









前两天,群里小伙伴问了一个问题:

不是说snappy压缩不支持split嘛,为什么我改小mapred.max.split.size一倍之后,mapper数翻倍?
一直以来大家都知道snappy是不支持切分的,但是在测试时,又发现在某些情况下,貌似支持切分,这让人很疑惑... ...
关于snappy压缩,在网上大家的说法也不是很统一,有人说不支持split,有人说支持:



凡是稍微有点深度的有问题,从网上求答案,真的是太难了......
这篇从群里小伙伴的这个问题出发,分析一下有关snappy压缩的一些事情及spark 在处理这一块的源码层面分析。
先给结论
1、snappy压缩格式本身是不可切分的;
2、snappy压缩格式作用在文本类文件格式上不可切分;
3、snappy压缩格式作用在Sequence、Avro、parquet、orc等这些容器类的文件格式上,能够支持切分。但这里的切分并不是因为snappy变的可切分了,而是因为这些容器类的文件格式牛逼~~
再理解一遍啥是可切分?啥是不可切分?原因是啥?
可切分:是否可以搜索数据流的任意位置并进一步往下读取数据。
啥意思?
1、假设有一个1GB的不压缩的文本文件,如果HDFS的块大小为128M,那么该文件将被存储在8个块中,把这个文件作为输入数据的MapReduc/Spark作业,将创建8个map/task任务,其中每个数据块对应一个任务作为输入数据。
对于不压缩的文本文件来说,是可切分,因为每个block都存了完整的数据信息,读取的时候可以按照规定的方式去读:比如按行读。
2、假如一个文本文件经过snappy压缩后,文件大小为1GB。与之前一样,HDFS也是将这个文件存储成8个数据块。但是每个单独的map/task任务将无法独立于其他任务进行数据处理,官方一点的说法,原因就是压缩算法无法从任意位置进行读取。
通俗的讲解,就是因为存储在HDFS的每个块都不是完整的文件,我们可以把一个完整的文件认为是具有首尾标识的,因为被切分了,所以每个数据块有些有头标示,有些有尾标示,有些头尾标示都没有,所以就不能多任务来并行对这个文件进行处理。
粗暴点来讲,就是因为经过snappy压缩后的文本文件不是按行存了,但是又没有相关的结构能记录数据在每个block里是怎么存储的,每行的起止位置在哪儿,所以只有将该文件的所有HDFS的数据块都传输到一个map/task任务来进行处理,但是大多数数据块都没有存储在这个任务的节点上,所以需要跨节点传输,且不能并行处理,因此运行的时间可能很长。
总结:决定可不可分,主要是看能不能有个清晰的规则支持从任意位置读数据,对于文本文件来说,按行读,哪怕两个map task来读同一个block,只要按照定好的规则也是能读的,不会发生错乱。
而一些不可切分的压缩算法,做不到这点(当然,如果你能给开发个对应的规则去读,也是可以的,哈哈,但是这个很难吧,要不然也不会说是不可切分了)
文件的存储格式和压缩格式的关系
存储格式:text、Sequence、Avro、parquet、orc等
压缩格式:Gzip、snappy、lzo、lz4、zlib等
压缩格式并不是一种文件格式,我们可以认为他是一种算法
一个orc格式的文件,可以用zlib压缩算法来压缩、也可以用snappy压缩算法来压缩,用完这些压缩算法后,该文件还是orc格式
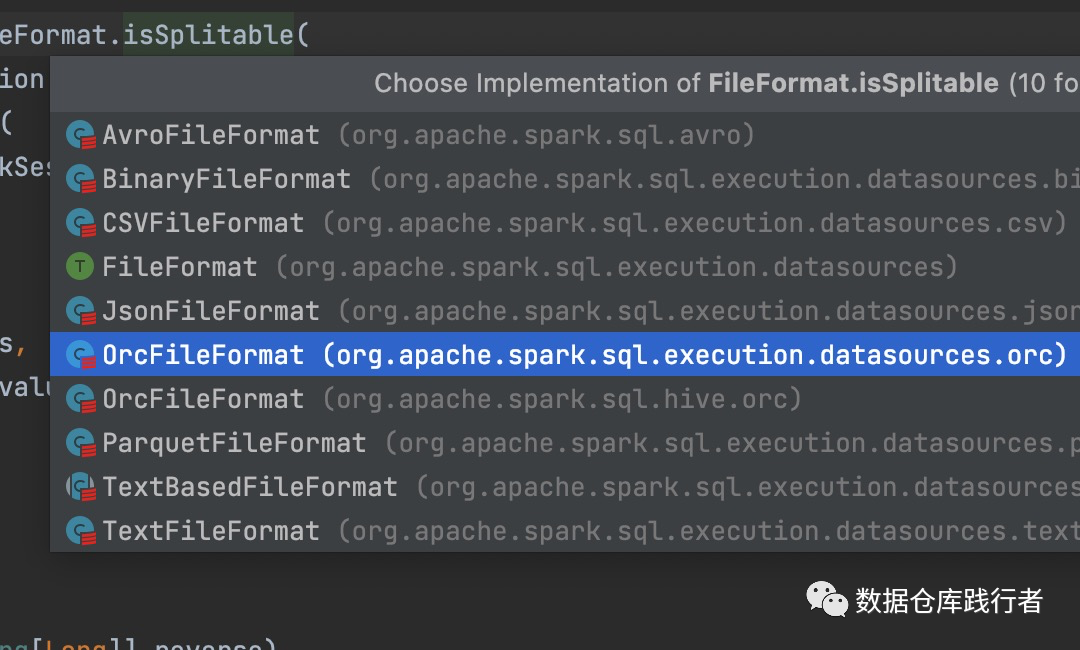
从spark源码中看,文件格式的实现类是上面几种,没有见有snappy、zlib文件格式的。所以说,这一点一定要分清。
以orc为例分析snappy是怎么作用到容器类的文件格式上的
orc文件格式本身可切分的
orc虽然是二进制存储,但因为orc中提供了各种索引,使得在读取数据时支持从指定任意一行开始读取,所以,orc是切分的。
文件压缩
在orc格式的hive表中,记录首先会被横向的切分为多个stripes,然后在每一个stripe内数据以列为单位进行存储。

