







 本文介绍了如何使用Python的Lxml、Request和Beautifulsoup库,快速编写一个信息收集器,爬取并整理全国各城市的大学名称。通过分析网页结构,设置循环和异常处理,实现了数据抓取并按城市存储到不同的TXT文件中,适合Python初学者学习。
本文介绍了如何使用Python的Lxml、Request和Beautifulsoup库,快速编写一个信息收集器,爬取并整理全国各城市的大学名称。通过分析网页结构,设置循环和异常处理,实现了数据抓取并按城市存储到不同的TXT文件中,适合Python初学者学习。
环境:
Python 3
模块:
Lxml
Request
Beautifulsoup
开始:
首先看一下目标站:
http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-1.html
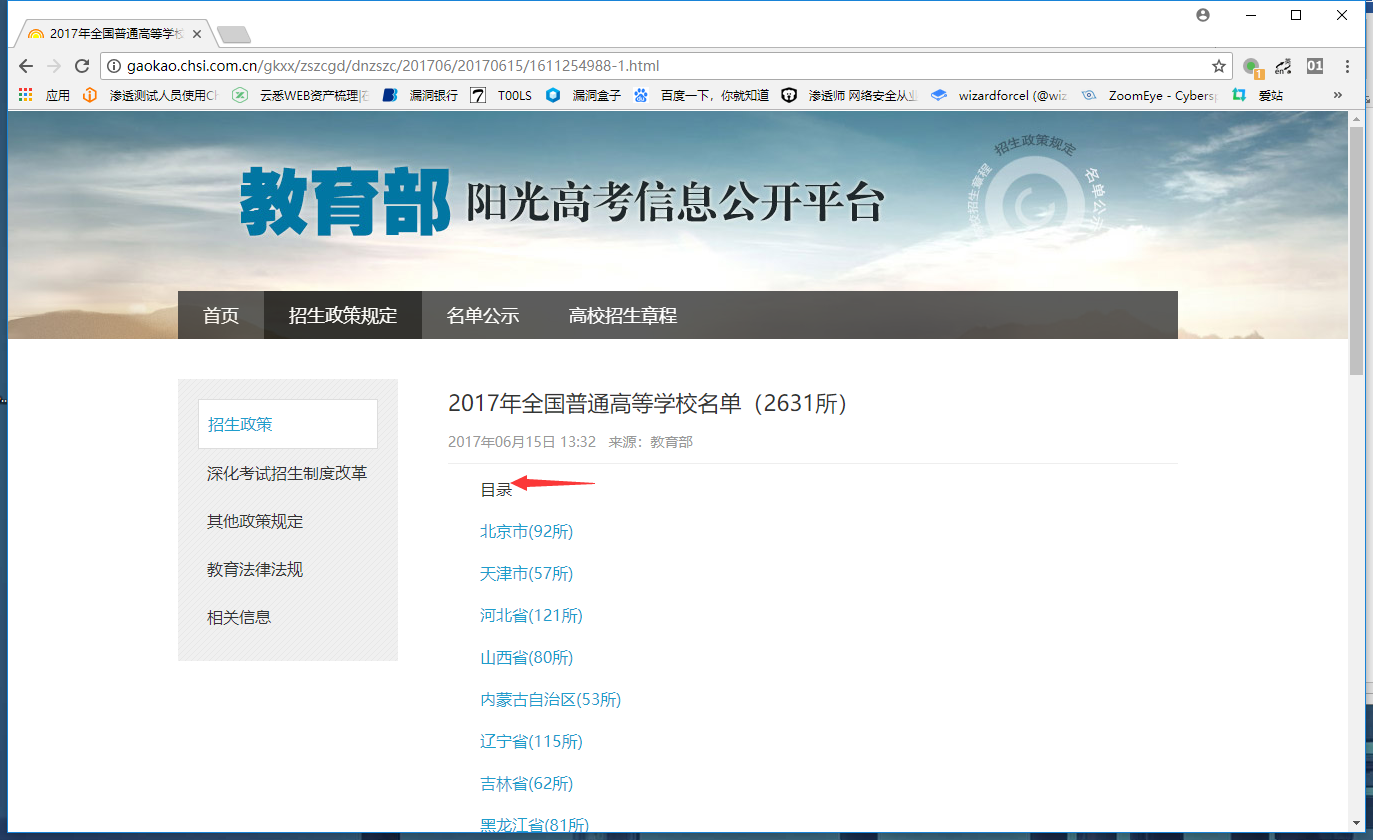
这里有一个目录:我们点击第一个北京市,就可以看到其中的表格,和北京市所有的大学名字
我们的目标就是吧每一个城市的所有大学,分别放在不同的txt文本中。
