







- ArrayList, 基于可变数组的
| 值 | 10 | 15 | 20 | 25 | 30 |
|---|---|---|---|---|---|
| 下标 | 0 | 1 | 2 | 3 | 4 |
优点:根据下标的检索速度非常快
缺点:插入和删除元素的时候比较慢,需要比较大的连续的内存空间
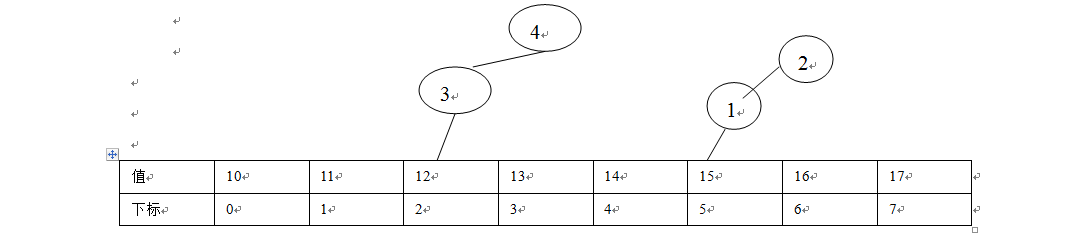
根据下标检索比较快的原因,因为数组的地址分配是连续的,数组中的元素类型是一致的,所以每个元素的长度是一致的,如果我们的数组是int类型的数组,那么每个元素的字节长度为4个,如果想得到下标3对应的值,使用比较简单的四则运算就可以了:
开始位置+(下标*元素长度),下标3的值为:开始位置+(3*4),然后再读取4个字节就可以了
插入和删除比较慢的原因:因为插入和删除会带来元素的移动
| 值 | 10 | 15 | 20 | 25 | 30 |
|---|---|---|---|---|---|
| 下标 | 0 | 1 | 2 | 3 | 4 |
如果根据数组中的值进行检索,我们一般使用二分法(折半法)
- LinkedList, 基于链表
优点:插入和删除比较快,因为不会带来元素的移动,只需要改变指针的位置就可以了
缺点:检索速度比较慢,因为存储不连续(没有规律可寻)
- 散列表(哈希表),HashSet、HashMap(HashSet底层采用了HashMap,主要采用HashMap的key),散列表存取速度比较快,散列表一般基于数组实现的,我们可以看做一个有规则的数组就是一个散列表(下标和值有对应)
- 以上下标和值存在规则,以上数组可以看做是一个散列表,规则如下:
元素的下标=元素值-10,此时换算出来的下标值我们可以称为hashCode,取得hashCode的方法如下:

public int hashCode(int value) {
return value -10;
}HashCode相等不代表对象equals相等
生成规则:
equals相等hashCode必须相等
equals不相等,hashcode不要求不相等(理想情况下最好是不相等)
哈希冲突(哈希碰撞)
6. 当遍历一个比较大的集合的时候,最好看看,有没有规律可寻,尽量不要从头到尾线性比较
7. 关于这个几个集合可以统一使用迭代模式完成遍历,迭代模式可以隐藏数据遍历的细节
8. 集合主要体现了策略模式和迭代模式
(想了解ArrayList、Vector、HashMap、HashTable是如何扩容的请看本博客其他文章)















 592
592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









