








在第2章中,我们讨论了多种导入数据到R中的方法。遗憾的是,将你的数据表示为矩阵或数据框这样的矩形形式仅仅是数据准备的第一步。这里可以演绎Kirk船长在《星际迷航》“末日决战的滋味”一集中的台词(这完全验明了我的极客基因):“数据是一件麻烦事——一件非常非常麻烦的事。”在我的工作中,有多达60%的数据分析时间都花在了实际分析前数据的准备上。我敢大胆地说,多数需要处理现实数据的分析师可能都面临着以某种形式存在的类似问题。让我们先看一个例子。
4.1 一个示例
本人当前工作的研究主题之一是男性和女性在领导各自企业方式上的不同。典型的问题如下。
处于管理岗位的男性和女性在听从上级的程度上是否有所不同?
这种情况是否依国家的不同而有所不同,或者说这些由性别导致的不同是否普遍存在?
解答这些问题的一种方法是让多个国家的经理人的上司对其服从程度打分,使用的问题类似于:

结果数据可能类似于表4-1。各行数据代表了某个经理人的上司对他的评分。
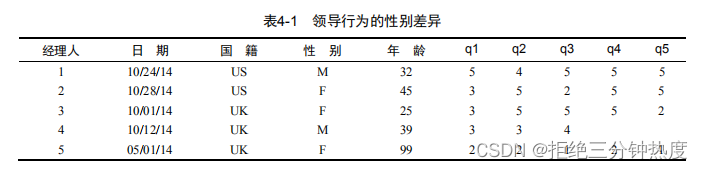
在这里,每位经理人的上司根据与服从权威相关的五项陈述(q1到q5)对经理人进行评分。例如,经理人1是一位在美国工作的32岁男性,上司对他的评价是惯于顺从,而经理人5是一位在英国工作的,年龄未知(99可能代表缺失)的女性,服从程度评分较低。日期一栏记录了进行评分的时间。
一个数据集中可能含有几十个变量和成千上万的观测,但为了简化示例,我们仅选取了5行10列的数据。另外,我们已将关于经理人服从行为的问题数量限制为5。在现实的研究中,你很可能会使用10到20个类似的问题来提高结果的可靠性和有效性。可以使用代码清单4-1中的代码创建一个包含表4-1中数据的数据框。
代码清单4-1 创建leadership数据框
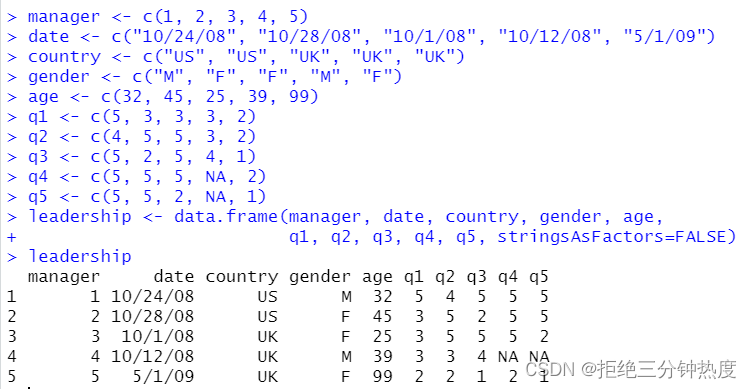
manager <- c(1, 2, 3, 4, 5)
date <- c("10/24/08", "10/28/08", "10/1/08", "10/12/08", "5/1/09")
country <- c("US", "US", "UK", "UK", "UK")
gender <- c("M", "F", "F", "M", "F")
age <- c(32, 45, 25, 39, 99)
q1 <- c(5, 3, 3, 3, 2)
q2 <- c(4, 5, 5, 3, 2)
q3 <- c(5, 2, 5, 4, 1)
q4 <- c(5, 5, 5, NA, 2)
q5 <- c(5, 5, 2, NA, 1)
leadership <- data.frame(manager, date, country, gender, age,
q1, q2, q3, q4, q5, stringsAsFactors=FALSE)
leadership
为了解决感兴趣的问题,你必须首先解决一些数据管理方面的问题。这里列出其中一部分。
五个评分(q1到q5)需要组合起来,即为每位经理人生成一个平均服从程度得分。
在问卷调查中,被调查者经常会跳过某些问题。例如,为4号经理人打分的上司跳过了问题4和问题5。你需要一种处理不完整数据的方法,同时也需要将99岁这样的年龄值重编码为缺失值。
一个数据集中也许会有数百个变量,但你可能仅对其中的一些感兴趣。为了简化问题,我们往往希望创建一个只包含那些感兴趣变量的数据集。
