







多种聚类算法
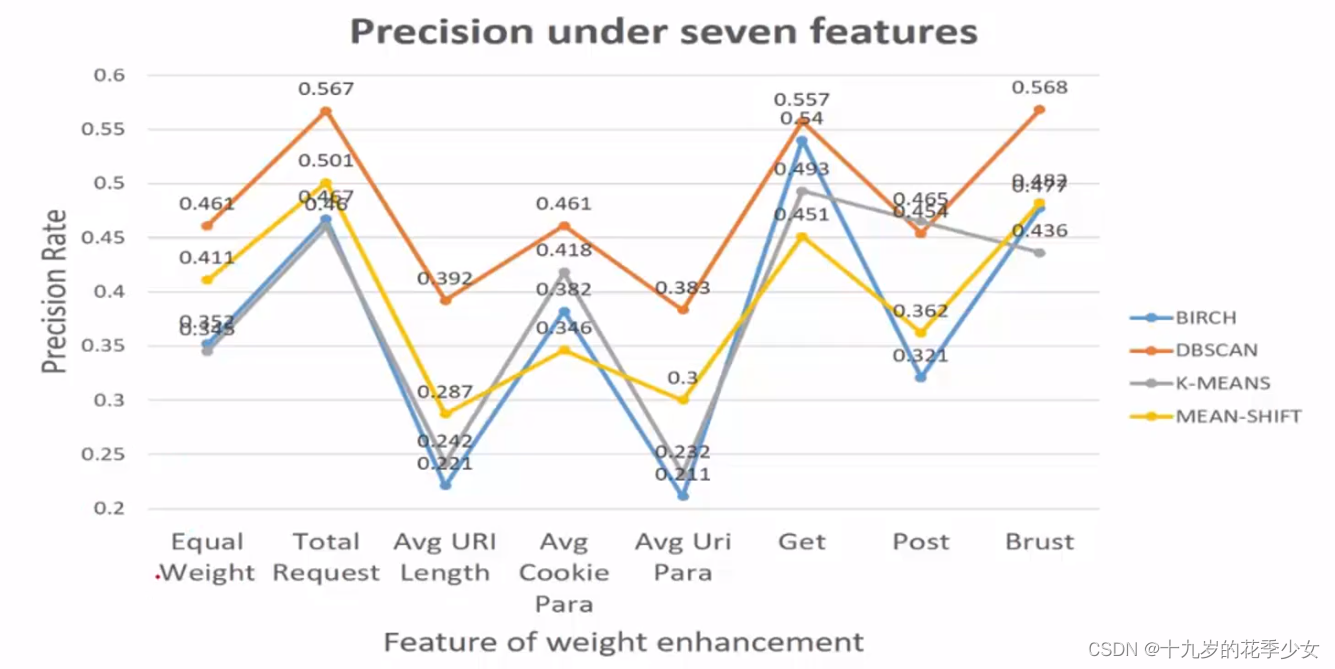
横坐标,第一个是相同的权重,后面给不同的特征加权重,对特征增强。
聚类算法使用sklearn实现
K-Means算法
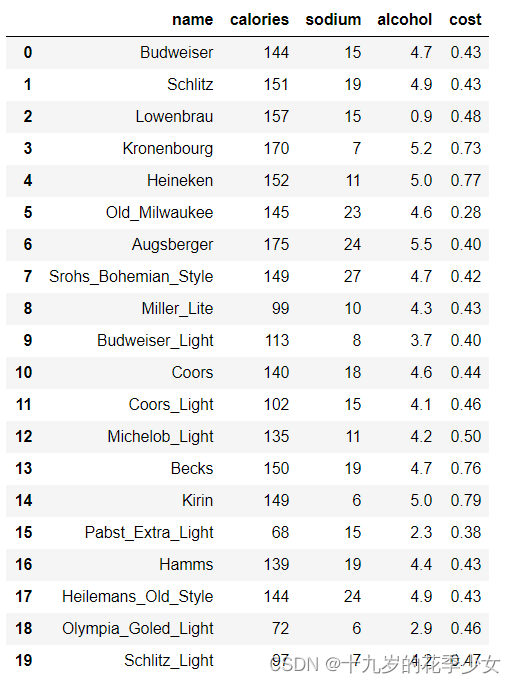
啤酒数据集
import pandas as pd
beer = pd.read_csv('data.txt', sep=' ')
beer
取出特征
X = beer[["calories","sodium","alcohol","cost"]]
实例化模型,设置两个不同的K值
from sklearn.cluster import KMeans
km = KMeans(n_clusters=3).fit(X)
km2 = KMeans(n_clusters=2).fit(X)
查看划分标签
km.labels_

