







直接上代码
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
def test1():
# ax=y 求a
x = np.arange(1, 10)
x = x.reshape((9, 1))
y = np.arange(10, 100, 10)
y = y.reshape((9, 1))
# 数据划分
x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=22)
estimator = LinearRegression() # 线性回归(正规方程)
estimator.fit(x_train, y_train)
# 模型保存
# joblib.dump(estimator, './test.pkl')
# 模型加载
# estimator = joblib.load('./test.pkl')
y_predict = estimator.predict(x_test)
print(y_predict[:3])
print(y_test[:3])
print("系数:", estimator.coef_)
print('偏置:', estimator.intercept_)
error = mean_squared_error(y_test, y_predict)
print("误差为:", error)
# y=2x+7
def test2():
x = [2,3,4,5,6]
x = np.asarray(x)
x = x.reshape(5, 1)
y = [11,13,15,17,19]
y = np.asarray(y)
y = y.reshape(5, 1)
z = [7,8,9]
z = np.asarray(z)
z = z.reshape(1, 1)
# x_train, x_test, y_train, y_test = train_test_split(x, y, random_state=20)
estimator = LinearRegression() # 线性回归(正规方程)
estimator.fit(x, y)
# estimator.fit(x_train, y_train)
y_predict = estimator.predict(z)
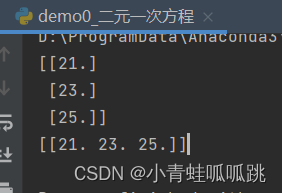
print(y_predict[:3])
print(y_predict.reshape(1, 3))
# print("系数:", estimator.coef_)
# print('偏置:', estimator.intercept_)
# error = mean_squared_error(y_test, y_predict)
# print("误差为:", error)
if __name__ == '__main__':
test1()
test2()
预测7,8,9的结果为
[[21. 23. 25.]]
















 3182
3182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