既往研究表明,领导行为可能随经理人的年龄而改变,二者存在函数关系。要检验这种观点,你希望将当前的年龄值重编码为类别型的年龄组(例如年轻、中年、年长)。
领导行为可能随时间推移而发生改变。你可能想重点研究最近全球金融危机期间的服从行为。为了做到这一点,你希望将研究范围限定在某一个特定时间段收集的数据上(比如,2009年1月1日到2009年12月31日)。
我们将在本章中逐个解决这些问题,同时完成如数据集的组合与排序这样的基本数据管理任务。然后,在第5章,我们会讨论一些更为高级的话题。
4.2 创建新变量
在典型的研究项目中,你可能需要创建新变量或者对现有的变量进行变换。这可以通过以下形式的语句来完成:
变量名 <- 表达式
以上语句中的“表达式”部分可以包含多种运算符和函数。表4-2列出了R中的算术运算符。算术运算符可用于构造公式(formula)。

假设你有一个名为mydata的数据框,其中的变量为x1和x2,现在你想创建一个新变量sumx存储以上两个变量的加和,并创建一个名为meanx的新变量存储这两个变量的均值。如果使用代码:
sumx <- x1 + x2
meanx <- (x1 + x2)/2
你将得到一个错误,因为R并不知道x1和x2来自于数据框mydata。如果你转而使用代码:
sumx <- mydata$x1 + mydata$x2
meanx <- (mydata$x1 + mydata$x2)/2
语句可成功执行,但是你只会得到一个数据框(mydata)和两个独立的向量(sumx和meanx)。这也许并不是你真的想要的。因为从根本上说,你希望将两个新变量整合到原始的数据框中。代码清单4-2提供了三种不同的方式来实现这个目标,具体选择哪一个由你决定,所得结果都是相同的。
代码清单4-2 创建新变量
mydata<-data.frame(x1 = c(2, 2, 6, 4),
x2 = c(3, 4, 2, 8))
mydata$sumx <- mydata$x1 + mydata$x2
mydata$meanx <- (mydata$x1 + mydata$x2)/2
attach(mydata)
mydata$sumx <- x1 + x2
mydata$meanx <- (x1 + x2)/2
detach(mydata)
mydata <- transform(mydata,
sumx = x1 + x2,
meanx = (x1 + x2)/2)
**我个人倾向于第三种方式,即transform()函数的一个示例。这种方式简化了按需创建新变量并将其保存到数据框中的过程。**
4.3 变量的重编码
重编码涉及根据同一个变量和/或其他变量的现有值创建新值的过程。举例来说,你可能想:
将一个连续型变量修改为一组类别值;
将误编码的值替换为正确值;
基于一组分数线创建一个表示及格/不及格的变量。
**要重编码数据,可以使用R中的一个或多个逻辑运算符(见表4-3)。逻辑运算符表达式可返回TRUE或FALSE。**

不妨假设你希望将leadership数据集中经理人的连续型年龄变量age重编码为类别型变量agecat(Young、 Middle Aged、Elder)。首先,必须将99岁的年龄值重编码为缺失值,使用的代码为:
leadership$age[leadership$age == 99] <- NA
语句`variable[condition] <- expression`将仅在condition的值为TRUE时执行赋值。
在指定好年龄中的缺失值后,你可以接着使用以下代码创建agecat变量:
