







目录
特征缩放
- 数据归一化:把数据的取值范围处理为0-1或者-1 - 1之间。 任意一组数据转化为0-1之间:
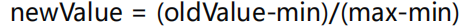 任意一组数据转化为-1 - 1之间:
任意一组数据转化为-1 - 1之间: 
- 均值标准化:
 x为特征数据,u为数据的平均值,s为数据的方差
x为特征数据,u为数据的平均值,s为数据的方差
交叉验证
将数据分成k份,然后取其中一份作为测试集,其余k-1份为训练集,然后求得误差的平均值作为最终评价。
拟合
欠拟合:在训练集和测试集上的性能都较差
拟合:在训练集和测试集上的性能都比较好
过拟合:能较好地学习训练集数据的性质,而在测试集上的性能较差
如下图所示,可以直观的展现出欠拟合,拟合,过拟合的性质:

如何防止过拟合
- 减少特征
- 增加数据量
- 正则化
正则化
正则化是机器学习中对原始损失函数引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。 也就是目标函数变成了 原始损失函数+额外项
正则化代价函数:
- L1正则化:

- L2正则化:

















 599
599











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









