









解决问题
- 所有这些GAN变体都至少具有三个组成部分:生成器,鉴别器和编码器。 鉴别器和编码器具有相似的网络架构。 但是,随着训练过程的进行,大多数GAN中的生成器和编码器变得越来越完美,但鉴别器变得越来越原始。 换句话说,最优判别器在大多数情况下是原始且无用的。
- 我们能否在鉴别器和编码器之间共享权重?据我们所知,唯一成功做到这一点的是自省变分自动编码器(IntroVAEs,Huang等人(2018))。 但是IntroVAE非常复杂,我们很难重现其结果。
结果
- 在本文中,作者开发了一种非常简洁的方法来帮助普通GAN中的鉴别器成为编码器。 更具体地说,作者为普通GAN开发了一个额外的目标函数,并且因为有了这个额外的这个目标函数,鉴别器不仅可以区分输入图像是否真实,而且还具有为输入图像提取良好特征的能力。
- 我们进一步讨论了鉴别器的自由度,揭示了这种额外目标函数如何工作的原理。
实现方法
原始GAN:
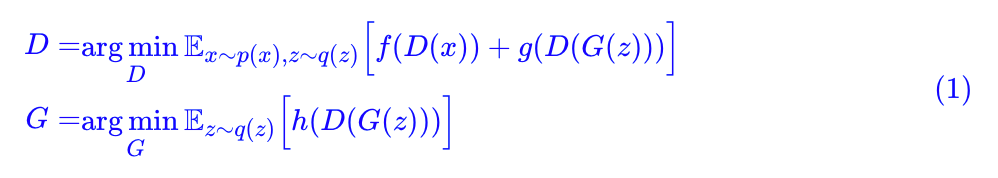
定义几个向量算符:
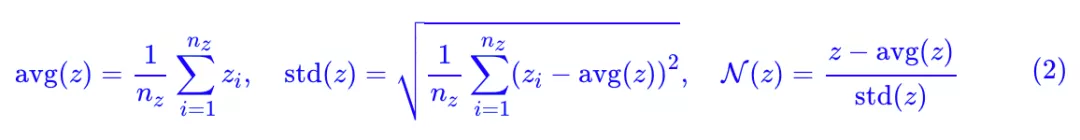
这些向量分别是各元素的均值、方差,以及标准化的向量。
当 nz≥3 时(真正有价值的 GAN 都满足这个条件),[avg(z),std(z),N(z)] 是函数无关的,也就是说它相当于是原来向量 z 的一个正交分解。
判别器的结构其实和编码器有点类似,只不过编码器输出一个向量而判别器输出一个标量罢了,那么我可以把判别器写成复合函数:

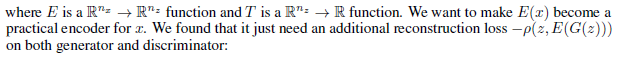
只需要加一个 loss即可实现让鉴别器变为编码器:Pearson 相关系数
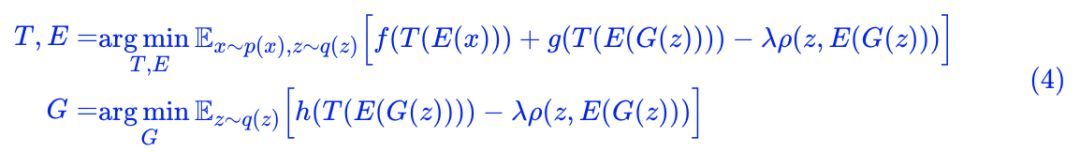
其中:
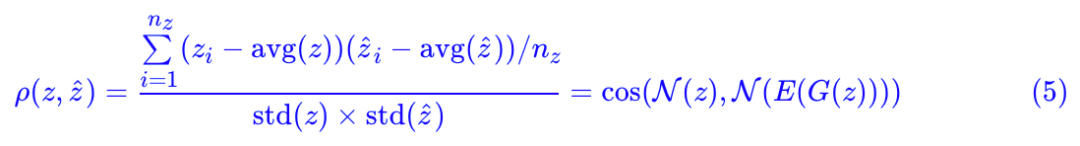
如果 λ=0,那么就是普通的 GAN 而已(只不过判别器被分解为两部分 E 和 T 两部分)。加上了这个相关系数,直观上来看,就是希望 z 和 E(G(z)) 越线性相关越好。为什么要这样加?我们留到最后讨论。
能不能把 T 也省掉?经过作者多次试验,结论是:还真能!因为我们可以直接用 avg(E(x)) 做判别器:
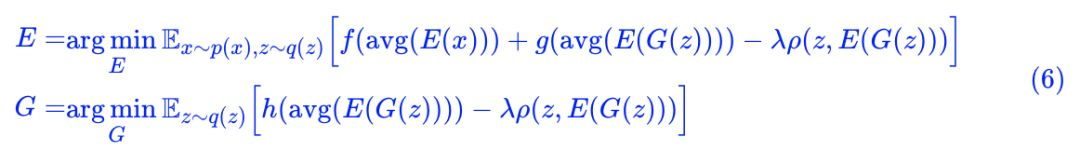
实验结果:
实验的目标主要有两个:1)这个额外的 loss 会不会有损原来生成模型的质量;2)这个额外的 loss 是不是真的可以让 E 变成一个有效的编码器?
CelebA HQ 随机生成结果