条带( stripe):ORC文件存储数据的地方,每个stripe一般为HDFS的块大小,包含以下3部分:
-
index data:保存了所在条带的一些统计信息,以及数据在 stripe中的位置索引信息。
-
row data:数据存储的地方,由多个行组构成,每10000行构成一个行组,数据以流( stream)的形式进行存储。
-
Stripe Footer:保存数据所在的文件目录
文件脚注( File Footer):包含了文件中stripe的列表,每个 stripe的行数,以及每个列的数据类型。它还包含每个列的最小值、最大值、行计数、求和等聚合信息。
Postscript:含有压缩参数和压缩大小相关的信息
而orc在压缩时,压缩算法起作用的地方是数据流,也就是上图右侧的红色圈出的部分:
orc文件使用两级压缩机制,首先将一个数据流使用流式编码器进行编码,然后使用一个可选的压缩器(snappy or zlib)对数据流进行进一步压缩。
也就是说,snappy作用的地方是stripe里的row data部分。
两个位置
当读取一个orc文件时,orc reader需要有两个位置信息就可准确的进行数据读取操作:
-
metadata streams和data stream中每个行组的开始位置
由于每个stripe中有多个行组,orc reader需要知道每个group的metadata streams和data stream的开始位置。而这些信息存储在index data里,index data并没有被snappy压缩
-
stripes的开始位置
由于一个orc文件可以包含多个stripes,并且一个hdfs block也能包含多个stripes。为了快速定位指定stripe的位置,需要知道每个stripe的开始位置。而这些信息主要保存在orc file的 File Footer中。File Footer也没有被snappy压缩
综上,我们知道orc使用snappy压缩后,索引信息还在,这就使得在压缩后,仍然能支持从指定任意一行开始读取。
spark 层面的源码分析
spark 通过FileSourceScanExec 来处理hdfs文件:

找到判断文件是否可切分的逻辑
我们重点看一下OrcFileFormat 和 TextFileFormat部分的实现:
OrcFileFormat:
返回true,默认可切分
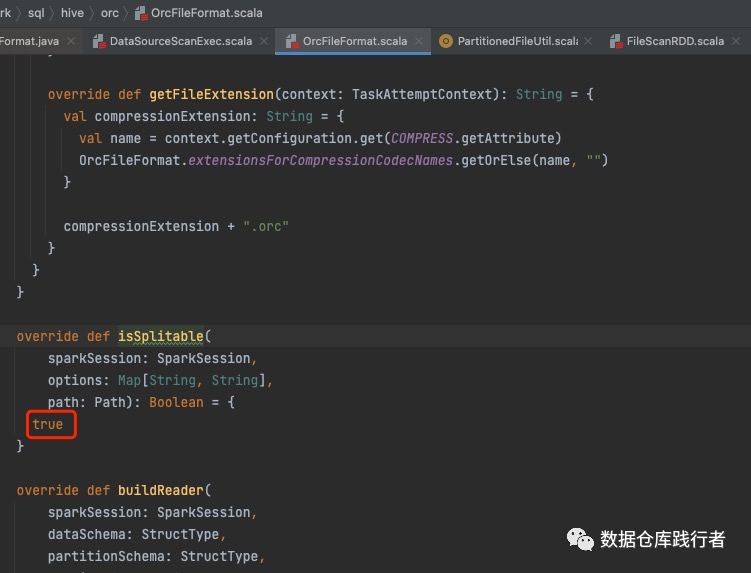
TextFileFormat:
先给结论:
1、没有做【把整个文件当成一行来读】这样的配制
2、没有压缩或者如果压缩了,压缩的算法必须是SplittableCompressionCodecr的子类
满足上面两个条件,该文件才可切分。
而snappy的压缩是没有继承SplittableCompressionCodecr的,所以用snappy的算法来压缩文本文件,是不可切分的。

TextFileFormat的父类是TextBasedFileFormat:

不知道是不是说清晰了呢?欢迎一起讨论
另,搜索数仓团队正在火热招人,北京上海都有岗位,有需要的可戳 搜索数仓招聘啦,也可微信私聊,看简历
Hey!
我是小萝卜算子
欢迎关注:数据仓库践行者
分享是最好的学习,这里记录我对数据仓库的实践的思考和总结
每天学习一点点
知识增加一点点
思考深入一点点
在成为最厉害最厉害最厉害的道路上
很高兴认识你
推荐阅读















 84
84











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











