







 本文深入探讨SparkSQL如何通过源码解析`show create table`命令,了解其与Hive元数据库的交互,解析表的metadata,并呈现最终结果。文章通过模拟测试类、分析实体类与元数据表的关系,以及详细步骤,揭示了执行过程中的核心方法。适合对SparkSQL源码感兴趣的技术人员阅读。
本文深入探讨SparkSQL如何通过源码解析`show create table`命令,了解其与Hive元数据库的交互,解析表的metadata,并呈现最终结果。文章通过模拟测试类、分析实体类与元数据表的关系,以及详细步骤,揭示了执行过程中的核心方法。适合对SparkSQL源码感兴趣的技术人员阅读。
这篇文章主要介绍了show create table命令执行的源码流程,弄清楚了sparksql是怎么和hive元数据库交互,查询对应表的metadata,然后拼接成最终的结果展示给用户的。
如果你正好也想了解这块,就点赞、收藏吧~
今天这篇文章也是来自于【源码共读群】的一个讨论,先上聊天:
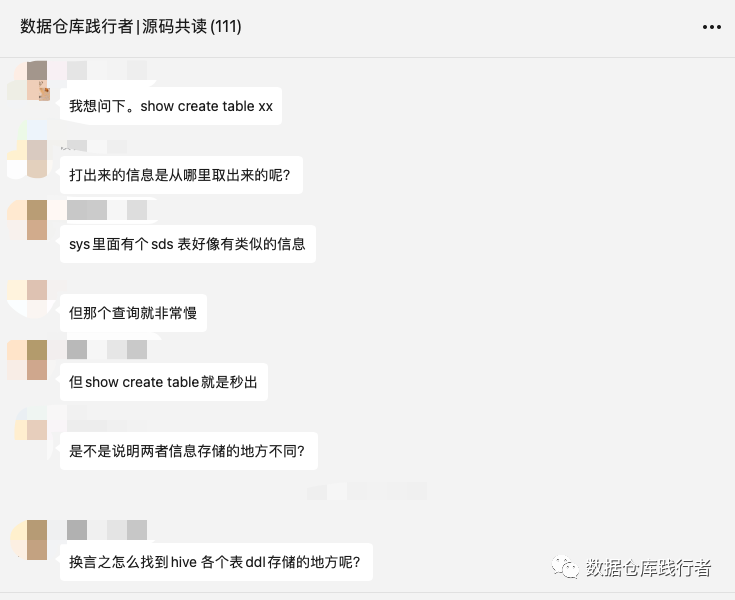
我们平时都很关注select这样的查询语句,却很少关注show create table 这样的语句的执行过程,在网上确实也很难搜到写相关内容的博客。正好借这个问题,深挖一下运行原理,于是,花2个小时,撸一遍源码,得到了基本的结论:
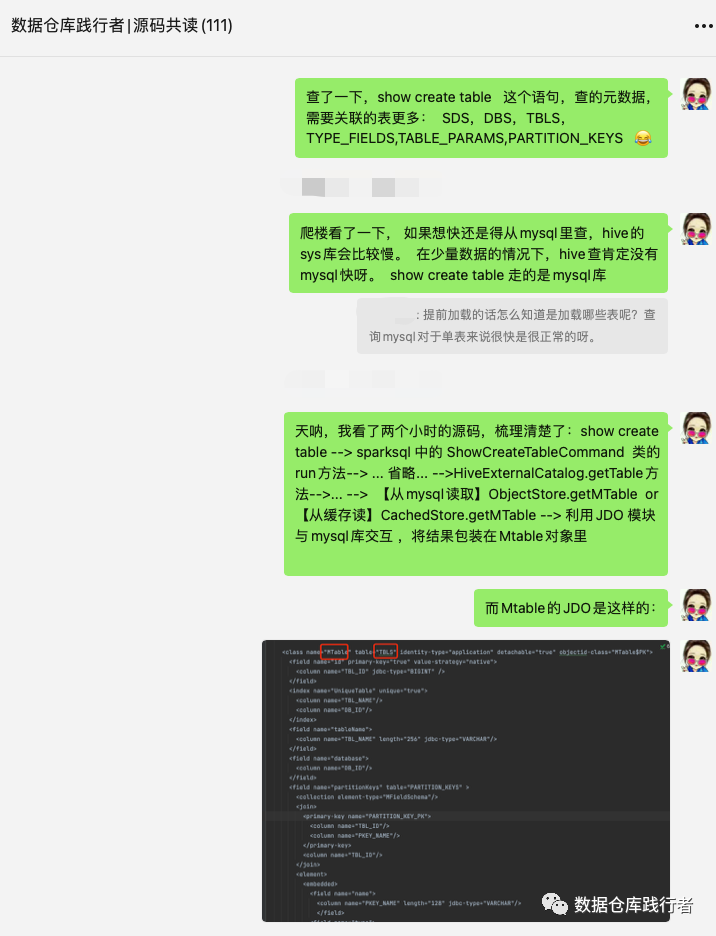
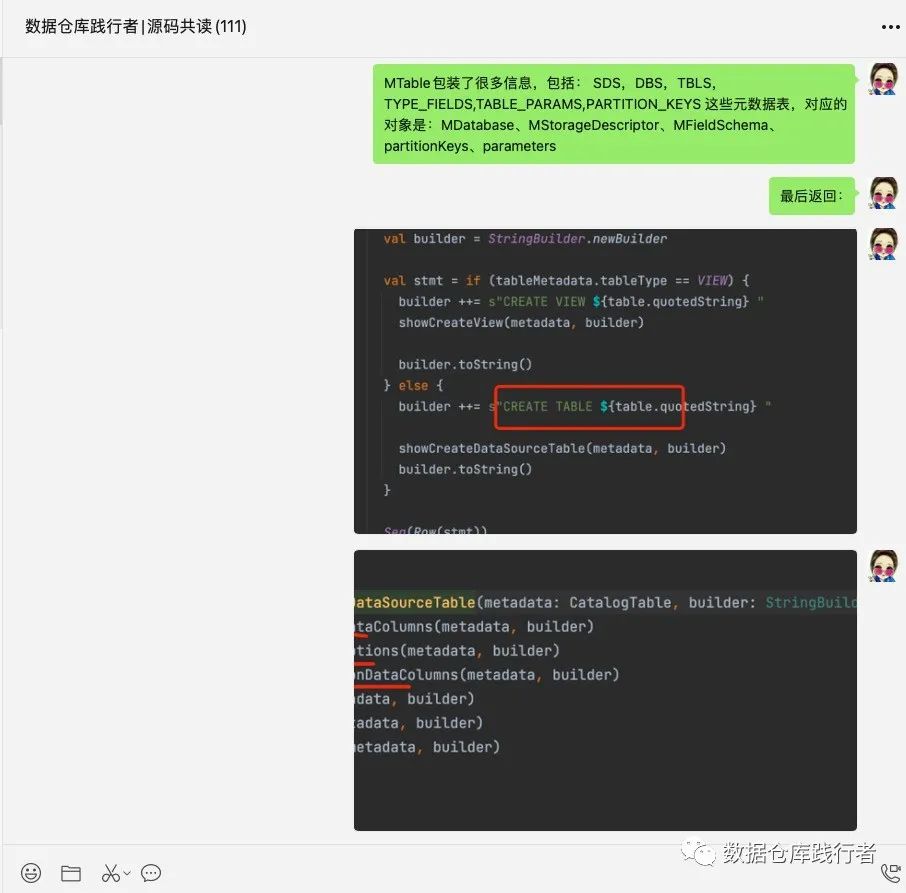
哈哈,感谢大家认可啦,群友都希望录个视频,那我先写文章,然后,再录个短屏。
