









Stochastic Weight Averaging in PyTorch
SWA为什么有效
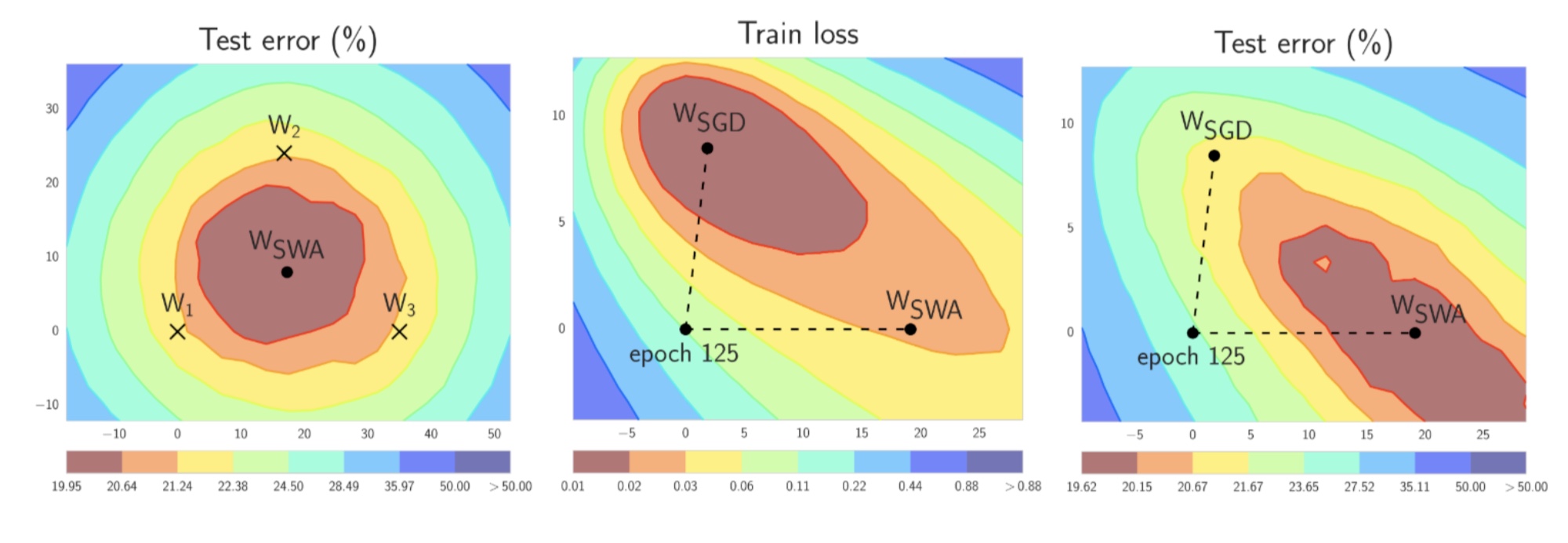
Figure 1. Illustrations of SWA and SGD with a Preactivation ResNet-164 on CIFAR-100 [1]. Left: test error surface for three FGE samples and the corresponding SWA solution (averaging in weight space). Middle and Right: test error and train loss surfaces showing the weights proposed by SGD (at convergence) and SWA, starting from the same initialization of SGD after 125 training epochs. Please see [1] for details on how these figures were constructed.