leadership$agecat[leadership$age > 75] <- "Elder"
leadership$agecat[leadership$age >= 55 &
leadership$age <= 75] <- "Middle Aged"
leadership$agecat[leadership$age < 55] <- "Young"
你在leadership$agecat中写上了数据框的名称,以确保新变量能够保存到数据框中。(我将中年人(Middle Aged)定义为55到75岁,这样不会让我感觉自己是个老古董。)请注意,如果你一开始没把99重编码为age的缺失值,那么经理人5就将在变量agecat中被错误地赋值为“老年人”(Elder)。
这段代码可以写成更紧凑的:
leadership <- within(leadership,{
agecat <- NA
agecat[age > 75] <- "Elder"
agecat[age >= 55 & age <= 75] <- "Middle Aged"
agecat[age < 55] <- "Young" })
函数**within()**与函数**with()**类似(见2.2.4节),不同的是它允许你修改数据框。首先,创建了agecat变量,并将每一行都设为缺失值。括号中剩下的语句接下来依次执行。请记住agecat现在只是一个字符型变量,你可能更希望像2.2.5节讲解的那样把它转换成一个有序型因子。
若干程序包都提供了实用的变量重编码函数,特别地,car包中的**recode()**函数可以十分简便地重编码数值型、字符型向量或因子。而doBy包提供了另外一个很受欢迎的函数**recodevar()**。最后,R中也自带了**cut()**,可将一个数值型变量按值域切割为多个区间,并返回一个因子。
4.4 变量的重命名
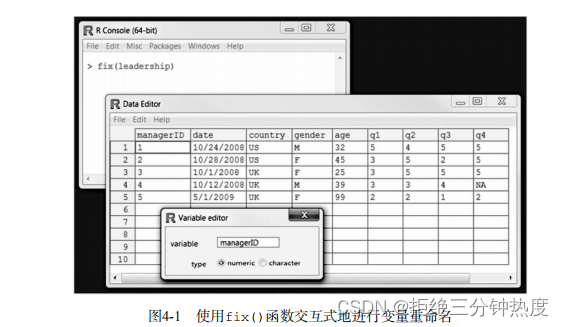
如果对现有的变量名称不满意,你可以交互地或者以编程的方式修改它们。假设你希望将变量名manager修改为managerID,并将date修改为testDate,那么可以使用语句:
fix(leadership)
来调用一个交互式的编辑器。然后你单击变量名,然后在弹出的对话框中将其重命名(见图4-1)。
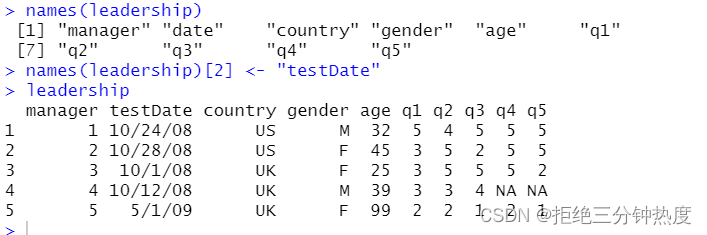
若以编程方式,可以通过names()函数来重命名变量。例如:
names(leadership)[2] <- "testDate"
将重命名date为testDate,就像以下代码演示的一样:
names(leadership)
names(leadership)[2] <- "testDate"
leadership
以类似的方式:
names(leadership)[6:10] <- c("item1", "item2", "item3", "item4", "item5")
将重命名q1到q5为item1到item5。
最后,plyr包中有一个rename()函数,可用于修改变量名。这个函数默认并没有被安装,所以你首先要使用命令install.packages("plyr")对之进行安装。
**rename()函数的使用格式为:**
rename(dataframe, c(oldname="newname", oldname="newname",...))