CelebA HQ重构效果:

CelebA HQ线性插值结果:

-
随机生成效果还不错,说明新引入的相关系数项没有降低生成质量;
-
重构效果还不错,说明 E(x) 确实提取到了 x 的主要特征;
-
线性插值效果还不错,说明 E(x) 确实学习到了接近线性可分的特征。
知乎讨论
匿名回答:个人理解,直接使用z-E(G(Z))有点cycleGAN的味道了,理论上如果G(z)的生成模式合理,是可以这么用的。但是好像GAN的一个问题就是直接用z有时候不合理,好像前些天是Facebook他们做的GAN,是把z经过一个网络映射W以后,然后输入生成器,这样提高了效率和性能,经过网络W映射后的z的分布更加合理,更适合直接进行latent domain的算术运算。所以感觉如果O-GAN中没有使用这个映射,那么z分布的合理性就可能不是很高,直接使用z-E(G(z))在训练的时候实际上等价于G,E双方分别要训练W和W^{-1},所要求的G,E匹配的条件太苛刻,这样训练难度可能就大了。或者说,E(G(z))是用来做分类的,而实际上在G的输入端,z的分布并不一定适合做分类,即我们直接对z做一个操作来完成对生成图像的分类可能是困难的,这时候要求z=E(G(z))就不合理了,因为z本身没有受到足够的约束,要求一个有强烈约束的E(G(z))与其相等是不恰当的。我们应该允许z和E(G(z))有对应关系但是这个对应可以更普遍更一般而不是严格要求相等。
作者在这里使用二者线性相关代替直接计算误差,应该是增加了一些自由度,增加了一个等价性或者叫gauge invariance,只要二者相关性足够好,那么也可以认为等价可接受,这样就降低了G,E要完美匹配(W,W(-1))的难度,变成了(W,UW{-1}),其中U是一个线性变换,就是这里的gauge transformation。我觉得实际上这个gauge group还可以扩大,比如扩大到Facebook他们做的那个对z的映射网络W,只要W不是过于chaotic,那么还是可以有好的对应关系,这时候代价函数可以是 W(z)-E(G(z))。题主使用的线性关系就是W的一个线性网络的特例。
原作答:
没错,你揭示了核心本质。
如果引入新参数矩阵W,那么我们可以直接去优化||z-W(E(G(z)))||^2,也就是说,虽然我们不能直接优化||z - E(G(z))||2,但是加入一个参数矩阵来控制自由度,那么用mse还是可以的,当然事后还要把W{-1}训练出来。这是我前一步的方案,o-gan就是在这个方案的基础上,进一步简化出来的。要说理由,还是洁癖吧…
至于z和E(G(z))匹配是否合理。从理论上其实应该是合理的,因为假设一个GAN训练得很理想,那么对于所有的真实图片,都应该有一个G(z)与之很接近,那么只需要找到对应的z=E(G(z))即可。实验上也表明了这一点。
很多重构GAN都用了||x-G(E(x))||^2作为辅助loss,但事实上,如果这个loss设置得不合理的话,某些图的重构上会模糊(比如CelebA HQ上,大部分人都没有帽子,如果有一个戴帽子的人来重构,帽子那部分就会模糊),但是匹配z和E(G(z))就不会,因为G、E压根都没有学习到帽子的特征,所以z不会有帽子的维度,在隐空间匹配与帽子没关系,这样学习出来的E(x)直接把帽子特征忽略掉了,然后G(E(x))就得到了一张没有帽子都也不会模糊的图片。
参考文献:
O-GAN:简单修改,让GAN的判别器变成一个编码器.
O-GAN Github 源码.
如何看待O-GAN(正交GAN)模型?.















 997
997











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