带有SWA的训练过程
自动模式
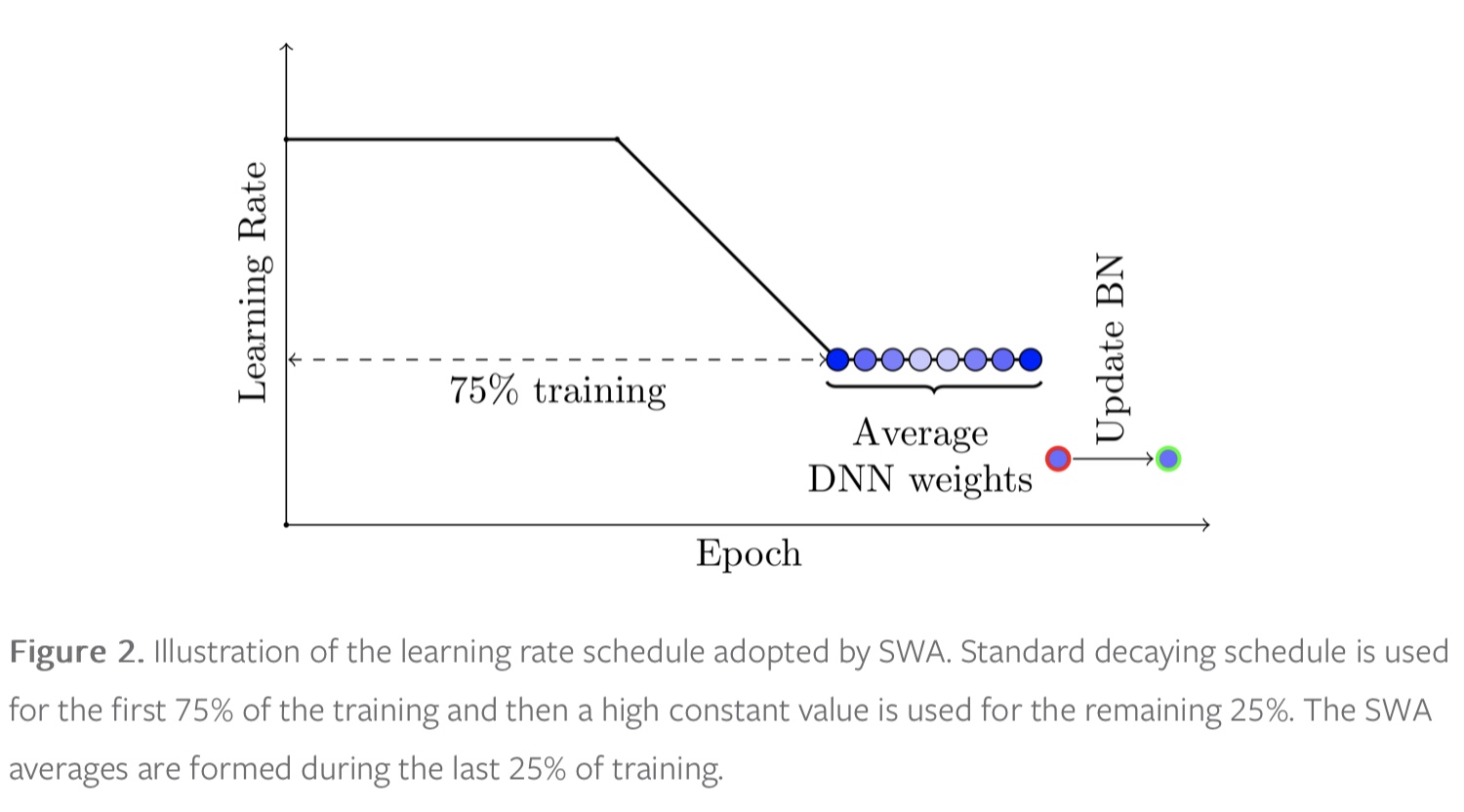
In our implementation the auto mode of the SWA optimizer allows us to run the procedure described above. To run SWA in auto mode you just need to wrap your optimizer base_opt of choice (can be SGD, Adam, or any other torch.optim.Optimizer ) with SWA(base_opt, swa_start, swa_freq, swa_lr) . After swa_start optimization steps the learning rate will be switched to a constant value, swa_lr (set to a reasonalby high constant value) , and in the end of every swa_freq optimization steps a snapshot of the weights will be added to the SWA running average. Once you run opt.swap_swa_sgd() , the weights of your model are replaced with their SWA running averages.