这里是一个示例:
library(plyr)
leadership <- rename(leadership,
c(manager="managerID", date="testDate"))
plyr包拥有一系列强大的数据集操作函数,你可以在http://had.co.nz/plyr获得更多信息。
4.5 缺失值
在任何规模的项目中,数据都可能由于未作答问题、设备故障或误编码数据的缘故而不完整。在R中,缺失值以符号NA(Not Available,不可用)表示。与SAS等程序不同,R中字符型和数值型数据使用的缺失值符号是相同的。
R提供了一些函数,用于识别包含缺失值的观测。函数is.na()允许你检测缺失值是否存在。假设你有一个向量:
y <- c(1, 2, 3, NA)
然后使用函数:
is.na(y)
将返回c(FALSE, FALSE, FALSE, TRUE)。
请注意is.na()函数是如何作用于一个对象上的。它将返回一个相同大小的对象,如果某个元素是缺失值,相应的位置将被改写为TRUE,不是缺失值的位置则为FALSE。代码清单4-3将此函数应用到了我们的leadership数据集上。
代码清单4-3 使用is.na()函数
is.na(leadership[,6:10])
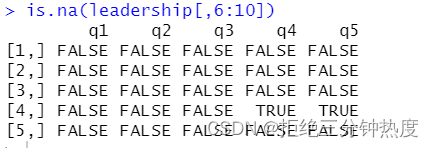
这里的leadership[,6:10]将数据框限定到第6列至第10列,接下来is.na()识别出了缺失值。
当你在处理缺失值的时候,你要一直记得两件重要的事情。第一,缺失值被认为是不可比较的,即便是与缺失值自身的比较。这意味着无法使用比较运算符来检测缺失值是否存在。例如,逻辑测试myvar == NA的结果永远不会为TRUE。作为替代,你只能使用处理缺失值的函数(如本节中所述的那些)来识别出R数据对象中的缺失值。
第二,R 并不把无限的或者不可能出现的数值标记成缺失值。再次地,这和其余像SAS之类类似的程序处理这类数值的方式所不同。正无穷和负无穷分别用Inf和–Inf所标记。因此5/0返 回Inf。不可能的值(比如说,sin(Inf))用NaN符号来标记(not a number,不是一个数)。若要识别这些数值,你需要用到is.infinite()或is.nan()。
4.5.1 重编码某些值为缺失值
如4.3节中演示的那样,你可以使用赋值语句将某些值重编码为缺失值。在我们的leadership示例中,缺失的年龄值被编码为99。在分析这一数据集之前,你必须让R明白本例中的99表示缺失值(否则这些样本的平均年龄将会高得离谱)。你可以通过重编码这个变量完成这项工作:
leadership$age[leadership$age == 99] <- NA
任何等于99的年龄值都将被修改为NA。请确保所有的缺失数据已在分析之前被妥善地编码为缺失值,否则分析结果将失去意义。
4.5.2 在分析中排除缺失值
确定了缺失值的位置以后,你需要在进一步分析数据之前以某种方式删除这些缺失值。原因是,含有缺失值的算术表达式和函数的计算结果也是缺失值。举例来说,考虑以下代码:
x <- c(1, 2, NA, 3)
y <- x[1] + x[2] + x[3] + x[4]
z <- sum(x)
由于x中的第3个元素是缺失值,所以y和z也都是NA(缺失值)。
好在多数的数值函数都拥有一个na.rm=TRUE选项,可以在计算之前移除缺失值并使用剩余值进行计算:
x <- c(1, 2, NA, 3)
y <- sum(x, na.rm=TRUE)
这里,y等于6。
在使用函数处理不完整的数据时,请务必查阅它们的帮助文档(例如,help(sum)),检查这些函数是如何处理缺失数据的。函数sum()只是我们将在第5章中讨论的众多函数之一,使用这些函数可以灵活而轻松地转换数据。
你可以通过函数na.omit()移除所有含有缺失值的观测。na.omit()可以删除所有含有缺失数据的行。在代码清单4-4中,我们将此函数应用到了leadership数据集上。
代码清单4-4 使用na.omit()删除不完整的观测
leadership
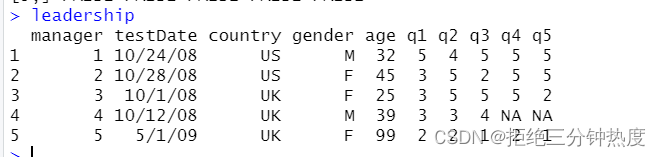
newdata <- na.omit(leadership)
newdata

在结果被保存到newdata之前,所有包含缺失数据的行均已从leadership中删除。
