









Caffe是一个清晰而高效的深度学习框架,特别是在处理图像方面有着强悍的能力,也方便上手,最近学习了Caffe,用一些图集做了分类练习。
详细的入门学习强烈推荐这个系列:http://www.cnblogs.com/denny402/tag/caffe/default.html?page=2 这个作者把基础的东西很详细的都介绍了一遍,在这里我只做一些简要的总结:
训练一个基于CNN的图形分类器的基本流程是准备数据->转换数据->计算均值(非必须)->训练->测试,注意:所有基于Caffe的操作要在./Caffe目录下操作,我在代码或命令中使用的“储存目录”都是指的你选定的同一个目录,且位置为./caffe/储存目录
1.准备数据
准备数据首先你需要有一个图片集和一个文件,文件中记录着图片集中每个图片对应着哪个标签,比如我有一个字母图片的集合,他们的标签对应着ABCD等等,根据这些图片集,我们需要写一个文件train.txt和一个test.txt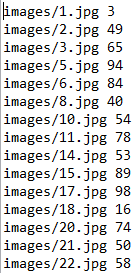
2.转换数据
caffe能够处理的数据形式是leveldb或者lmdb,所以我们要把图集转换成这两种形式之一,用下面的create_lmdb.sh将图集转换为lmdb
#!/usr/bin/env sh
MY=储存目录
echo "Create train lmdb.."
rm -rf $MY/img_train_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_height=256 \
--resize_width=256 \
/home/xxx/caffe/储存目录 \
$MY/train.txt \
$MY/img_train_lmdb
echo "Create test lmdb.."
rm -rf $MY/img_test_lmdb
build/tools/convert_imageset \
--shuffle \
--resize_width=256 \
--resize_height=256 \
/home/xxx/caffe/储存目录 \
$MY/test.txt \
$MY/img_test_lmdb
echo "All Done.."
其中我标注xxx的目录和MY变量都是根据你的linux改变的,然后执行命令
sh create_lmdb.sh目录下就会产生img_test_lmdb和img_train_lmdb
3.计算均值
这一步不是必要的,但是有这一步结果可能会更好的收敛,直接执行
sudo build/tools/compute_image_mean 储存目录/img_train_lmdb 储存目录/mean.binaryproto4.训练
(1)完成以上步骤后还需要一个solver.prototxt和一个train_val.prototxt才能训练,它们的具体参数的含义可以见我开始推荐的系列博客,下载可以从http://download.csdn.net/detail/xiaonannanxn/9621078这里下载,只要修改几个目录的值即可,都放到“储存目录”下。然后执行
./build/tools/caffe train --solver 储存目录/solver.prototxt (2)在图像识别方面,每层网络抽象出的特征有一些相似之处,比如人脸识别可能都一层或一层的某一部分抽象出眼睛,所以,我们可以利用一些实验项目已经训练好的model来训练你的模型,命令如下
./build/tools/caffe train --solver 储存目录/solver.prototxt --weights 储存目录/bvlc_reference_caffenet.caffemodel最后一个参数就是你使用的别人已经训练好的model
(3)训练的一个副产物是*.solverstate,可以用它继续未完成的训练,执行如下命令
./build/tools/caffe train --solver 储存目录/solver.prototxt --snapshot 储存目录/1_iter_1000.solverstate最后一个参数是你的*.solverstate
4.测试
(1)其实在我给的train_val.prototxt中已经设置了每迭代几次就测试,如果结束了想重新测试,执行命令
./build/tools/caffe test --weights 储存目录/1_iter_500.caffemodel --model 储存目录/train_val.prototxt第二个参数最后一个参数是你的*.caffemodel(训练结束的产物)
(2)如果你想单独测试某一个图片,执行命令
sudo ./build/examples/cpp_classification/classification.bin \
储存目录/deploy.prototxt \
储存目录/1_iter_220.caffemodel \
储存目录/mean.binaryproto \
储存目录/labels.txt \
储存目录/test.jpg其种从第二行到第六行分别对应的是deploy文件(类似train_val.prototxt文件,在我提供的下载链接中有实例)、caffemodel、均值、标签文件、需要测试的图片,其中标签文件的格式为开始设定的0123对应ABCD反过来,即每一行一个标签,为ABCD
(3)有的时候还需要用python或者matlab来循环的测试图片,caffe是提供的python接口的,配置很容易在网上找到,我在这只列出一个用来测试图片的python程序供大家参考,在用python调用caffe时需要将mean.binaryproto也就是均值文件转换为*.npy格式,以下是示例:
import caffe
import numpy as np
MEAN_PROTO_PATH = 'mean.binaryproto'
MEAN_NPY_PATH = 'mean.npy'
blob = caffe.proto.caffe_pb2.BlobProto()
data = open(MEAN_PROTO_PATH, 'rb' ).read()
blob.ParseFromString(data)
array = np.array(caffe.io.blobproto_to_array(blob))
mean_npy = array[0]
np.save(MEAN_NPY_PATH ,mean_npy) 然后是调用的主程序
# coding:utf-8
import numpy as np
import os
caffe_root = '/home/xxx/caffe/'
import sys
sys.path.insert(0,caffe_root+'python')
import caffe
MODEL_FILE = caffe_root+'储存目录/deploy.prototxt'
PRETRAINED = caffe_root+'储存目录/1_iter_220.caffemodel'
#cpu模式
caffe.set_mode_cpu()
#定义使用的神经网络模型
net = caffe.Classifier(MODEL_FILE, PRETRAINED,
mean=np.load(caffe_root + '储存目录/mean.npy').mean(1).mean(1),
channel_swap=(2,1,0),
raw_scale=255,
image_dims=(256, 256))
imagenet_labels_filename = caffe_root + '储存目录/labels.txt'
labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t')
#对目标路径中的图像,遍历并分类
row = 1
for root,dirs,files in os.walk(caffe_root + "储存目录/图片目录"):
for file in files:
#加载要分类的图片
IMAGE_FILE = os.path.join(root,file).decode('gbk').encode('utf-8');
input_image = caffe.io.load_image(IMAGE_FILE)
#预测图片类别
prediction = net.predict([input_image])
#预测各标签的概率
print prediction[0]
# 输出概率最大的前5个预测结果
top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
print labels[top_k]大概的流程就介绍到这里,有兴趣的同学请看我推荐的博客以及caffe官方指导文档http://caffe.berkeleyvision.org/ 里面有Documents















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









