






#小样本目标检测(Few-shot Object Detection)
paper: 2006.07502v2 (arxiv.org)
code: GitHub - ubc-vision/UniT
1.论文概括
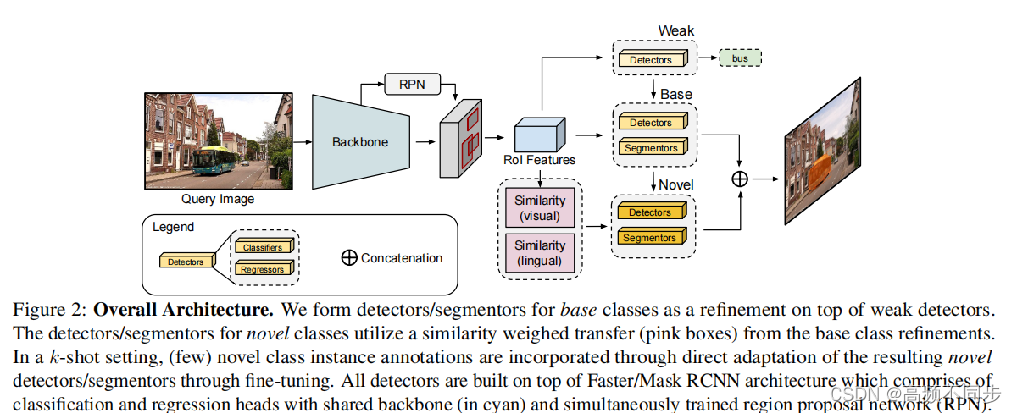
该论文提出了一个直观,统一的半监督(semi-supervised)模型,适用于任何样本量(any-shot,包括zero-shot和few-shot)的目标检测及分割。对于基类数据,模型学习从弱监督(weakly-supervised)到监督(fully-supervised)学习的映射。在新类学习时,利用新类和基类之间的视觉和语言相似度,迁移这些映射的内容到新类的检测器和分类器上。通过在MS-COCO和Pascal VOC数据集上的大量实验,验证了该方案的有效性。

2.主要方法
该方法是在Faster R-CNN检测框架下实现的,在基类训练时,同时采用了全监督(有instances标签)和弱监督(只有图像级标注)方法进行训练。在迁移到新类上,用多模态相似度(lingual+visual)将新类表示为其基类对应项的线性组合。
3.代码运行与解读
下载官方代码后,在本地运行调试了一下。考虑由于环境资源限制,在采用的win11运行代码,会导致部分错误发生(源码的环境应该是Linux)。记录一下代码运行时遇到的一些bug及解决方法。
UniT是在faster R-CNN的基础框架下实现,需要安装detectron2。在环境配置时需要参照detectron安装教程进行 (cuda,pytorch, python,vs的版本都要符合要求,不然在编译setup.py时会报错)。
安装detectron2教程: https://detectron2.readthedocs.io/en/latest/tutorials/install.html
这里我安装的环境版本是cuda11.1, pytorch1.9, python=3.9, vs2019 ,在配置好环境后还需要设置系统环境变量(PATH_HOME = cuda11.1,和cuda的环境变量保持一致)。
1.在配置好环境后,仍然报错:

参考https://github.com/Ikomiadev/detectron2/commit/cf546cfdae29b1f032f58a7d0340140443ee0603 的解决方案对setup.py进行修改,成功编译。
2. 安装 scikit-learn时如果发生报错,可以查看https://scikitlearn.org/stable/developers/advanced_installation.html 检查环境内的依赖项再进行安装。
3. 按readme准备好数据后,这里采用的是voc数据,运行train_VOC.py,出现以下错误:
ImportError: cannot import name 'FastRCNNOutputs' from 'detectron2.modeling.roi_heads.fast_rcnn'
发现仍然是detectron2的问题,最新版本的detectron2不包含’FasterRCNNOutputs'文件,需要更换成detectron2 v0.5版本。https://github.com/facebookresearch/detectron2
4. 再次运行train_VOC.py,出现错误:
AttributeError: module 'PIL.Image' has no attribute 'LINEAR'
这个应该是PIL版本的问题,修改LINEAR为BILINEAR解决该问题
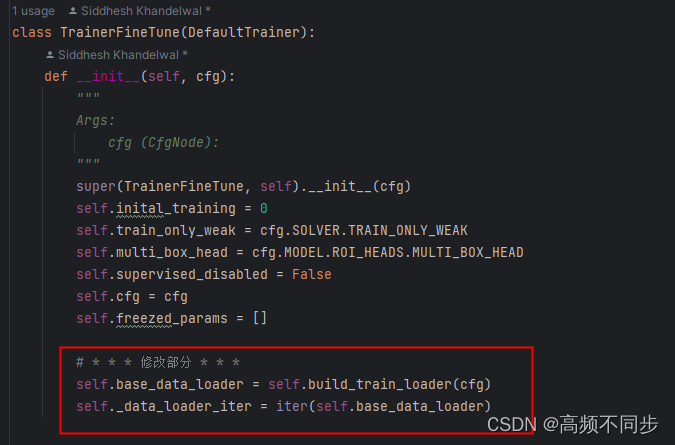
5. 再再次运行train_VOC.py,出现错误:
self._data_loader_iter has not attribute TrainerNoMeta,类似的错误还有 self._detect_anomaly / self._write_metrics has not attribute TrainerNoMeta
后面检查代码发现,应该是detectron2.engine.train_loop中的SampleTrainer在类的函数没有继承到 TrainerNoMeta。在default/engine文件做如下修改:
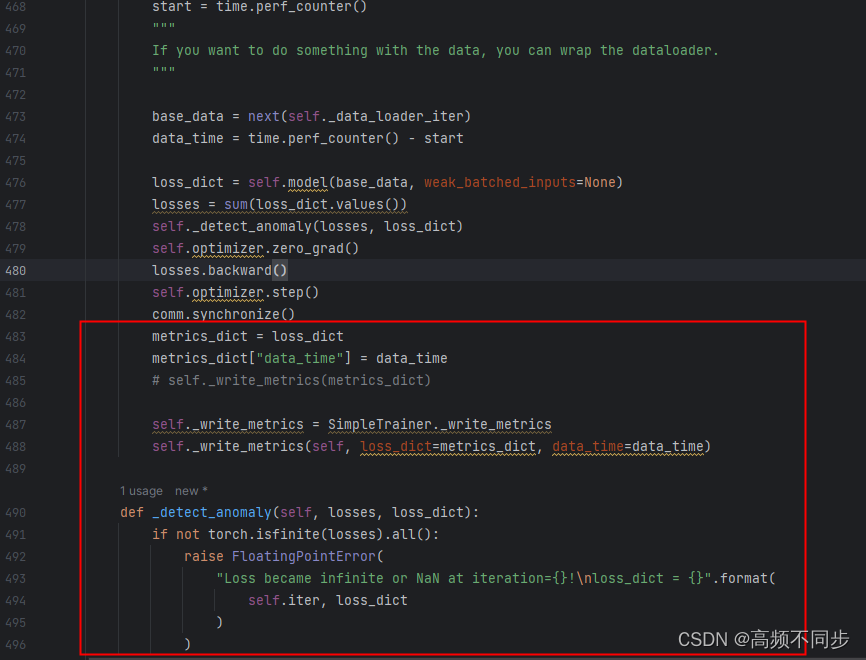
6. 运行train_VOC.py,终于终于可以正常运行了,but,用3060跑的速度真的很慢,很慢.....
在跑通了代码后,通过debug进一步理解文章实现的思路,总结如下:
在基类数据训练时,从base数据集中分别选取instances annotation和image-level annotation作为训练数据,通过结合若监督和全监督训练来优化网络结构。

在finetuning阶段,从base和novel数据集中共选取N-way K-shot的数据,进行训练,对roi head输出的box feature计算lingual和visual相似度,利用相似度的输出和原本的box feature共同计算cls和box预测值。
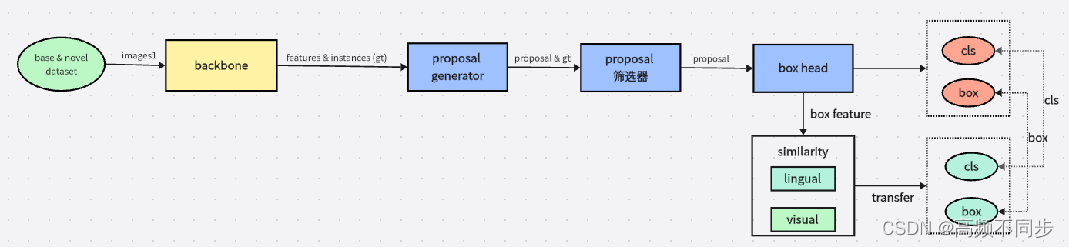

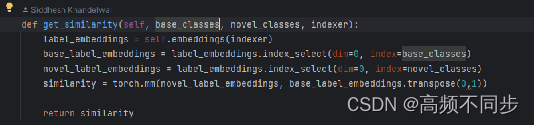
具体的,lingual相似度通过一个预训练好的网络作为embeddingNet(源码应该是基于coco数据集训练好的),利用矩阵相乘的方法计算base和novel类别相似度。

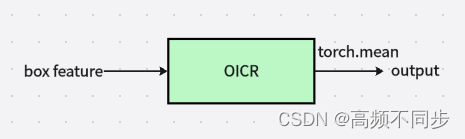
visual相似度则是参考OICR(三层线性全连接层)进一步提取novel和base的visual相似度。

















 1884
1884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