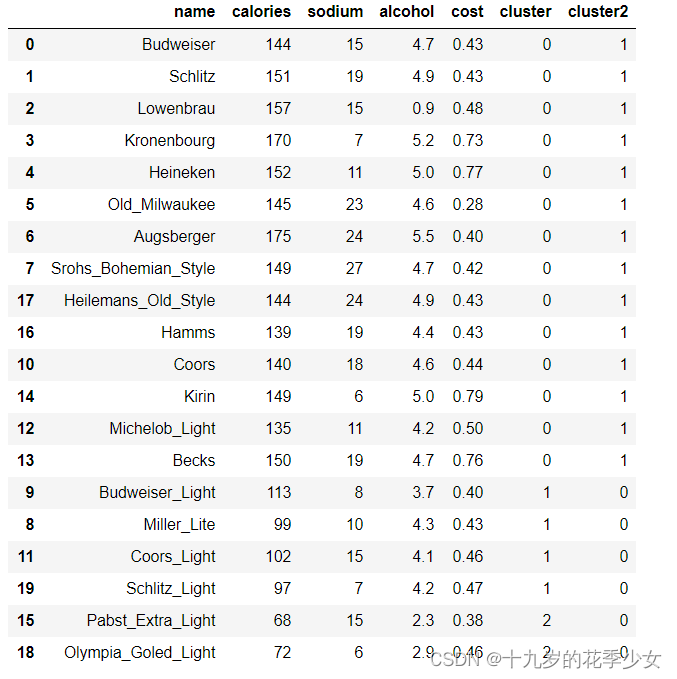
查看这两个不同K值模型的聚类结果
beer['cluster'] = km.labels_
beer['cluster2'] = km2.labels_
beer.sort_values('cluster')
from pandas.tools.plotting import scatter_matrix
%matplotlib inline
cluster_centers = km.cluster_centers_
cluster_centers_2 = km2.cluster_centers_
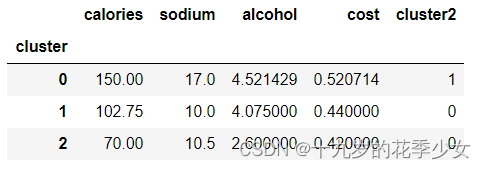
计算均值
beer.groupby("cluster").mean()
beer.groupby("cluster2").mean()
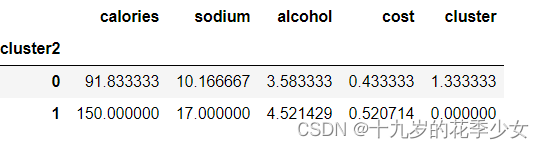
centers = beer.groupby("cluster").mean().reset_index()
%matplotlib inline
import matplotlib.pyplot as plt
plt.rcParams['font.size'] = 14
import numpy as np
colors = np.array(['red', 'green', 'blue', 'yellow'])
可视化分类结果