下面开挖,源码是枯燥的,但也是我们能看到真相的窗口~~
本文基于spark 3.2
本文大纲
1、写能模拟从hive查表的本地测试类
2、hive中的实体类和元数据库表及字段的对应关系
3、源码分析执行过程

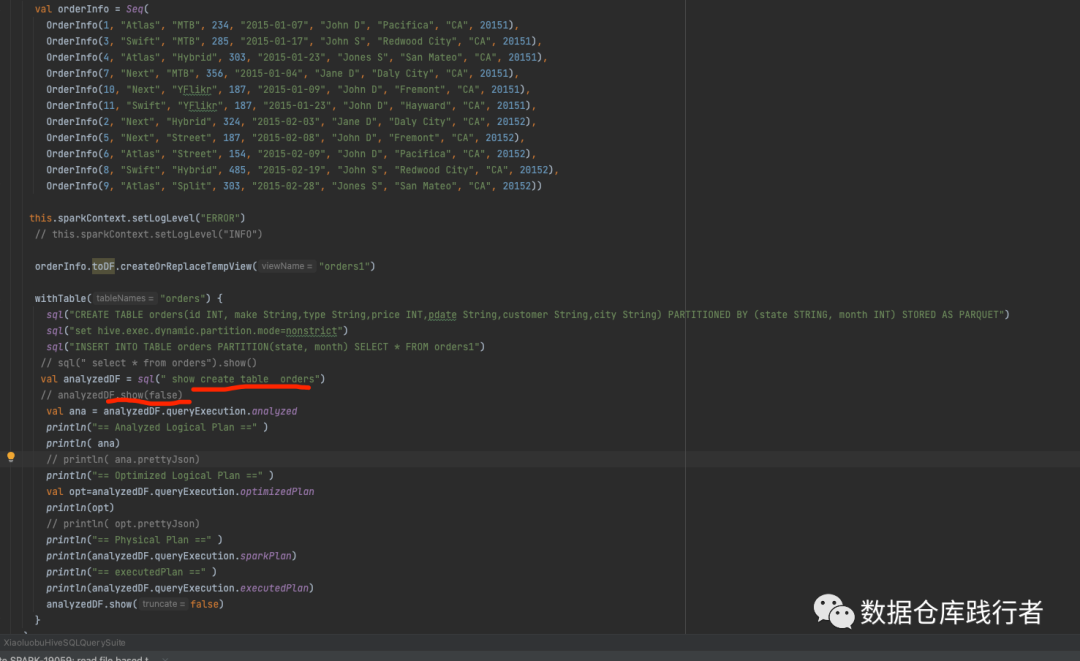
1、写能模拟从hive查表的本地测试类
我们在读sparksql源码时,为了方便,基本上都是用df.createOrReplaceTempView("XXX")这样的形式,来产生一些数据,这些足够我们去研究90%以上的规则,但这些不能模拟hive的情况,如果我们搭建远程连hive的环境,又会花费大量的精力。
还好,在sparksql源码工程里,我们可以通过继承TestHiveSingleton,在不用搭建hive环境的情况下,来模拟hive。
这个在【源码共读】的分享上我们会专门讲~~
测试类代码如下:
2、hive中的实体类和元数据库表及字段的对应关系
MTable(类)--> TBLS(表)
MDatabase(类)-->DBS(表)
MStorageDescriptor(类)-->SDS(表)
MFieldSchema(类)-->TYPE_FIELDS(表)
partitionKeys(MTable类中的filed) -->PARTITION_KEYS(表)
parameters (MTable类中的filed--> TABLE_PARAMS(表)
下面的配制包含了类中的字段及表字段的对应关系:
<class name="MTable&# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











