







这次是分享一个多维分析优化的案例
【本文大纲】
-
业务背景
-
spark sql处理count distinct的原理
-
spark sql 处理 grouping sets的原理
-
优化过程及效果
-
总结
1、业务背景
先上sql:
select
if(req_netease_user is null, 'all', req_netease_user) as netease_user,
if(campaign_id is null, 'all', campaign_id) as campaign_id,
if(spec_id is null, 'all', spec_id) as spec_id,
if(app_bundle is null, 'all', app_bundle) as app_bundle,
if(render_name is null,'all', render_name) as render_name,
if(platform is null, 'all', platform) as platform,
count(distinct request_id) as bid_request_num,
count(distinct deviceid) as bid_request_uv,
count(distinct case when bid_response_nbr=10001 then bid_response_id else null end) as offer_num,
count(distinct case when bid_response_nbr=10001 then deviceid else null end) as offer_uv,
dt
from
(
select
distinct dt,
if(req_netease_user is null, 'null', req_netease_user) as req_netease_user,
if(render_name is null, 'null', render_name) as render_name,
if(platform is null,'null', platform) as platform,
if(campaign_id is null, 'null', campaign_id) as campaign_id,
if(spec_id is null, 'null', spec_id) as spec_id,
if(app_bundle is null, 'null', app_bundle) as app_bundle,
request_id,
bid_response_nbr,
bid_response_id,
deviceid
from table_a where dt = '2019-08-11' and request_id is not null
) tmp group by dt, req_netease_user, campaign_id, spec_id, app_bundle, render_name, platform
grouping sets(
(dt),
(dt, req_netease_user),
(dt, campaign_id),
(dt, spec_id),
(dt, app_bundle),
(dt, render_name),
(dt, platform),
(dt, req_netease_user, campaign_id),
(dt, req_netease_user, spec_id),
(dt, req_netease_user, app_bundle),
(dt, req_netease_user, render_name),
(dt, req_netease_user, platform),
(dt, req_netease_user, campaign_id, spec_id),
(dt, req_netease_user, campaign_id, app_bundle),
(dt, req_netease_user, campaign_id, render_name),
(dt, req_netease_user, campaign_id, platform),
(dt, req_netease_user, campaign_id, spec_id, app_bundle),
(dt, req_netease_user, campaign_id, spec_id, render_name),
(dt, req_netease_user, campaign_id, spec_id, platform),
(dt, req_netease_user, campaign_id, spec_id, app_bundle, render_name),
(dt, req_netease_user, campaign_id, spec_id, app_bundle, platform),
(dt, req_netease_user, campaign_id, spec_id, app_bundle, render_name, platform)
)逻辑不复杂,就是慢,运行时间如下:

要运行5个小时~~~
这是一张广告竞价的业务表,每一条请求 request_id 都会产生一条数据,一天下来,数据量是很大的(几十亿)。 然而,又要对 7个维度做成22个组合,分别求 count(distinct request_id) , count(distinct deviceid), count(distinct case when bid_response_nbr=10001 then bid_response_id else null end) ,count(distinct case when bid_response_nbr=10001 then deviceid else null end) 。 只能说,需求好无耻啊 啊 啊 啊
2、spark sql对count distinct做的优化
在 hive 中我们对count distinct 的优化往往是这样的:
--优化前
select count(distinct id) from table_a
--优化后
select
count(id)
from
(
select
id
from table_a group by id
) tmphive往往只用一个 reduce 来处理全局聚合函数,最后导致数据倾斜;在不考虑其它因素的情况下,我们的优化方案是先 group by 再 count 。
在使用spark sql 时,貌似不用担心这个问题,因为 spark 对count distinct 做了优化:
explain
select
count(distinct id),
count(distinct name)
from table_a执行计划如下:
== Physical Plan ==
*(3) HashAggregate(keys=[], functions=[count(if ((gid#147005 = 2)) table_a.`id`#147007 else null), count(if ((gid#147005 = 1)) table_a.`name`#147006 else null)])
+- Exchange SinglePartition
+- *(2) HashAggregate(keys=[], functions=[partial_count(if ((gid#147005 = 2)) table_a.`id`#147007 else null), partial_count(if ((gid#147005 = 1)) table_a.`name`#147006 else null)])
+- *(2) HashAggregate(keys=[table_a.`name`#147006, table_a.`id`#147007, gid#147005], functions=[])
+- Exchange(coordinator id: 387101114) hashpartitioning(table_a.`name`#147006, table_a.`id`#147007, gid#147005, 4096), coordinator[target post-shuffle partition size: 67108864]
+- *(1) HashAggregate(keys=[table_a.`name`#147006, table_a.`id`#147007, gid#147005], functions=[])
+- *(1) Expand [List(name#146984, null, 1), List(null, id#146979, 2)], [table_a.`name`#147006, table_a.`id`#147007, gid#147005]
+- *(1) Project [id#146979, name#146984]
+- *(1) FileScan parquet table_a
从执行计划中可以看到,在处理 count distinct 时,用 Expand 的方式,具体是怎么 expand 的呢,如下图:
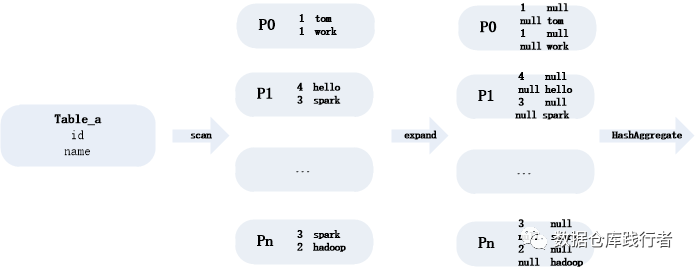
expand 之后,再以id、name 为 key 进行HashAggregate 也就是 group by ,这样以来,就相当于去重了。后面直接计算count (id) 、 count(name) 就可以,把数据分而治之。 在一定程度上缓解了数据倾斜。
顺便附上 distinct 这块的部分代码,方便做对照理解:
def rewrite(a: Aggregate): Aggregate = {
// 把所有聚合表式取出来
val aggExpressions = a.aggregateExpressio 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 481
481











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