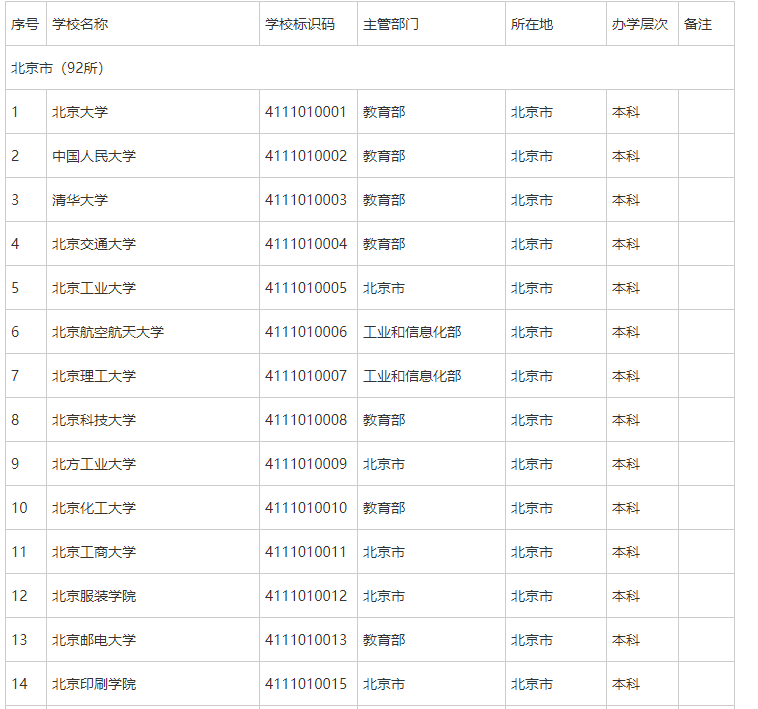
正式开始分析:
我们审查元素,我们要取的目标为学校名称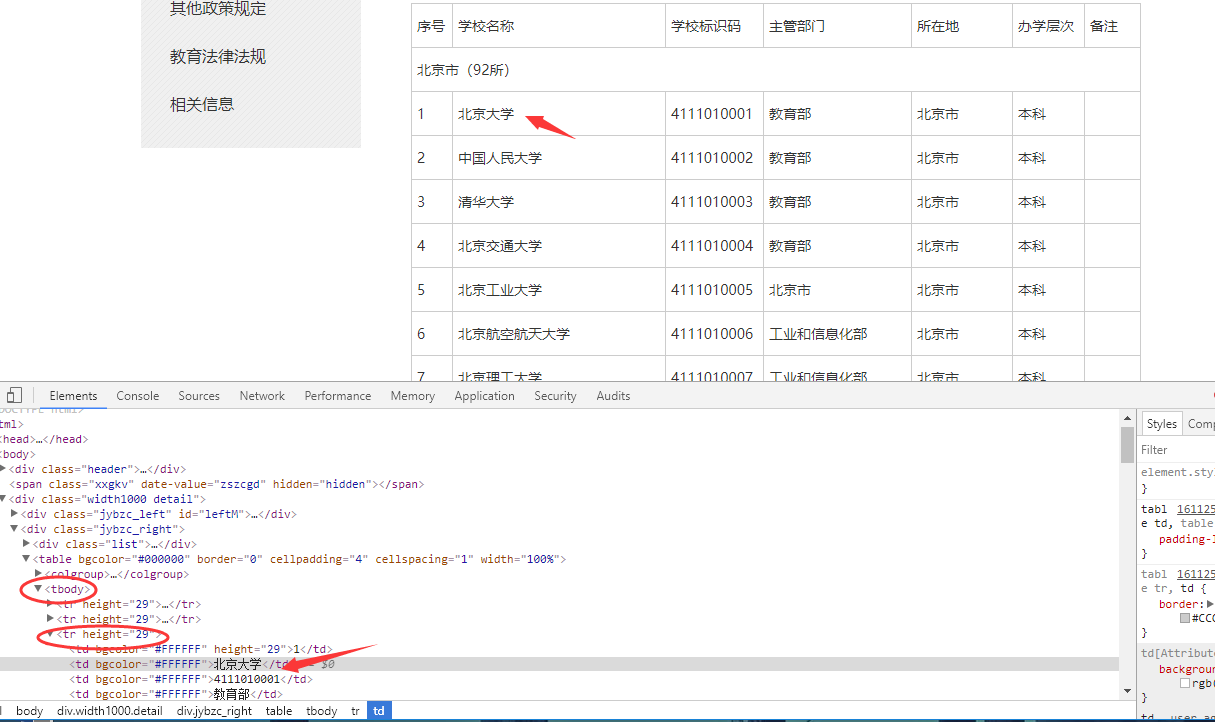
可以清晰的看到网页的结构,我们要取的目标在一个tbodyz中,并在一个tr标签内。继续分析下一个名字找到他们的规律
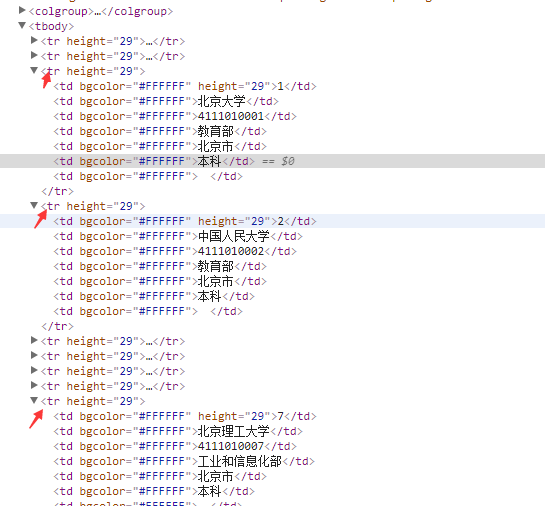
可以看到每个名字都在一个单独的tr标签中。
好我们在看一下这个北京市的url和第二个城市网页对应的url。
http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-2.html
http://gaokao.chsi.com.cn/gkxx/zszcgd/dnzszc/201706/20170615/1611254988-3.html
可以看到最后的数字不同,从二开始。依次增加。好我们已经基本获得了目标的信息,下面我们开始激动人心的敲代码。
我们先从一页开始。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









