133 -m
ipvsamd -a -f 5 -r 192.168.10.131 -m
rs1:
ip route add default via 192.168.10.135
rs2:
ip route add default via 192.168.10.135
-----
(2) lvs-dr,拓扑见上文第二张图,vmware上“仅主机模式”创建两个虚拟网络vmnet2(192.168.20.0/24)和vmnet1(192.168.10.0/24)
各 interface ip 通过DHCP获得,如下
CIP:192.168.20.134/24
DIP:192.168.10.135/24
RIP:192.168.10.133/24 & 192.168.10.131/24
配置如下(rs上的httpd服务已经开启):
client:
ip route add 1.1.1.1/32 via 192.168.20.133 //指明到 VIP 的路由,client要访问的是VIP
director:
ip add add 1.1.1.1/32 dev lo:0 //添加 VIP 到 loopback
ipvsadm -A -t 1.1.1.1:80 -s rr
ipvsadm -a -t 1.1.1.1:80 -r 192.168.10.133 -g //指明rs ip和LVS类型为 lvs-dr
ipvsadm -a -t 1.1.1.1:80 -r 192.168.10.133 -g
rs1:
ip add add 1.1.1.1/32 dev lo:0
ip route add default via 192.168.10.137 //添加报文回程路由
rs2:
ip add add 1.1.1.1/32 dev lo:0
ip route add default via 192.168.10.137 //添加报文回程路由
router:
echo 1 > /proc/sys/net/ipv4/ip_forward
ip route add 1.1.1.1 via 192.168.10.133 // 这一条不加不行(见链接:http://blog.csdn.net/xiaohaiyinyu/article/details/73656780),但是即使加了也不会用到,因为根本不会有到1.1.1.1的报文经过 router。
(finish)
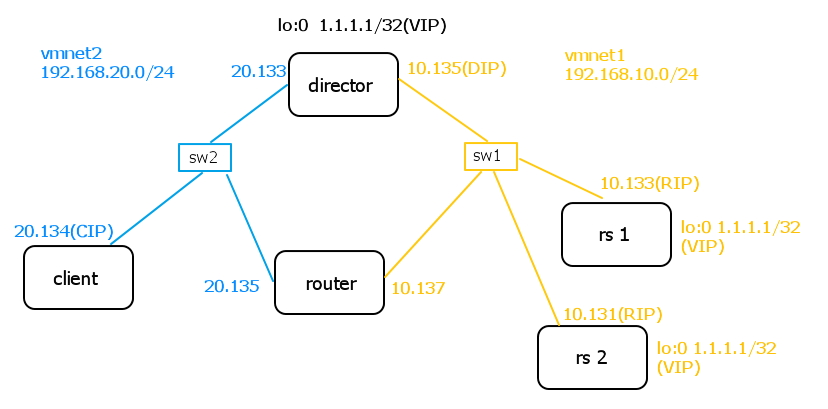
上面讲的 lvs-dr 是用来理解 lvs 工作原理的,生产环境中的拓扑如下,其中director上的VIP是正常公网IP,一般是配置在 interface 的别名上,如 eth1:0,而RS上的VIP依然配置在loopback上。
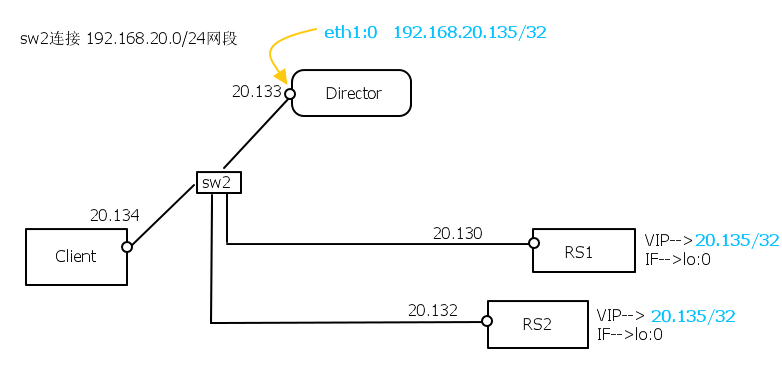
这种组网因为是在二层,因此 client 发送 arp 广播问 who is 192.168.20.135 时,RS1和RS2,也会回答。这就让 client 不知道 192.168.20.135的MAC到底是什么了。这里要确保 client 上的MAC地址表中对 192.168.20.135 的 MAC地址为 director上 eth1(举例)的MAC。如何保证?
如下两个参数:
/proc/sys/net/ipv4/conf/the_if_you_select(or all)/arp_ignore
RS1和RS2上参数设置为1,能够保证对于询问VIP的MAC的广播均不响应。
{默认值为
0,即某个接口到达的
ARP报文,如果请求的是本机的
IP,无论该
IP在哪个接口上(含
loopback接口),都给予回应。修改值为
1,即某个接口到达的
ARP报文,只有请求的是该接口的
IP,才给予回应。}
/proc/sys/net/ipv4/conf/the_if_you_select(or all)/arp_announce
我们设置 arp_ignore =1仅保证了对 ARP广播不应答,设置arp_announce=2 则保证了不会用loopback接口做源地址发送ARP广播(这样client就收不到来自RS的192.168.20.135的MAC了)。前者控制对被动ARP的行为,后者控制主动ARP的行为。
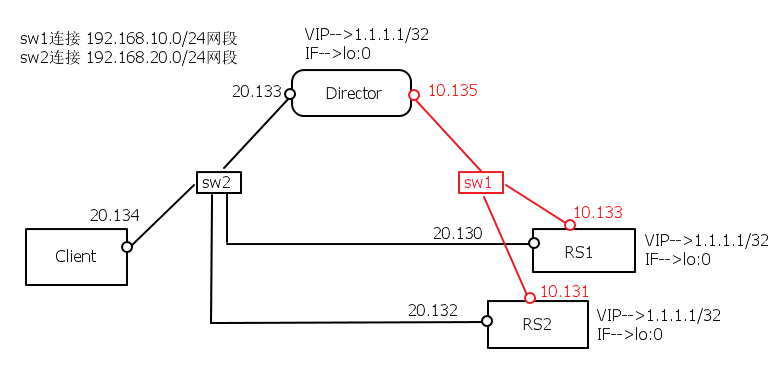
问题延伸之不作死就不会死:
我在上图的基础上改造出下图,通过抓包发现director确实能够实现调度,即对于1.1.1.1的访问,都能基于MAC轮流转给RS1和RS2。但是我想让RS1和RS2的响应报文从vmnet2回送给client,没想到 RS1和RS2竟然把从director调度过来的请求报文直接丢弃。在RS1和RS2上用 dropwatch -l kas 查看在协议栈哪一层丢的包,发现丢包发生在 ip_rcv_finish()函数。猜想是请求报文从某接口接收,也要求从相同接口回应,若相同接口无路由可达,则丢弃。换句话说就是,从某物理接口近来的请求报文,其响应报文也应该从该接口发送出去,若该接口到不了客户端,就直接丢弃,不多废话。
不过这个还是需要找源码验证!记录于此,以免忘记。
(其实我是先在这个拓扑下做的实验,因为不确定上面的猜想,所以把拓扑改造成本文中的第二张图中的拓扑,lvs-dr实验才做成功,泪奔。。。)
(3) lvs-tun,
这个涉及到tunl接口,实验做完后再补于此。















 3560
3560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