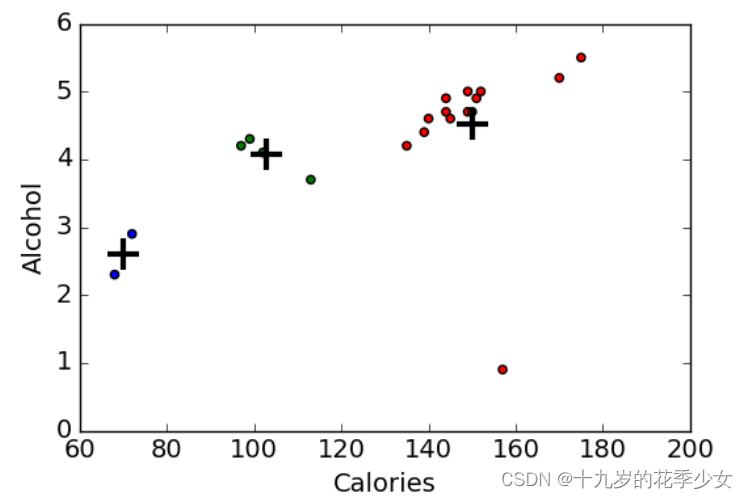
plt.scatter(beer["calories"], beer["alcohol"],c=colors[beer["cluster"]])
plt.scatter(centers.calories, centers.alcohol, linewidths=3, marker='+', s=300, c='black')
plt.xlabel("Calories")
plt.ylabel("Alcohol")
这是在alcohol和calories两个维度上的
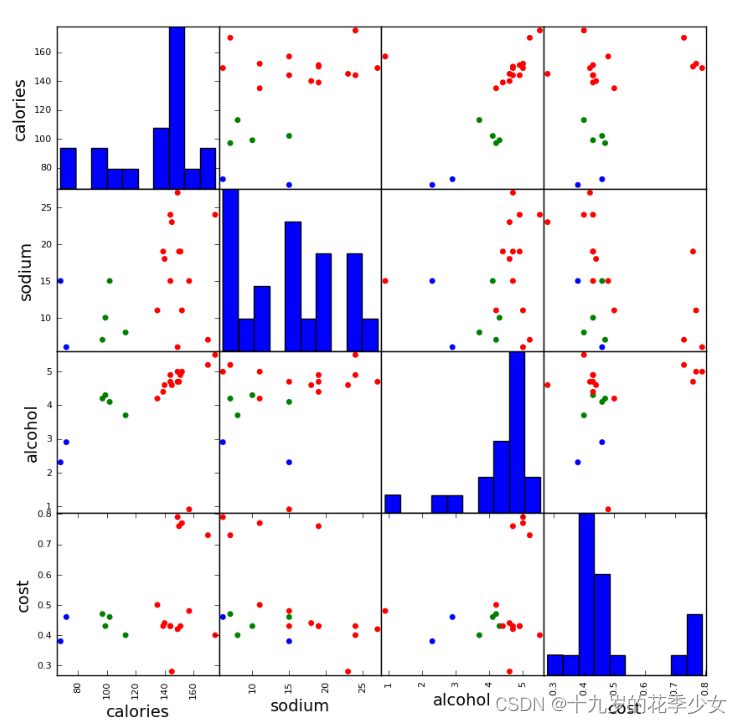
再画出其他维度的,两两一组。
scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=100, alpha=1, c=colors[beer["cluster"]], figsize=(10,10))
plt.suptitle("With 3 centroids initialized")
分成两个簇的结果
scatter_matrix(beer[["calories","sodium","alcohol","cost"]],s=100, alpha=1, c=colors[beer["cluster2"]], figsize=(10,10))
plt.suptitle("With 2 centroids initialized")

