







HashMap
HashMap是基于Hashing(哈希)原理,通过put()和get()方法来存储和获取对象。
HashMap的来源:
数组的特点是:寻址容易,插入和删除困难;
而链表的特点是:寻址困难,插入和删除容易。
那么我们能不能综合两者的特性,做出一种寻址容易,插入删除也容易的数据结构?HashMap应运而生。HashMap的实现方式如下图:
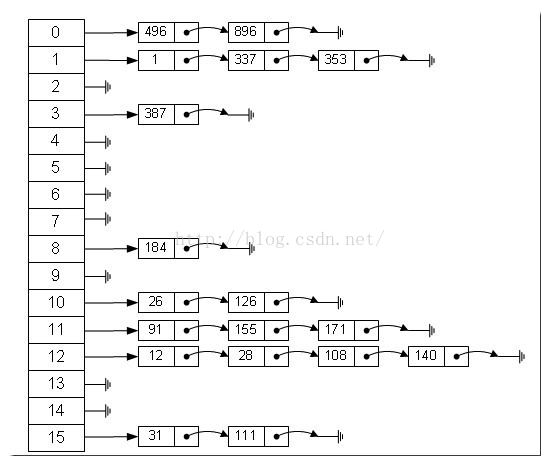
左边很明显是个数组,数组的每个成员包括一个指针,指向一个链表(桶)的头,当然这个链表可能为空,也可能元素很多。
1、利用key的hashCode重新hash计算出当前对象的元素在数组中的下标
2、存储时,如果出现hash值相同的key,此时有两种情况。(1)如果key相同(通过equals),则覆盖原始值;(2)如果key不同(出现冲突),则将当前的key-value放入链表中
3、获取时,直接找到hash值对应的下标,在进一步判断key是否相同(通过equals),从而找到对应值。
优点:不论哈希表中有多少数据,查找、插入、删除(有时包括删除)只需要接近常量的时间即0(1)的时间级。实际上,这只需要几条机器指令。
缺点:它是基于数组的,数组创建后难于扩展,某些哈希表被基本填满时,性能下降得非常严重,所以程序员必须要清楚表中将要存储多少数据(或者准备好定期地把数据转移到更大的哈希表中,这是个费时的过程)。
Hashtable
HashMap和Hashtable都实现了Map接口,主要的区别有:线程安全性,同步(synchronization),以及速度。HashMap几乎可以等价于Hashtable,除了HashMap是非synchronized的,并可以接受null(HashMap可以接受为null的键值(key)和值(value),而Hashtable则不行)。
HashMap是非synchronized,而Hashtable是synchronized,意味着Hashtable是线程安全的,多个线程可以共享一个Hashtable;而多个线程是不能共享HashMap的。Java 5提供了ConcurrentHashMap,它是HashTable的替代,比HashTable的扩展性更好。另一个区别是HashMap的迭代器(Iterator)是fail-fast迭代器,而Hashtable的enumerator迭代器。HashMap可以通过下面的语句进行同步:Map m = Collections.synchronizeMap(hashMap);
HashSet
HashSet是实现Set<E>接口的一个实体类,数据是以哈希表的形式存放的,里面的不能包含重复数据。Set接口是一种一个不包含重复元素的 collection。底层是依赖HashMap实现的
创建HashSet实例的源码:
/**
* Constructs a new, empty set; the backing <tt>HashMap</tt> instance has
* default initial capacity (16) and load factor (0.75).
*/
public HashSet() {
map = new HashMap<>();
}add()方法源码:
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}其实只用到了HashMap的Key,Value都是一样的。所以可以参考HashMap的特性。
ArrayList
1、ArrayList是基于动态数组的数据结构,查询快,增删慢,线程不安全。
2、在列表尾部插入数据很快。
add(E) 添加到末尾,复杂度O(1);
在内部数据中增加一项,偶尔可能会导致对数组重新进行分配;在列表中间插入或删除一个元素意味着这个列表中剩余的元素都会被移动。
add(index, E) 添加元素,在第几个元素后面插入,后面的元素需要向后移动,复杂度O(n);
3、删除数据同插入一样
4、获取数据块,直接读取第几个下标,复杂度O(1)
ArrayList详细解析请参考《ArrayList源码万字解析》
LinkList
原理总结:
1、数据存储基于双向链表的数据结构,查询慢,增删快。线程不安全。
2、插入数据很快。先是在双向链表中找到要插入节点的位置index,找到之后,再插入一个新节点。 双向链表查找index位置的节点时,有一个加速动作:若index < 双向链表长度的1/2,则从前向后查找; 否则,从后向前查找。
add(E) 添加到末尾,复杂度O(1);
add(index, E) 添加第几个元素后,需要先查找到第几个元素,直接指针指向操作,复杂度O(n);
3、删除数据很快。先是在双向链表中找到要插入节点的位置index,找到之后,进行如下操作:
//node节点全身而退
node.previous.next = node.next;
node.next.previous = node.previous;
node = null 查找节点过程和插入一样。
remove()删除元素,直接指针指向操作,复杂度O(1)。
4、获取数据很慢,需要从Head节点进行查找。
get() 获取第几个元素,依次遍历,复杂度O(n);
5、遍历数据很慢,每次获取数据都需要从头开始。














 207
207











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









