






豆瓣电影 Top 250自学心得
1、按照截图所示‘以cURL格式复制’,然后使用插件网页获得爬虫的hearders,插件网页链接:https://tool.yuanrenxue.cn/curl
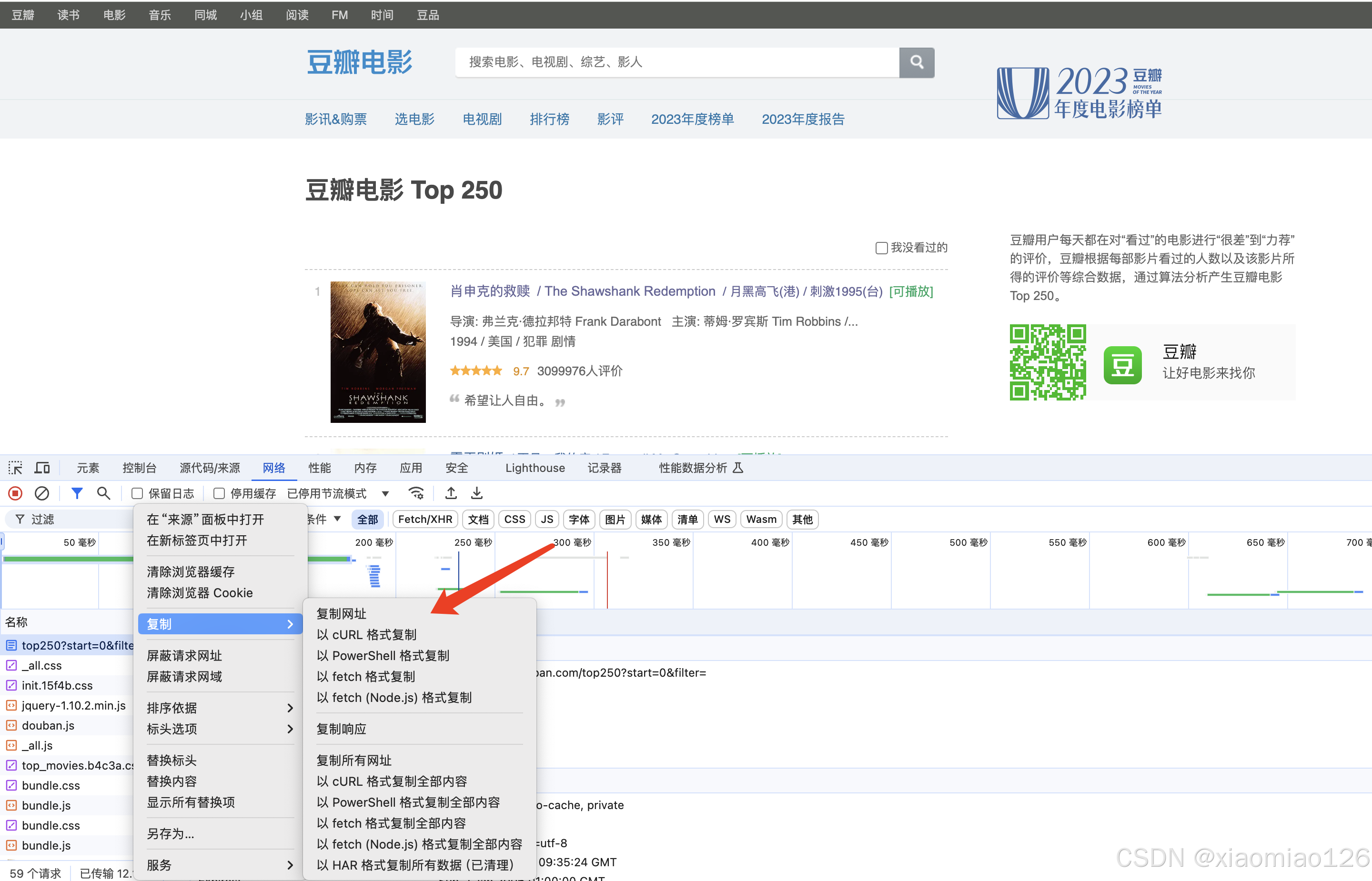
2、插件获取的hearders如下:
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'bid=dE7xWKtd5Vo; ll="118162"; _gid=GA1.2.1650176230.1734762005; Hm_lvt_19fc7b106453f97b6a84d64302f21a04=1734762142; HMACCOUNT=768D4019623228DE; Hm_lpvt_19fc7b106453f97b6a84d64302f21a04=1734762146; _ga_393BJ2KFRB=GS1.2.1734762145.1.0.1734762145.0.0.0; _ga_PRH9EWN86K=GS1.2.1734762142.1.1.1734762146.0.0.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1734762163%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DamGQvtxTUJiDXYphChQt4SjPVUqOAMFXUK17DsM7JfBmwox3M8agBWRlNpYAhtDC%26wd%3D%26eqid%3Dd5da3bdf002f0b770000000467665e08%22%5D; _pk_id.100001.4cf6=44eaa79d9034ed25.1734762163.; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.2067160932.1734762004.1734762163.1734762163.1; __utmc=30149280; __utmz=30149280.1734762163.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.2067160932.1734762004.1734762163.1734762163.1; __utmb=223695111.0.10.1734762163; __utmc=223695111; __utmz=223695111.1734762163.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __yadk_uid=wYgqMkanikBugtOwCwXqY0VpKJNRGCLw; _vwo_uuid_v2=DC1A799EA982B2CAED473DCBB8B0173F7|c900a2ce9854d74f6a8186e964de7f65; __utmt=1; _ga=GA1.1.2067160932.1734762004; _ga_Y4GN1R87RG=GS1.1.1734762004.1.1.1734762265.0.0.0; __utmb=30149280.2.10.1734762163',
'priority': 'u=0, i',
'sec-ch-ua': '"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
}
3、解析网页,先获取页面的html,然后对html进行分析,这里采用的是bs4去解析页面.
如下代码主要查询了电影排名,电影标题,电影详细链接,后续可以补充电影评分、作者等字段
def parser_url(url):
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_='item') # 查找包含电影所有信息的父元素div.item
for index, item in enumerate(items): # 使用enumerate可以同时获取索引和元素本身
movie_num = item.find('em').text # 在每个电影对应的div.item中找排名em元素并获取文本
movie_title = item.find('span', class_='title').text
movie_url = item.find('a')['href']
print('%s-%s-详情链接:%s' % (movie_num, movie_title, movie_url))
4、实现翻页功能,通过对豆瓣电影翻页后url的分析可以了解,url常规变化时
https://movie.douban.com/top250?start={}&filter=
start是从0开始的,总共电影250,则设置range(0,250,25),表示0-250范围,步长为25的翻页功能.
base_url = 'https://movie.douban.com/top250?start={}&filter='
for i in range(0, 250, 25): # 翻页10次,每次间隔25个电影
url = base_url.format(i)
parser_url(url)
代码:
# 爬虫练习
import requests
from bs4 import BeautifulSoup