删除所有含有缺失数据的观测(称为行删除,listwise deletion)是处理不完整数据集的若干手段之一。如果只有少数缺失值或者缺失值仅集中于一小部分观测中,行删除不失为解决缺失值问题的一种优秀方法。但如果缺失值遍布于数据之中,或者一小部分变量中包含大量的缺失数据,行删除可能会剔除相当比例的数据。我们将在第18章中探索若干更为复杂精妙的缺失值处理方法。下面,让我们谈谈日期值。
4.6 日期值
日期值通常以字符串的形式输入到R中,然后转化为以数值形式存储的日期变量。函数as.Date()用于执行这种转化。其语法为as.Date(x, "input_format"),其中x是字符型数据,input_format则给出了用于读入日期的适当格式(见表4-4)。

日期值的默认输入格式为yyyy-mm-dd。语句:
mydates <- as.Date(c("2007-06-22", "2004-02-13"))
将默认格式的字符型数据转换为了对应日期。相反,
strDates <- c("01/05/1965", "08/16/1975")
dates <- as.Date(strDates, "%m/%d/%Y")
dates

则使用mm/dd/yyyy的格式读取数据。
在leadership数据集中,日期是以mm/dd/yy的格式编码为字符型变量的。因此:
myformat <- "%m/%d/%y"
leadership$date <- as.Date(leadership$date, myformat)
使用指定格式读取字符型变量,并将其作为一个日期变量替换到数据框中。这种转换一旦完成,你就可以使用后续各章中讲到的诸多分析方法对这些日期进行分析和绘图。
有两个函数对于处理时间戳数据特别实用。Sys.Date()可以返回当天的日期,而date()则返回当前的日期和时间。我写下这段文字的时间是2014年11月27日下午1:21。所以执行这些函
数的结果是:
Sys.Date()

data()

你可以使用函数format(x, format="output_format")来输出指定格式的日期值,并且可以提取日期值中的某些部分:
today <- Sys.Date()
format(today, format="%B %d %Y")
format(today, format="%A")
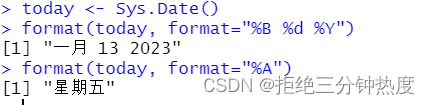
format()函数可接受一个参数(本例中是一个日期)并按某种格式输出结果(本例中使用了表4-4中符号的组合)。这里最重要的结果是,距离周末只有两天时间了!
R的内部在存储日期时,是使用自1970年1月1日以来的天数表示的,更早的日期则表示为负数。这意味着可以在日期值上执行算术运算。例如:
startdate <- as.Date("2004-02-13")
enddate <- as.Date("2011-01-22")
days <- enddate - startdate
days
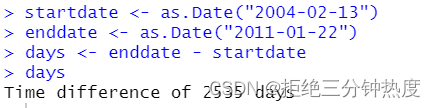
显示了2004年2月13日和2011年1月22日之间的天数。
最后,也可以使用函数difftime()来计算时间间隔,并以星期、天、时、分、秒来表示。假设我出生于1956年10月12日,我现在有多大呢?
today <- Sys.Date()
dob <- as.Date("1956-10-12")
difftime(today, dob, units="weeks")

4.6.1 将日期转换为字符型变量
你同样可以将日期变量转换为字符型变量。函数`as.character()`可将日期值转换为字符型:
strDates <- as.character(dates)
进行转换后,即可使用一系列字符处理函数处理数据(如取子集、替换、连接等)。我们将在第5章中详述字符处理函数。
4.6.2 更进一步
要了解字符型数据转换为日期的更多细节,请查看`help(as.Date)`和`help(strftime)`。要了解更多关于日期和时间格式的知识,请参考`help(ISOdatetime)`。lubridate包中包含了许多简化日期处理的函数,可以用于识别和解析日期—时间数据,抽取日期—时间成分(例如年份、月份、日期等),以及对日期—时间值进行算术运算。如果你需要对日期进行复杂的计算,那么timeDate包可能会有帮助。它提供了大量的日期处理函数,可以同时处理多个时区,并且提供了复杂的历法操作功能,支持工作日、周末以及假期。
4.7 类型转换
在上节中,我们讨论了将字符数据转换为日期值以及逆向转换的方法。R中提供了一系列用
来判断某个对象的数据类型和将其转换为另一种数据类型的函数。