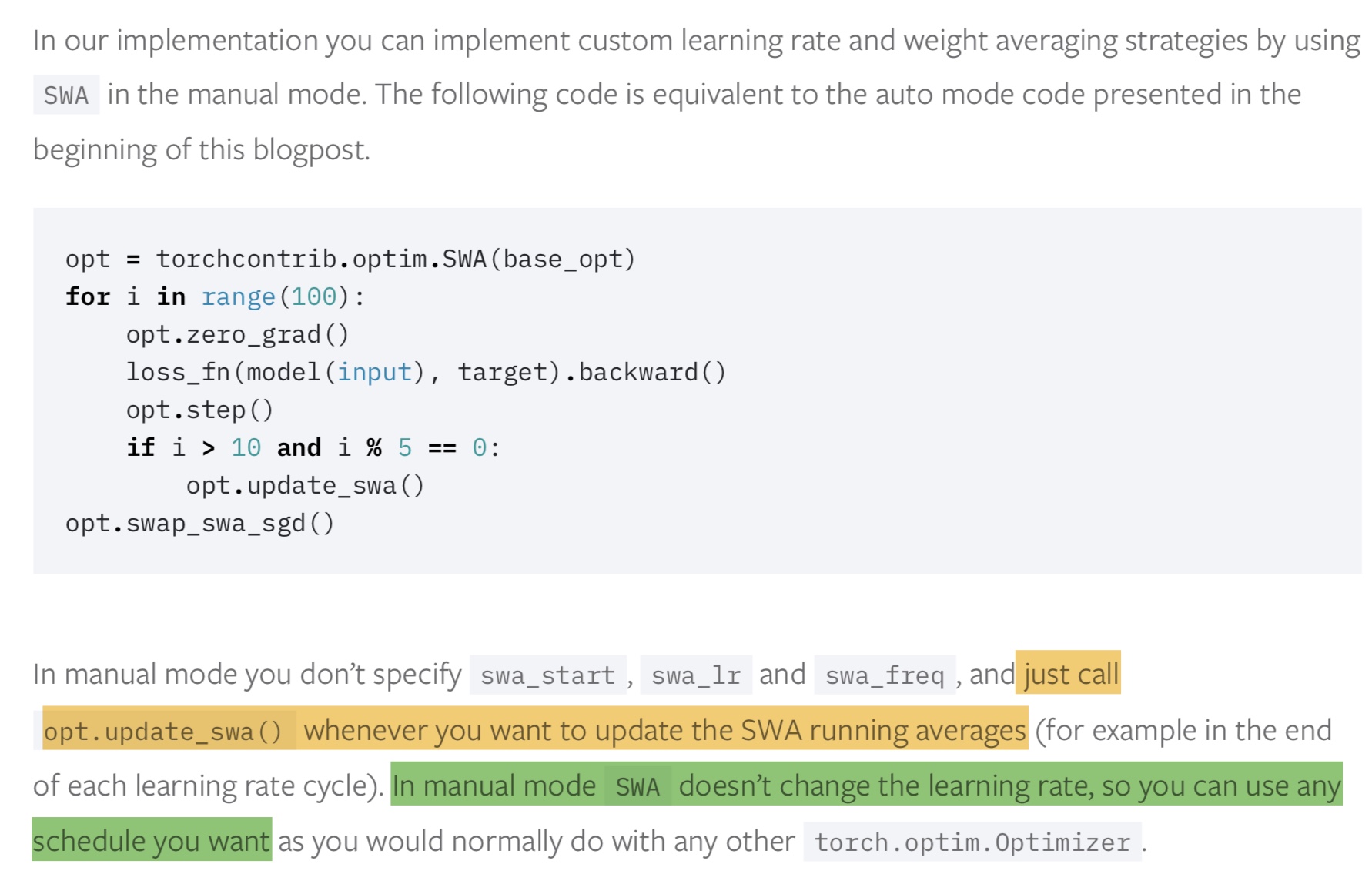
手动模式
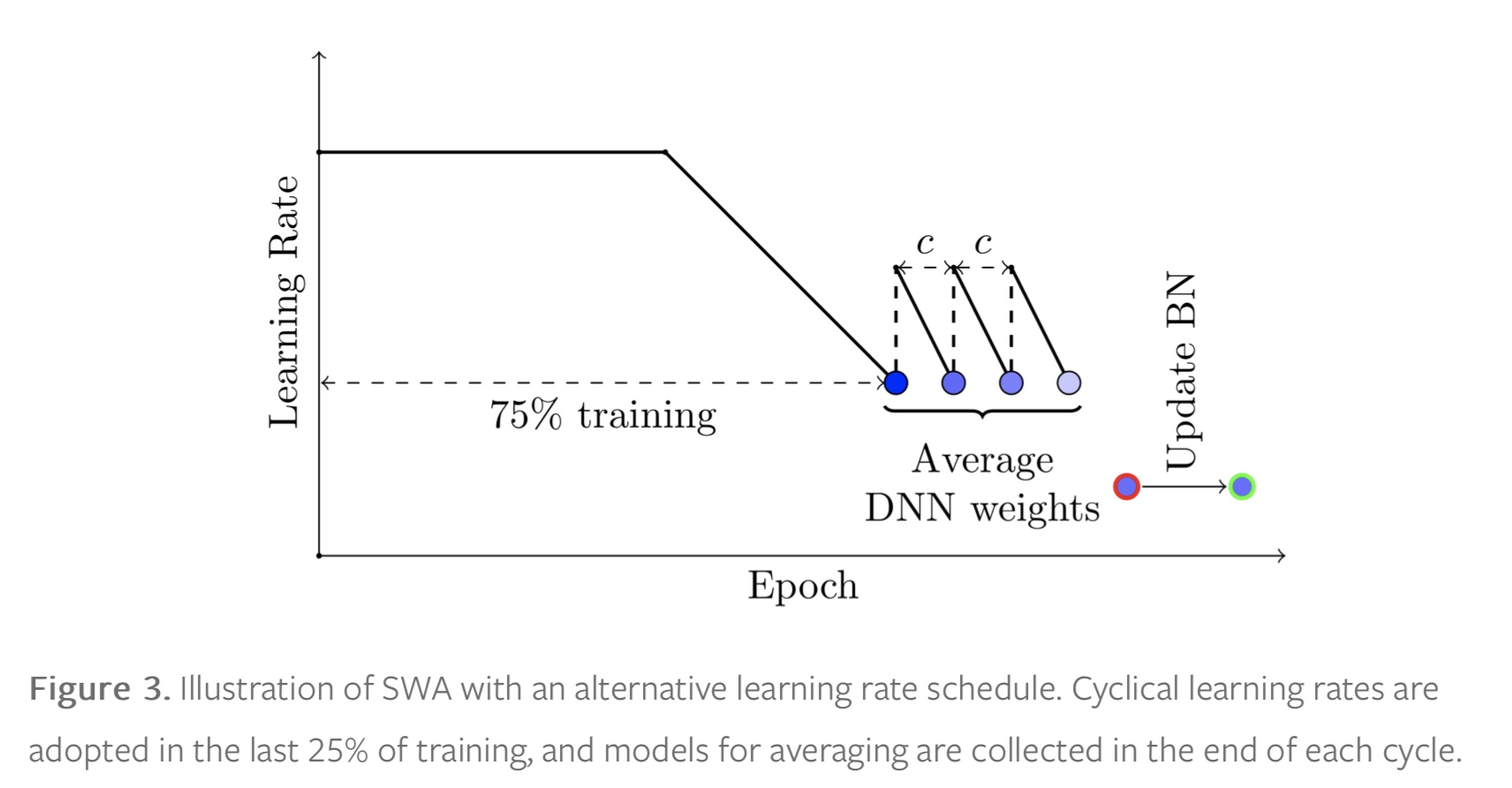
we can maintain a running average of the weights obtained in the end of every epoch within the last 25% of training time (see Figure 2).
BATCH NORMALIZATION层需要注意!!
















 1897
1897











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