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-language': 'zh-CN,zh;q=0.9',
'cache-control': 'max-age=0',
'cookie': 'bid=dE7xWKtd5Vo; ll="118162"; _gid=GA1.2.1650176230.1734762005; Hm_lvt_19fc7b106453f97b6a84d64302f21a04=1734762142; HMACCOUNT=768D4019623228DE; Hm_lpvt_19fc7b106453f97b6a84d64302f21a04=1734762146; _ga_393BJ2KFRB=GS1.2.1734762145.1.0.1734762145.0.0.0; _ga_PRH9EWN86K=GS1.2.1734762142.1.1.1734762146.0.0.0; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1734762163%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DamGQvtxTUJiDXYphChQt4SjPVUqOAMFXUK17DsM7JfBmwox3M8agBWRlNpYAhtDC%26wd%3D%26eqid%3Dd5da3bdf002f0b770000000467665e08%22%5D; _pk_id.100001.4cf6=44eaa79d9034ed25.1734762163.; _pk_ses.100001.4cf6=1; ap_v=0,6.0; __utma=30149280.2067160932.1734762004.1734762163.1734762163.1; __utmc=30149280; __utmz=30149280.1734762163.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utma=223695111.2067160932.1734762004.1734762163.1734762163.1; __utmb=223695111.0.10.1734762163; __utmc=223695111; __utmz=223695111.1734762163.1.1.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __yadk_uid=wYgqMkanikBugtOwCwXqY0VpKJNRGCLw; _vwo_uuid_v2=DC1A799EA982B2CAED473DCBB8B0173F7|c900a2ce9854d74f6a8186e964de7f65; __utmt=1; _ga=GA1.1.2067160932.1734762004; _ga_Y4GN1R87RG=GS1.1.1734762004.1.1.1734762265.0.0.0; __utmb=30149280.2.10.1734762163',
'priority': 'u=0, i',
'sec-ch-ua': '"Google Chrome";v="131", "Chromium";v="131", "Not_A Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"macOS"',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'none',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
}
def parser_url(url):
response = requests.get(url, headers=headers)
html = response.text
soup = BeautifulSoup(html, 'html.parser')
items = soup.find_all('div', class_='item') # 这里改为查找包含电影所有信息的父元素div.item
for index, item in enumerate(items): # 使用enumerate可以同时获取索引和元素本身
movie_num = item.find('em').text # 在每个电影对应的div.item中找排名em元素并获取文本
movie_title = item.find('span', class_='title').text
movie_url = item.find('a')['href']
print('%s-%s-详情链接:%s' % (movie_num, movie_title, movie_url))
base_url = 'https://movie.douban.com/top250?start={}&filter='
for i in range(0, 250, 25): # 翻页10次,每次间隔25个电影
url = base_url.format(i)
parser_url(url)```


















 3477
3477

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