标准化数据
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
X_scaled
可以发现,消除了数据之间值得较大差异

再次使用K-means算法
km = KMeans(n_clusters=3).fit(X_scaled)
beer["scaled_cluster"] = km.labels_
beer.sort_values("scaled_cluster")
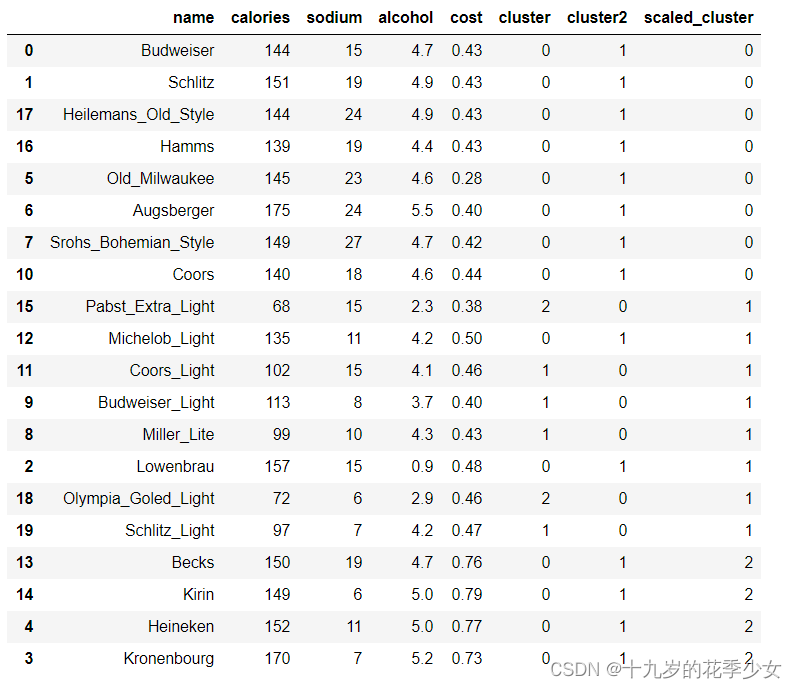
有时候不标准化会比标准化结果更好。
聚类评估:轮廓系数(Silhouette Coefficient )
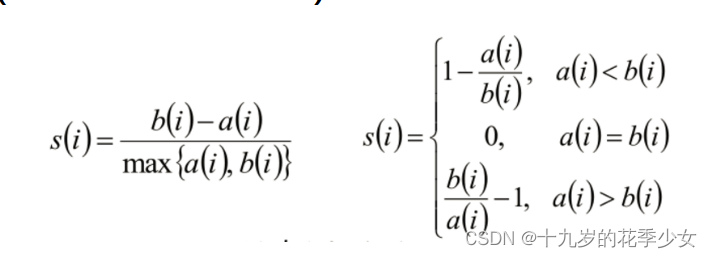
- 计算样本i到同族其他样本的平均距离ai。ai 越小,说明样本i越应该被聚类到该簇。将ai 称为样本i的簇内不相似度。
- 计算样本i到其他某簇Cj 的所有样本的平均距离bij,称为样本i与簇Cj 的不相似度。定义为样本i的簇间不相似度:bi =min{bi1, bi2, …,bik}
- si 接近1,则说明样本i聚类合理
- si接近1,则说明样本i更应该分类到另外的簇
- 若si 近似为0,则说明样本在两个簇的边界上。
代码实现
from sklearn import metrics
#传入数据和聚类完的结果
score_scaled = metrics.silhouette_score(X,beer.scaled_cluster)
#比较做归一化和不做归一化的结果
score = metrics.silhouette_score(X,beer.cluster)
print(score_scaled, score)
不做唯一话反而结果高了。
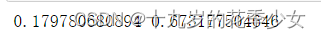
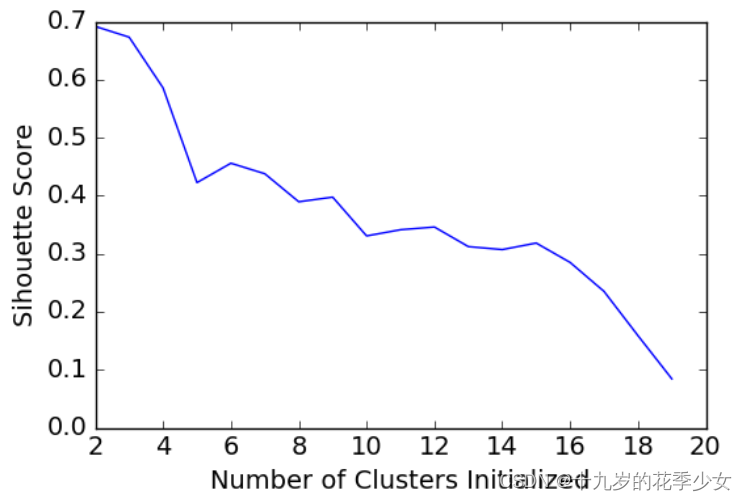
遍历K得选值 模型得分。选定分数高得K值。
scores = []
for k in range(2,20):
labels = KMeans(n_clusters=k).fit(X).labels_
score = metrics.silhouette_score(X, labels)
scores.append(score)
scores

画图直观查看
plt.plot(list(range(2,20)), scores)
plt.xlabel("Number of Clusters Initialized")
plt.ylabel("Sihouette Score")
可以看出K值为2的时候比较好。
DBSCAN
在比较不规整得数据集上效果比K-means较好。















 5018
5018











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