R与其他统计编程语言有着类似的数据类型转换方式。举例来说,向一个数值型向量中添加一个字符串会将此向量中的所有元素转换为字符型。你可以使用表4-5中列出的函数来判断数据的类型或者将其转换为指定类型。

名为is.datatype()这样的函数返回TRUE或FALSE,而as.datatype()这样的函数则将其参数转换为对应的类型。代码清单4-5提供了一个示例。
代码清单4-5 转换数据类型
a <- c(1,2,3)
a
is.numeric(a)
is.vector(a)
a <- as.character(a)
is.numeric(a)
is.vector(a)
is.character(a)

当和第5章中讨论的控制流(如if-then)结合使用时,is.datatype()这样的函数将成为一类强大的工具,即允许根据数据的具体类型以不同的方式处理数据。另外,某些R函数需要接受某个特定类型(字符型或数值型,矩阵或数据框)的数据,as.datatype()这类函数可以让你在分析之前先行将数据转换为要求的格式。
4.8 数据排序
有些情况下,查看排序后的数据集可以获得相当多的信息。例如,哪些经理人最具服从意识?在R中,可以使用order()函数对一个数据框进行排序。默认的排序顺序是升序。在排序变量的前边加一个减号即可得到降序的排序结果。以下示例使用leadership演示了数据框的排序。
语句:
newdata <- leadership[order(leadership$age),]
创建了一个新的数据集,其中各行依经理人的年龄升序排序。语句:
attach(leadership)
newdata <- leadership[order(gender, age),]
detach(leadership)
则将各行依女性到男性、同样性别中按年龄升序排序。
最后,
attach(leadership)
newdata <-leadership[order(gender, -age),]
detach(leadership)
将各行依经理人的性别和年龄降序排序。
4.9 数据集的合并
如果数据分散在多个地方,你就需要在继续下一步之前将其合并。本节展示了向数据框中添加列(变量)和行(观测)的方法。
4.9.1 向数据框添加列
要横向合并两个数据框(数据集),请使用merge()函数。在多数情况下,两个数据框是通过一个或多个共有变量进行联结的(即一种内联结,inner join)。例如:
total <- merge(dataframeA, dataframeB, by="ID")
将dataframeA和dataframeB按照ID进行了合并。类似地,
total <- merge(dataframeA, dataframeB, by=c("ID","Country"))
将两个数据框按照ID和Country进行了合并。类似的横向联结通常用于向数据框中添加变量。

4.9.2 向数据框添加行
要纵向合并两个数据框(数据集),请使用rbind()函数:
total <- rbind(dataframeA, dataframeB)
两个数据框必须拥有相同的变量,不过它们的顺序不必一定相同。如果dataframeA中拥有dataframeB中没有的变量,请在合并它们之前做以下某种处理:
删除dataframeA中的多余变量;
在dataframeB中创建追加的变量并将其值设为NA(缺失)。
纵向联结通常用于向数据框中添加观测。
4.10 数据集取子集
R拥有强大的索引特性,可以用于访问对象中的元素。也可利用这些特性对变量或观测进行选入和排除。以下几节演示了对变量和观测进行保留或删除的若干方法。
4.10.1 选入(保留)变量
从一个大数据集中选择有限数量的变量来创建一个新的数据集是常有的事。在第2章中,数据框中的元素是通过`dataframe[row indices, column indices]`这样的记号来访问的。你可以沿用这种方法来选择变量。例如:
newdata <- leadership[, c(6:10)]
从`leadership`数据框中选择了变量q1、q2、q3、q4和q5,并将它们保存到了数据框newdata中。将行下标留空(,)表示默认选择所有行。 语句:
myvars <- c("q1", "q2", "q3", "q4", "q5")
newdata <-leadership[myvars]
实现了等价的变量选择。这里,(引号中的)变量名充当了列的下标,因此选择的列是相同的。
最后,其实你可以写:
myvars <- paste("q", 1:5, sep="")
newdata <- leadership[myvars]
本例使用paste()函数创建了与上例中相同的字符型向量。paste()函数将在第5章中讲解。
4.10.2 剔除(丢弃)变量
剔除变量的原因有很多。举例来说,如果某个变量中有很多缺失值,你可能就想在进一步分析之前将其丢弃。下面是一些剔除变量的方法。
你可以使用语句:
myvars <- names(leadership) %in% c("q3", "q4")
newdata <- leadership[!myvars]
剔除变量q3和q4。为了理解以上语句的原理,你需要把它拆解如下
(1) names(leadership) 生成了一个包含所有变量名的字符型向量:
c("managerID","testDate","country","gender","age","q1", "q2","q3","q4","q5")
(2) names(leadership) %in% c(“q3”, “q4”) 返回了一个逻辑型向量,
names(leadership)中每个匹配q3或q4的元素的值为TRUE,反之为FALSE:
c(FALSE, FALSE,
FALSE, FALSE, FALSE, FALSE, FALSE, TRUE, TRUE, FALSE)。
(3) 运算符非(!)将逻辑值反转:c(TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, TRUE)。
(4) leadership[c(TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, TRUE, FALSE, FALSE, TRUE)]选择了逻辑值为TRUE的列,于是q3和q4被剔除了。
在知道q3和q4是第8个和第9个变量的情况下,可以使用语句:
newdata <- leadership[c(-8,-9)]
将它们剔除。这种方式的工作原理是,在某一列的下标之前加一个减号(–)就会剔除那一列。
最后,相同的变量删除工作亦可通过:
leadership$q3 <- leadership$q4 <- NULL
来完成。这回你将q3和q4两列设为了未定义(NULL)。注意,NULL与NA(表示缺失)是不同的。
丢弃变量是保留变量的逆向操作。选择哪一种方式进行变量筛选依赖于两种方式的编码难易
程度。如果有许多变量需要丢弃,那么直接保留需要留下的变量可能更简单,反之亦然。
4.10.3 选入观测
选入或剔除观测(行)通常是成功的数据准备和数据分析的一个关键方面。代码清单4-6给出了一些例子。
代码清单4-6 选入观测
newdata <- leadership[1:3,] #选择第1行到第3行(前三个观测)
newdata <- leadership[leadership$gender=="M" &
leadership$age > 30,] #选择所有30岁以上的男性
attach(leadership)
newdata <- leadership[gender=='M' & age > 30,]
detach(leadership)
在以上每个示例中,你只提供了行下标,并将列下标留空(故选入了所有列)。在第一个示例中,你选择了第1行到第3行(前三个观测)。
让我们拆解第二行代码以便理解它。
(1) 逻辑比较leadership$gender=="M"生成了向量c(TRUE, FALSE, FALSE, TRUE, FALSE)。
(2) 逻辑比较leadership$age > 30生成了向量c(TRUE, TRUE, FALSE, TRUE, TRUE)。
(3) 逻辑比较c(TRUE, FALSE, FALSE, TRUE, TRUE) & c(TRUE, TRUE, FALSE, TRUE, TRUE)生成了向量c(TRUE, FALSE, FALSE, TRUE, FALSE)。
(4) leadership[c(TRUE, FALSE, FALSE, TRUE, FALSE),]从数据框中选择了第一个和第四个观测(当对应行的索引是TRUE,这一行被选入;当对应行的索引是FALSE,这一行被剔除)。这就满足了我们的选取准则(30岁以上的男性)。
在本章开始的时候,我曾经提到,你可能希望将研究范围限定在2009年1月1日到2009年12月31日之间收集的观测上。怎么做呢?这里有一个办法:
leadership$date <- as.Date(leadership$date, "%m/%d/%y")#使用格式mm/dd/yy将开始作为字符值读入的日期转换为日期值
startdate <- as.Date("2009-01-01") #创建开始日期
enddate <- as.Date("2009-10-31")#创建结束日期
newdata <- leadership[which(leadership$date >= startdate &
leadership$date <= enddate),]# 像上例一样选取那些满
足你期望中准则的个案
注意,由于as.Date()函数的默认格式就是yyyy-mm-dd,所以你无需在这里提供这个参数。
4.10.4 subset()函数
前两节中的示例很重要,因为它们辅助描述了逻辑型向量和比较运算符在R中的解释方式。理解这些例子的工作原理在总体上将有助于你对R代码的解读。既然你已经用笨办法完成了任务,现在不妨来看一种简便方法。
使用subset()函数大概是选择变量和观测最简单的方法了。两个示例如下:
newdata <- subset(leadership, age >= 35 | age < 24,
select=c(q1, q2, q3, q4))#选择所有age值大于等于35或age值
小于24的行,保留了变量q1到q4
newdata <- subset(leadership, gender=="M" & age > 25,
select=gender:q4)#选择所有25岁以上的男性,并保留了变量gender到q4(gender、q4和其间所有列)
你在第2章中已经看到了冒号运算符from:to。在这里,它表示了数据框中变量from到变量to包含的所有变量。
4.10.5 随机抽样
在数据挖掘和机器学习领域,从更大的数据集中抽样是很常见的做法。举例来说,你可能希望选择两份随机样本,使用其中一份样本构建预测模型,使用另一份样本验证模型的有效性。sample()函数能够让你从数据集中(有放回或无放回地)抽取大小为n的一个随机样本。
你可以使用以下语句从leadership数据集中随机抽取一个大小为3的样本:
mysample <- leadership[sample(1:nrow(leadership), 3, replace=FALSE),]
sample()函数中的第一个参数是一个由要从中抽样的元素组成的向量。在这里,这个向量是1到数据框中观测的数量,第二个参数是要抽取的元素数量,第三个参数表示无放回抽样。sample()函数会返回随机抽样得到的元素,之后即可用于选择数据框中的行。
R中拥有齐全的抽样工具,包括抽取和校正调查样本(参见sampling包)以及分析复杂调查数据(参见survey包)的工具。其他依赖于抽样的方法,包括自助法和重抽样统计方法,详见第12章。
4.11 使用 SQL 语句操作数据框
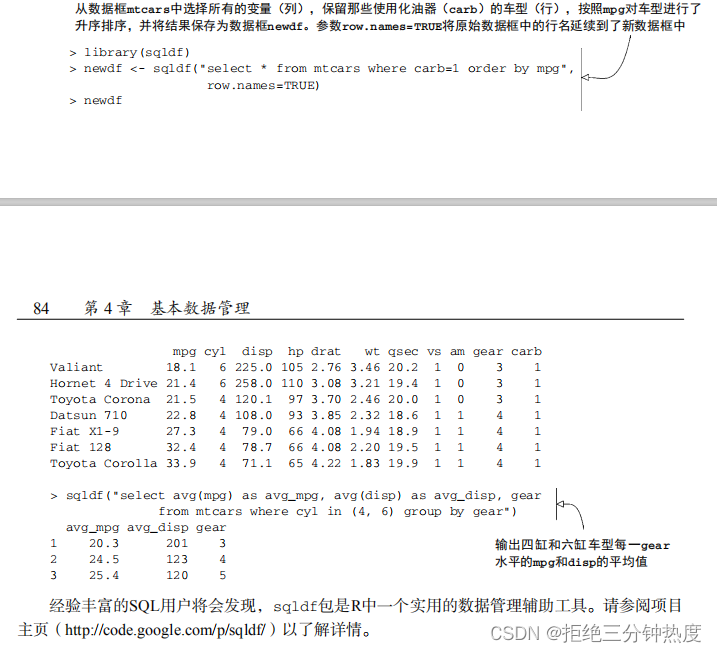
到目前为止,你一直在使用R语句操作数据。但是,许多数据分析人员在接触R之前就已经精通了结构化查询语言(SQL),要丢弃那么多积累下来的知识实为一件憾事。因此,在我们结束本章之前简述一下sqldf包。(如果你对SQL不熟,请尽管跳过本节。)
在下载并安装好这个包以后(install.packages(“sqldf”)),你可以使用sqldf()函数在数据框上使用SQL中的SELECT语句。代码清单4-7给出了两个示例。
代码清单4-7 使用SQL语句操作数据框
4.12 小结
本章讲解了大量的基础知识。首先我们看到了R存储缺失值和日期值的方式,并探索了它们的多种处理方法。接着学习了如何确定一个对象的数据类型,以及如何将它转换为其他类型。还使用简单的公式创建了新变量并重编码了现有变量。你学习了如何对数据进行排序和对变量进行重命名,学习了如何对数据和其他数据集进行横向合并(添加变量)和纵向合并(添加观测)。最后,我们讨论了如何保留或丢弃变量,以及如何基于一系列的准则选取观测。
在下一章中,我们将着眼于R中不计其数的,用于创建和转换变量的算术函数、字符处理函数和统计函数。在探索了控制程序流程的方式之后,你将了解到如何编写自己的函数。我们也将
探索如何使用这些函数来整合及概括数据。
在第5章结束时,你就能掌握管理复杂数据集的多数工具。(无论你走到哪里,都将成为数据分析师艳羡的人物!)
5、参考来源:















 2505
2505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









